
As a fun project I thought I’d put Google’s Inception-v3 neural network on a Raspberry Pi to see how well it does at recognizing objects first hand. It turned out to be not only fun to implement, but also the way I’d implemented it ended up making for loads of fun for everyone I showed it to, mostly folks at hackerspaces and such gatherings. And yes, some of it bordering on pornographic — cheeky hackers.
An added bonus many pointed out is that, once installed, no internet access is required. This is state-of-the-art, standalone object recognition with no big brother knowing what you’ve been up to, unlike with that nosey Alexa.
But will it lead to widespread useful AI? If a neural network can recognize every object around it, will that lead to human-like skills? Read on.
How To Do Object Recognition

The implementation consists of:
- Raspberry Pi 3 Model B
- amplifier and speaker
- PiCamera
- momentary swtich
- cellphone charger battery for the Pi
The heart of the necessary software is Google’s Inception neural network which is implemented using their TensorFlow framework. You can download it by following the TensorFlow tutorial for image recognition. The tutorial doesn’t involve any programing so don’t worry if you don’t know Python or TensorFlow. That is, unless you’re going to modify their sample code as I did.
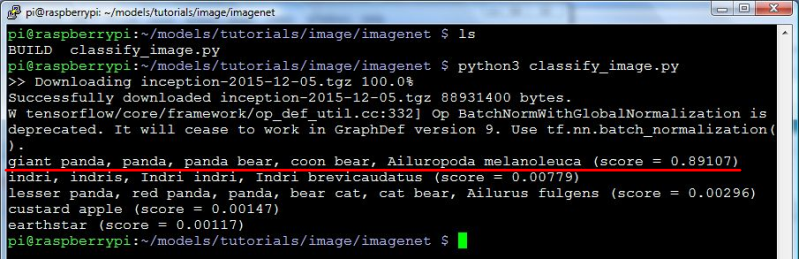
The sample code takes a fixed named file containing a picture of a panda and does object recognition on it. It gives the result by printing out that it saw a panda. But that wasn’t enough fun.
I hunted around for some text-to-speech software and found Festival. Now when it wants to say it saw a panda, I modified the sample code to run Festival in a linux shell and tell it to actually say “I saw a panda” to the speaker.
But that still wasn’t fun enough. I connected a PiCamera to the Raspberry Pi, and had that take a photo and give it to the TensorFlow code to do object recognition. In the vernacular, it now ran inference on my photo.
And lastly, to make it all real easy I connected a momemtary switch to one of the Pi’s GPIO pins and took the photo when the momentary switch was pressed.
Here’s the Python program’s main() function before…
def main(_):
maybe_download_and_extract()
image = (FLAGS.image_file if FLAGS.image_file else
os.path.join(FLAGS.model_dir, 'cropped_panda.jpg'))
run_inference_on_image(image)
… and after.
def main(_):
os.system("echo %s | festival --tts" % "Wait while I prepare my brain...")
maybe_download_and_extract()
# Creates graph from saved GraphDef.
create_graph()
# preparing for the switch
GPIO.setmode(GPIO.BCM)
GPIO.setup(17, GPIO.IN)
camera = PiCamera()
os.system("echo %s | festival --tts" % "I am ready to see things.")
while True:
# loop for the switch
while (GPIO.input(17) == GPIO.LOW):
time.sleep(0.01)
# take and write a snapshot to a file
image = os.path.join(FLAGS.model_dir, 'seeing_eye_image.jpg')
camera.capture(image)
os.system("echo %s | festival --tts" % "I am thinking about what you showed me...")
human_string = run_inference_on_image(image)
os.system("echo I saw a %s | festival --tts" % human_string)
The calls to os.system() are where I run the Festival text-to-speech program to make it say something to the speaker.
maybe_download_and_extract() is where Google’s Inception neural network would be downloaded from the Internet, if it’s not already present. By default, it downloads it to /tmp/imagenet which is on a RAM disk. The first time it did this, I copied it from /tmp/imagenet to /home/inception on the SD card and now run the program using a command line that includes where to find the Inception network.

