
Benchmarks often get criticized for their inability to perfectly model the real-world situations that we’d like them to. So take what follows in the limited scope that it’s intended, and don’t read too much into it. [Joonas Pihlajamaa]’s experiments with toggling a hardware pin as fast as possible on different single-board computers can still show us something.
The take-home result won’t surprise anyone who’s worked with a single-board computer: the higher-level interfaces are simply slow compared to direct memory-mapped GPIO access. But really slow. We’re talking around 5 kHz from Python or any of the file-based interfaces to the pins versus 3 MHz for direct access. Worse, as you’d expect when a non-realtime operating system is in the middle, there are glitches on the order of ten milliseconds with all the file-based methods.
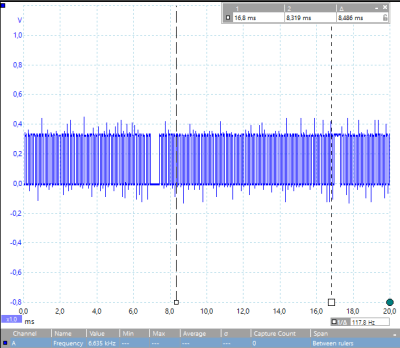
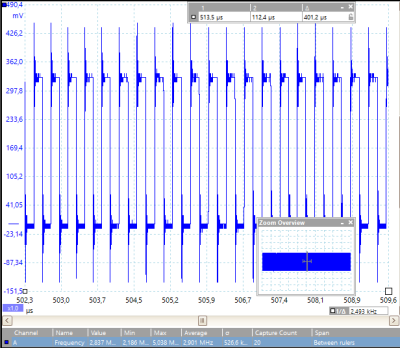
This test only tells us so much, though, and it’s not really taking advantage of the BeagleBone Black’s ace in the hole, the PRUs — onboard hardware processors that bring real-time IO capabilities to the system. We’d like to see a re-write of the code to take advantage of libpruio, for instance. A 20 MHz square wave is a piece of cake with the PRUs.
Of course, it’s not interacting, which is probably in the spirit of the benchmark as written. But if raw hardware speed on a BeagleBone is the goal, it’s likely that the PRUs are going to feature prominently in the solution.














Especially on the BBB, the omission of the PRU variant makes absolutely no sense, since nobody would use another approach when fast I/O is needed on it…
And everybody else not owning a BBB would use an Arduino.
Author of the benchmark here, I’d be happy to update the post to add a PRU variant, maybe someone could add a comment at CodeAndLife.com post with instructions, or email me (contact details at my site). I was not aware of the PRU functionality, and I think few new BBB users are. Even the linked Hack-a-day article says “Unfortunately, PRU’s are not supported and in the absence of information, difficult to program.”
I goole for “bb pru programming info” and first entry is: https://www.element14.com/community/community/designcenter/single-board-computers/next-gen_beaglebone/blog/2013/05/22/bbb–working-with-the-pru-icssprussv2
It is a very detailed document. Was it that hard to find?
Thanks for the link! You’re right it’s easy to find once you know that the device has “PRU”, but starting from scratch with BeagleBone I did not encounter it for some reason when preparing for the article. Now that I know about it, it seems that also googling for “fast gpio beaglebone” would also hint at this PRU.
>A 20 MHz square wave is a piece of cake with the PRUs.
20 MHz square wave is a piece of cake with Pee ZERO, Pee 2 is up to >20MHz, Pee 3 >40MHz
https://github.com/hzeller/rpi-gpio-dma-demo
up, pee2 >40, pee3 >60
The main difference, however, is that a PRU is a co-processor. You can write an application for PRU that can interact with main memory and never involve the CA core.
just don’t use the Pee’s ICU
Also I would like to point out that there 2xPRU’s (200Mhz) with there own interrupts + DMA. This means you can have two indipendant fast real time things, that use any of the shared peripherals, providing the main processor with ready processed data, or performing real time operations on the provided data, all In one chip. – I like the AM3359!
all true and good points, except pee 2 and 3 are quad core, and you can partition whole >1GHz core solely for your user program (no kernel scheduling, no interrupts, no context switches).
