
For humans, moving our arms and hands onto an object to pick it up is pretty easy; but for manipulators, it’s a different story. Once we’ve found the object we want our robot to pick up, we still need to plan a path from our robot hand to the object all the while lugging the remaining limbs along for the ride without snagging them on any incoming obstacles. The space of all possible joint configurations is called the “joint configuration space.” Planning a collision-free path through them is called path planning, and it’s a tricky one to solve quickly in the world of robotics.
These days, roboticists have nailed out a few algorithms, but executing them takes 100s of milliseconds to compute. The result? Robots spend most of their time “thinking” about moving, rather than executing the actual move.
Robots have been lurching along pretty slowly for a while until recently when researchers at Duke University [PDF] pushed much of the computation to hardware on an FPGA. The result? Path planning in hardware with a 6-degree-of-freedom arm takes under a millisecond to compute!
It’s worth asking: why is this problem so hard? How did hardware make it faster? There’s a few layers here, but it’s worth investigating the big ones. Planning a path from point A to point B usually happens probabilistically (randomly iterating to the finishing point), and if there exists a path, the algorithm will find it. The issue, however, arises when we need to lug our remaining limbs through the space to reach that object. This feature is called the swept volume, and it’s the entire shape that our ‘bot limbs envelope while getting from A to B. This is not just a collision-free path for the hand, but for the entire set of joints.
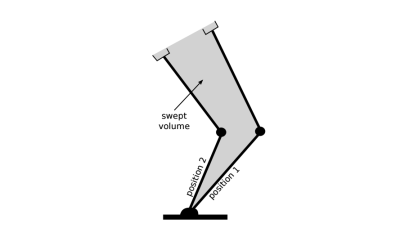
Encoding a map on a computer is done by discretizing the space into a sufficient resolution of 3D voxels. If a voxel is occupied by an obstacle, it gets one state. If it’s not occupied, it gets another. To compute whether or not a path is OK, a set of voxels that represent the swept volume needs to be compared against the voxels that represent the environment. Here’s where the FPGA kicks in with the speed bump. With the hardware implementation, voxel occupation is encoded in bits, and the entire volume calculation is done in parallel. Nifty to have custom hardware for this, right?
We applaud the folks at Duke University for getting this up-and-running, and we can’t wait to see custom “robot path-planning chips” hit the market some day. For now, though, if you’d like to sink your teeth into seeing how FPGAs can parallelize conventional algorithms, check out our linear-time sorting feature from a few months back.














In the movies, they always say “Don’t hit the red button!”
Think they nicknamed the robot ‘Neo’? …. “Do I take the red block or the blue block?”
Strange and probably unwise they would be using a button that is commonly used for emergency stop (e-stop) to allow the robot to move when it should be the other way around. Besides that, looks pretty cool, now when can I use this for wheeled mobile robots ?
Some of those gains could be from the persons implementing the solution. Moving towards a parallel HDL implementation would also requires much better programmers with more skills and requires more focus and understanding of the problem they are trying to solve. Instead of the usual ones that piles frame works and abstractions on the language of the month club, you get much higher quality of programmers. Quality vs quantity.
You might be underestimating the CS and engineering that goes into making robots work as well as they do. Please don’t insult people.
However, of course, optimizing a problem for speedy, functional/parallel solution might be part of why it’s faster. Still, this says nothing about whether previous implementations were especially bad.
You might have something if tekkienet was wrong, but he’s definitely right… hardware engineers > software engineers generally in my experience, notably so…
Ugh, I’ve never had a literal headache with CS until I was converting optimizing parallel algorithms for SIMD architectures. My effort was appreciated until they had to find someone else to do it. HA.
I can draw houses all day but that doesn’t make me an structural engineer.
One of the researchers here. The important thing to understand about our HW solution is that we have an order speedup in compute time, as every collision detection for the edges in the roadmap happens in parallel. It runs in O(N) time instead of O(E*N) time where N is the number of voxels in the 3D space and E is the number of edges in the roadmap.
May I ask if you are using the standard ip blocks for this or did you need a custom implementation for 3D space? Doing some multi-spectral LIDAR imaging for one of my projects that needs parallelism is running into volume and power issues, FPGA looks like a good solution if standard blocks can be used.
All our Verilog is custom.
Thanks for your response, good luck.
I have a potentially-stupid question:
I do most of my work in game development, but I noticed that you encode the space as voxels. Wouldn’t the obvious first-order optimization be to fit a collision mesh to the obstacles? That way, instead of using voxel collision, you could use the standard polygon-polygon collision, which is essentially instantaneous on a modern machine.
Read the paper. We don’t actually do “collision detection” online; we just check to see if a given point is in a logically minimized set of points (for each graph edge). This way collision detection can be performed by very simple and fast circuits.
Now they need a faster robot arm — what good is millisecond planning when it takes 10 seconds to execute the action!
Gotta combine with https://www.youtube.com/watch?v=EqMPLnIRUvQ or https://www.youtube.com/watch?v=-KxjVlaLBmk
Why not both?
Also u notice how the system usually decides to swing the arm up and over – there doesn’t seem to be any path optimisation going on, otherwise it will keep the hand low. Perhaps they can –
-work out one path then begin the arm movement
-immediately calculate hundreds of different paths with randomised variations, comparing with straight line. Should still take <1 second.