The call to create_graph() was moved from inside the run_inference_on_image() function. create_graph() sets up the neural network, which you need do only once. Previously the program was a one-shot deal, but now it has an infinite while loop which calls run_inference_on_image() each time through the loop. Obviously, setting up the neural network is something you do only once (see our introduction to TensorFlow for more about graphs) so it had to be moved above the loop.
The run_inference_on_image() function is where the image is given to the neural network to do the object recognition. It used to just print out whatever it thought was in the image, but I modified it to instead return the text string containing what it thinks the object is, “coffee mug” for example. So the last line is where it would say “I saw a coffee mug” to the amplifier and speaker.
Boxing all that up gave me a small, standalone package that could be carried around and tried out by anyone. Here’s a video of it in action.
[wpvideo mjtLSbgE]
An improvement would be to add a small screen so that the user could see what the camera sees, but the PiCamera has a wide viewing angle and a screen turns out to be not necessary.
How Good Is Its Object Recognition

Showing it a cell phone often results in it saying it saw a cell phone, but sometimes an iPod. However, so far it has gotten water bottles and coffee mugs correct every time.
However, it doesn’t do well with people. Pointing it at me in my office causes it to say it saw a “tobacco shop, tobacconist shop, tobacconist”, probably due to the shelves of equipment and parts directly behind me. However, standing against a blank wall it said it saw a sweatshirt, removing that it saw a tee shirt, removing that, it said “bathing trunks, swim trunks”, despite seeing only my bare upper torso and head. (I’ll spare you the photo.)


The neural network is trained on a dataset called ImageNet, the version from the Large Visual Recognition Challenge of 2012. That dataset consists of a huge collection of images divided up into 1000 classes, each class containing images of a particular object. As you can see from this small sample from the cell phone class, some of the phone images are a little dated. However, objects such as coffee mugs don’t change over time.
But that didn’t stop everyone who played with it from having fun, walking around testing it on everything in sight, like finding a magic wand for the first time and waving it around to see what it could conjure.
Is That The Best You Can Do?
Well, first off, each recognition takes around 10 seconds on a Raspberry Pi 3 so either that has to be sped up or a faster processor used, preferably one with a CUDA-enabled Nvidia GPU since that’s the only type of GPU TensorFlow currently supports.
The Inception neural net is only as good as the data it’s trained on. The flaws I pointed out above regarding recognizing cell phones and people are issues with the ImageNet dataset. Only 3.46% of the time are all 5 of its best guesses wrong, whereas humans doing the same test are wrong in their 5 best guesses 5% of the time. Not bad.
As we pointed out in our article about the freaky stuff neural networks do today, Long Short Term Memory (LSTM) neural networks can examine what they see in a single frame of a video, while taking into account what came before in the video. For example, it has more confidence that it saw a beach ball instead of a basket ball if the preceeding scene was that of a beach party. That differs from the Inception neural network in that Inception has only the image you show it to go on.
Where Does This Get Us?
Will improved object recognition lead to widespread useful AI with human-like skills? The evolution of the eye is often cited as a major cause of the explosion in lifeforms known as the Cambrian explosion around 541 million years ago, though there is much debate about that being that cause.
When those eyes evolved, however, there was already some form of brain to use them. That brain already handled the senses of touch, vibration and smell. So improved object recognition alone wouldn’t cause a revolution. For human-like skills our AIs would need more intelligence. We currently have only bits and pieces of ideas of what we need for that.
What many agree on is that our AI would need to make predictions so that it could plan. For that it could have an internal model, or understanding, of the world to use as a basis for those predictions. For the human skill of applying a soldering tip to a wire, an internal model would predict what would happen when the tip made contact and then plan based on that. When the tip contacts the wire, if things don’t go as predicted then the AI would react.
Recent work from Facebook with Generative Adverserial Networks (GANs) may hint at a starting point here that contains such a model and predictive capability (if you’re not familiar with GANs, we again refer you to our article about the freaky stuff neural networks do today). The “generative” part of the name means that they generate images. But more specifically, these are deeply convoluted GANs, meaning that they contain an understanding of what they’ve seen in the images they’ve been trained on. For example, they know about windows, doors and TVs and where they go in rooms.