1 GHz bit banging? Anything close to Realtime? See how fast your reaction time decreases…
The C++ file-based access functions by Derek Molloy are far from being optimal.
For each pin change they open the file in /sys/class/gpio/…, writes to that file, and closes it again.
Just keep that file open and do pwrite(,,, 0) to speed it up.
Didn’t we (the internet) know this like a month or two after every $SEMI_POPULAR_MCU came out? (which was what, 5 years ago for the BeagleBones?)
Anyone bitbanging from userspace deserves what they get. If you have a desire for a fast signal, use SPI or QSPI. If you have a desire for a PWM, use the damn PWM hardware, etc.
Still, knowing roughly how fast you can expect a GPIO level to change on a given language and access library doesn’t hurt, and you’ll get a rough comparison of speed of different approaches. But I agree that one cannot do anything time-critical from userspace, so the results are of limited use. A PWM benchmark would be quite boring, as it’s only determined by clock and cycle settings. :)
Typical ‘high-level’ programmer reply.
It doesn’t matter if you get another processor (PRU) or hardware module to output a faster signal, it’s about latency.
A 20MHz PWM output that can only change duty cycle every few milliseconds is much less useful than a 5MHz PWM signal that can change duty cycle every microsecond.
Toggling pins fast is the new “Hello world” and the ST32F4 is awesome at it, a change of state takes 2 clock cycles with 100MHz output enabled. I can’t tell you how disappointed I’ve been in the past with ARM9 chips connected by the B peripheral bus. It’s just thumb code that’s yucky to program in. It’s taken a long time for MCUs to be able to toggle output pins faster than my old ‘3MHz’ LPT port.
MHz is a really confusing unit to use for toggling as 90 million changes a second allows a 45MHz square wave.
For those interested in torture testing the BBB PRUs in a pseudo real-world application the following Github project of mine might be of use as a starting point:
https://github.com/ttreker/PRUSS-EndToEnd-PWM
The project is describe in detail in the readme. In a nutshell its purpose is to provide a framework for an end-to-end test applying the PRUSS (both PRUs working in concert with each other) to collect an external PWM source’s duty cycle for each cycle, dump the collected data to a buffer in realtime, and when complete transfer that data to an external client across the network. This last step is, of course, unneeded in a pure test of PRUSS speed in the context of the BBB OS, but was included to provide a basic framework for a potential real-world application. Whether it is suited for this purpose is for others to decide.
The project readme as a section on benchmarks that might be of interest to readers of this Hackaday post.
One feature of this project is that the PRUs are setup to work together; one gathers the counts while the other dumps the gathered data the system data buffer. It makes use of inter-PRU communication via a PRUSS “interrupt” (which really isn’t an interrupt in the context of the PRUSS alone).
I hope this is helpful.
Author of libpruio here. Typical benchmarks for pin toggling in Hz, 50 iteration, controlled by software running on ARM CPU, measured by onboard eCAP subsystem:
Open loop, direct GPIO:
Minimum: 140252.453125
Avarage: 233242.59875
Maximum: 306748.46875
Open loop, function Gpio->Value:
Minimum: 127226.4609375
Avarage: 176452.04203125
Maximum: 187617.265625
Closed loop, direct GPIO to direct GPIO:
Minimum: 69589.421875
Avarage: 70626.28109375
Maximum: 72150.0703125
Closed loop, function Gpio->Value to direct GPIO:
Minimum: 13061.6513671875
Avarage: 70048.3459765625
Maximum: 81168.828125
Closed loop, function Gpio->Value to function Gpio->setValue:
Minimum: 62814.0703125
Avarage: 71022.87359375
Maximum: 81168.828125
Closed loop, Adc->Value to direct GPIO:
Minimum: 92850.5078125
Avarage: 93054.59218750001
Maximum: 93283.5859375
Closed loop, Adc->Value to function Gpio->Value:
Minimum: 69589.421875
Avarage: 86433.71312499999
Maximum: 93196.6484375
Note the big difference between minimum and maximum!
And note: no optimization, just the vanilla library with all subsystems active. You can speed up the results by disabling unused subsystems, like PWM, ADC, GPIO.