-choose shortest path amongst the set then make the arm do that motion.
Well it dose plan the path in milliseconds so I suppose a faster arm would be easy, and then we get this…
https://www.youtube.com/watch?v=qgNsTOc_MIo
And as you might have realized we’re planning much faster than we can perceive the environment – I haven’t ever seen a 1 kHz depth camera. However, millisecond planning is very compelling even without super-fast actuators and perception. Task planning requires multiple plans to be generated for the same environment, and we see motion planning as a primitive operation that is important enough to deserve hardware support.
This tech might be interesting. Without a frame of reference compared to a non-fpga arm could do, or, knowledge of what the computer is doing before the red button is pressed, it is quite difficult for me, john q public, to be able to actually accept that they have done something impressive.
Kyle,
?
I’d suggest a robotics course https://www.youtube.com/view_play_list?p=65CC0384A1798ADF
? I’d suggest a robotics course https://www.youtube.com/view_play_list?p=65CC0384A1798ADF
Just thought I would remark that the article was really well written .. very cleanly “scoped” to be reasonably complete in the allotted space, clear writing style etc.
Great job.
I wonder about the speed of a GPU based implementation, it would at least be more future proof than a hardware implementation.
A GPU is hardware!
im cunfusd now :P
Yeah but I’d wager a CUDA application is way easier to update and implement than an FPGA program.
This problem seems to be about right for a GPU as it’s all about similar instructions on huge datasets.
But then I’m no expert!
Seems a pretty clean env. White table, boxes with black stripes, coloured cubes. With 4 kinect2’s that’s a lot of hw to map a clean space. Be interesting to see how it fares with a more noisy space. The work though as shown is great, I realize the complexity of the overall problem.
IMPRESSIVE!
Add in a depth camera (rather than the 4 2-d cameras) and you could do this with moving obstacles, yes?
A better question is why did no one try this earlier? Thousands of equations to optimize a path seems like an obvious problem for parallel computing.
I think there is a use for ‘one of my habits’ here.
Writing code can be boring and repetitive. After a diversion (8 years or so) of doing internet coding (php/mysql/html/css/javascript) I developed a different coding habit. In web code – a lot of the time you essentially write code in php that then writes the code in html that drives the browser.
I still use JavaScript quite often for two things.
1) I get it to write code for other languages to save me time. This is really great for complex data objects as well.
2) I use it to examine complex data and give graphical or visual representations as it is built right into a rendering engine (html) in the browser.
So to get to my point – I will explain with an example.
1) Take an old 22V10 CPLD or something like that as it is very well documented and has simple macro-cells.
2) Implement it in HDL using registers for the programming bits.
3) Now you have a *blank* CPLD in HDL that can be dynamically programmed.
Or in other words – you are not limited to creating static HDL. You can create a platform that creates dynamic HDL through the use of registers or RAM being the programming bits that are normally fixed in HDL. Now you can focus on rules and constraints and let the platform do the rest.
Ironically, the best way to achieve this platform (in my opinion) would be to use another language to write the dynamic HDL platform. Just express the result with registers and Boolean expressions.
register function: 0 = AND, 1 = OR
output <= (function AND (A OR B)) OR ((NOT function) AND (A AND B));
Here the dynamic register 'function' determines if 'output' is the result of (A AND B) or alternatively the result of (A OR B) and that can be determined by some other means at run time rather being fixed in code at compile time (synthesis time for HDL).
interesting, is there any tutorial on such programming technics?
Out of curiosity, I did a bit of google fu and that is not a lot out there. There are not even examples for HDL.
Here is what I did find out.
Keywords are: ‘code generation’, ‘automatic programming’.
There is a wiki here – https://en.wikipedia.org/wiki/Automatic_programming
A tutorial that is not specific to any language here – http://www.sciencedirect.com/science/article/pii/S0747717185800109
The key is simply that you write an abstraction for a higher level language. This is a very common thing to do in two areas. One is situations like a web servers that are coded in one language (php) and spits out code in another language (html etc).
The other common situation where you have a succinct lower level language (with sparse primitives) and you are more or less forced to write a higher level abstraction. An example would be LUA.
The only thing that is different about my suggestion is that the code is dynamic at run time.
I realize the position of the targets are updated in real-time, but if the obstacles or the robot base is moved how does the system update if occupancy is encoded like this? Would this method work with mobile manipulators or is it more for stationary arms with fixed environments?
The occupancy grid can be updated with a SLAM algorithm for mobile robots. We’re just focused on motion planning here so our rig is set up to capture the environment from every angle. It will be up to perception researchers to come up with representations of objects to enable the system to reason about whether voxels not visible to the camera are occupied. This uncertainty is something all motion planning methods have to deal with- not just ours.
One of the interesting things about our approach is that the collision detection is so fast that a probabilistic occupancy grid could be used instead of a boolean occupied/unoccupied grid. You could imagine assigning a probability to each voxel representing how certain you are something is there, then randomly sampling over the entire grid and performing collision detections many times over this distribution. The results of the successive collision detections could then be used to update edge weights for the shortest path solver.
So if obstacles or the robot base move the edge weights in the shortest path solver need to be recalculated. Is that time consuming?
Do the high speed delta robot demos that organise a moving conveyor belt of food do this kind of planning?
Eg https://www.youtube.com/watch?v=aPTd8XDZOEk