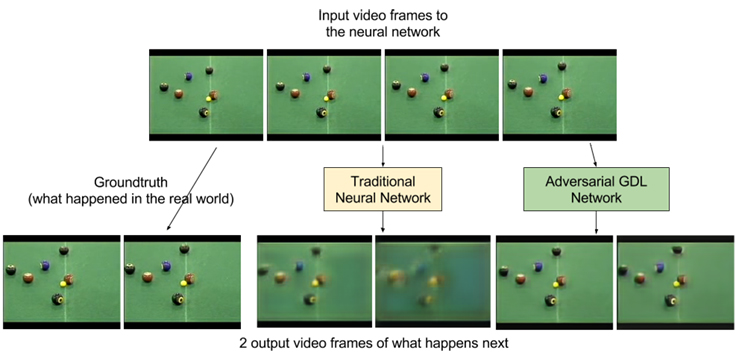
What about making predictions? More work from Facebook involves video generation. Using Adversarial Gradient Difference Loss Predictors (AGDL) they predict what the next two frames of a video should be. In the photo of a billiards game you can see the ground truth, i.e. what really happened, and what the AGDL network predicted. It’s not very far into the future but it’s a start.
Those are at least small steps on the path from a naive object recognizer to one with human-like skills.
In Closing
Where might you have seen the Inception neural network recognizing objects before? We’ve covered [Lukas Biewald] using it on an RC car to recognize objects in his garage/workshop.
While this turned out to be fun for everyone to use as is, what other uses can you think of for it? What useful application can you think of? What can be added? Let us know in the comments below.














instead of using ImageNet to recognize general objects, can I create my own database set of say individuals I know and have this system recognize particular individuals instead of objects? Is that hard to do?
Basically same thing google photos and facebook do.
I don’t know how well it would do with recognizing different individuals (I have no data on that) but you can retrain it. They have a tutorial on doing how to here https://www.tensorflow.org/tutorials/image_retraining.
ImageNet can be retrained, but isn’t the best pick for doing just face recognition. Here’s something a bit more close:
https://cmusatyalab.github.io/openface/
Yes, if you knit programming it could prove viable, however, you might have better results with opencv+HAARTraining.
This might be a good read for you: Machine Learning is Fun Part 4: Modern Face Recognition with Deep Learning. He built a python library that simplifies OpenCV and has even built a VMWare image with all the tools you need to experiment with your webcam (VMWare Fusion Trial will let you map your webcam to the VM). Translating this to an R-Pi3 with PiCamera, loading in an array of images and mounting it to my front door is on my list of projects. Running in VMWare with a single core and 2GB of RAM, it had little trouble recognizing my face from the video feed (used most of that CPU though), I don’t see this being much of a problem for a Pi with a lower res camera (higher resolutions require more convoluting).
Oh, and I found this in my notes if you’re familiar with dockerization on the Pi: https://hub.docker.com/r/joov/rpi-openface/
Hot Dog, Not Hot Dog.
I still want those 8 recipes for octopuses. Attempting to divert my attention from pusses to hot dogs is unbecoming of you Jian!
What about the possibility of adding the camera image to the database and correcting the assessment of what it was when the AI guessed wrong. In escence teaching the unit?
You can do that, but you’d have to retrain it from scratch i.e. the entire database again + your images. You can’t train it on new images without it starting to forget its previous training. Having said that, they do have a tutorial on how to retrain the network with your own set of images (https://www.tensorflow.org/tutorials/image_retraining), so I guess if you can figure out how to combine ImageNet and yours, then you can do it. Not sure of the computational requirements. You’re only retraining the last layer or two in the network as in the fully connected layer in this diagram
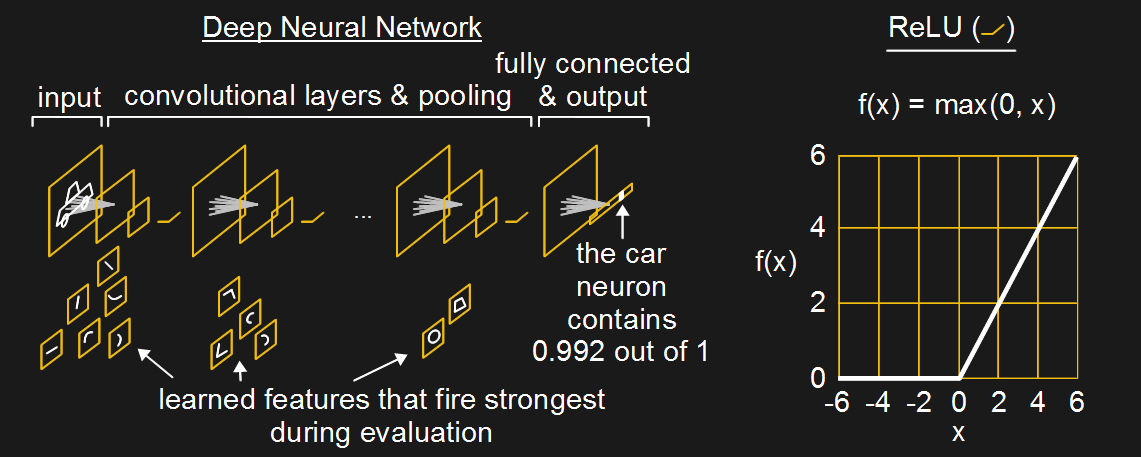
from http://hackaday.com/2017/06/08/from-50s-perceptrons-to-the-freaky-stuff-were-doing-today/.
Have you tried using G.A.N.N.? It is one of the most advanced neural networks and I’m pretty sure you would have a 100% success rate in any type of recognition.
What do you mean by G.A.A.N.? There’s GANs – Generative Adversarial Networks, GANN – Genetic Algorithm Neural Network, and a search turned up G.A.N.N. – Geeks Artificial Neural Network (http://savannah.nongnu.org/projects/gann/).
I am talking about G.A.N.N. – the Geeks Artificial Neural Network. It is a very good framework to build upon. You can find a paper describing its architecture at http://www.academia.edu/20560511/Geeks_Artificial_Neural_Network_G.A.N.N_. I’m pretty certain the results you will get will be much better than the ones using TensorFlow.
Thanks. I’ll have a look.
Would opencv be the best option for counting cars form my road? Or something tensorflow based, or another option? Camera sadly cannot be mounted above the road, needs to be the side and this is what has made my decision difficult. Googling doesn’t seem to have thrown up any easier options which I hoped the would be…
You can try to re-purpose a bean counter.
Detecting a moving object with OpenCV doesn’t require a top down view. Here’s a good example: https://gregtinkers.wordpress.com/2016/03/25/car-speed-detector/
Interesting! Thank you! Harder when the cars are shielded behind other cars, but perhaps I will give it a go! Certainly a good testing of my (poor) coding!!! (far prefer hardware!)
I need to get off my ass and build the squirrel detecting paintball sentry gun that I’ve always wanted.
Amen Brother!
That ADGL example confuses me… is there *anything* changing in any of those frames? I can’t see it.
(The fact I might’ve just failed the Turing test by posting this is not out of the realms of possibility.)
The ball at the top has moved upward and the ball on the left has moved leftward. You can see that they’ve moved closer to the edges of the images. The same thing has happened in the Groundtruth images.
WHERE DOES THIS GET US?
Best on your two sentences after, to Hell!
Nice Work!
If you want to recognize faces or other things more specific then that which the original NN (inception) was trained with, then its possible to add an additional layer/layers to the model, just before it makes the final classification, and then just train those additional layers for your specific application. The original NN is left untouched, and is being used to detect edges and basic shapes & other useful visual cues. ie) no need to start from scratch.
Thanks Jenny!
I have tried to replicate your project on a RPi3. I have found that it will run successfully twice but on the third photo it throws this error:
terminate called after throwing an instance of ‘std::bad_alloc’
Googling seems to point to Tensorflow as the possible source. Did you ever encounter the problem? If so did you manage to fix it?
I’ve never had that problem (or any other) and it’s done many recognitions while booted up — folks tend to walk around with it pointing it at everything. Googling “tensorflow std::bad_alloc” shows many people getting that with TensorFlow and it’s usually attributed to running out of memory. My Rpi3 model B has 1 GB of RAM and a 32GB SD card (not sure if the SD card would matter in this case).
One thing that may be different between yours and mine is that normally the code will download the Inception neural network to /tmp which is on a RAM disk and then decompress it into RAM. As I mention in the article, I’ve copied it from /tmp/imagenet to /home/inception, which is on the SD card, and run it with the command line given in the snapshot in the article, allowing me to give the command line argument pointing it at /home/inception. That way the downloaded, compressed file isn’t taking up RAM, though I do it because it’s rarely connected to the network so downloading isn’t an option anyway. Having said that, I never ran out of memory back when I used to have it in /tmp/imagenet. But give that a try.
If that doesn’t work…
Since it may be running out of memory, how are you storing your images? Possibly you’re accumulating a bunch of them? How big are your images?
Do you have more of the output from when it crashes?
Yet another possibility is that I’m using TensorFlow 1.0 and it’s been maybe two months since my inception was downloaded. Failing all the above, maybe something else changed.
Thank you for your helpful reply. I have pasted my most recent run below:
jay@rpi3ai:~/models/tutorials/image/imagenet $ python3 seeing_eye_w_switch.py –model_dir /home/inception
2017-07-10 17:16:20.316817: W tensorflow/core/framework/op_def_util.cc:332] Op BatchNormWithGlobalNormalization is deprecated. It will cease to work in GraphDef version 9. Use tf.nn.batch_normalization().
medicine chest, medicine cabinet (score = 0.11119)
monitor (score = 0.06366)
desk (score = 0.05311)
television, television system (score = 0.05302)
soap dispenser (score = 0.03141)
Killed
jay@rpi3ai:~/models/tutorials/image/imagenet $ ls -l
total 127324
drwxr-xr-x 10 jay jay 4096 Jun 23 13:19 bazel
-rw-r–r– 1 root root 101505017 Jun 22 09:51 bazel-0.4.5-dist.zip
-rw-r–r– 1 jay jay 566 Jun 21 23:12 BUILD
-rw-r–r– 1 jay jay 7744 Jun 21 23:12 classify_image.py.orig
-rw-r–r– 1 jay jay 7793 Jun 27 01:04 classify_image.py.save
drwxr-xr-x 31 jay jay 4096 Jun 22 23:24 models
-rw-r–r– 1 jay jay 8857 Jul 10 10:05 seeing_eye_w_switch.py
drwxr-xr-x 7 jay jay 4096 Jun 26 08:57 tensorflow
-rw-r–r– 1 jay jay 28584139 May 26 02:56 tensorflow-1.1.0-cp34-cp34m-linux_armv7l.whl
drwxr-xr-x 5 jay jay 4096 Jun 22 23:38 tensorflow-on-raspberry-pi
-rw-r–r– 1 jay jay 227394 Jul 10 09:55 test_image.jpg
-rw-r–r– 1 jay jay 1238 Jul 10 09:54 test_switch.py
drwxr-xr-x 2 jay jay 4096 Jun 21 23:34 tf
jay@rpi3ai:~/models/tutorials/image/imagenet $ ls -l /home/inception
total 181300
-rw-rw-r– 1 jay jay 95673916 Dec 5 2015 classify_image_graph_def.pb
-rw-rw-r– 1 jay jay 2683 Dec 1 2015 cropped_panda.jpg
-rw-rw-r– 1 jay jay 64986 Nov 18 2015 imagenet_2012_challenge_label_map_proto.pbtxt
-rw-rw-r– 1 jay jay 741401 Nov 18 2015 imagenet_synset_to_human_label_map.txt
-rw-r–r– 1 jay jay 88931400 Jul 7 13:11 inception-2015-12-05.tgz
-rw-rw-r– 1 jay jay 11416 Dec 4 2015 LICENSE
-rw-r–r– 1 jay jay 207873 Jul 10 17:17 seeing_eye_image.jpg
jay@rpi3ai:~/models/tutorials/image/imagenet $
As you can see the first photo returned a result, it was a bookcase. The second one ended in the Killed message with no other information.
AI is a new area of curiosity for me and I did have some trouble installing the software so I have listed what I am using in case I have picked up an incompatible version. I have been using htop to monitor cpu/mem use and it certainly seems to be memory use that is causing my crashes.
Regards.
All of your file sizes (other than your own code and images) match mine exactly so it looks like we have the same verison for the inception neural network at least.
As for my memory with inception loaded, I get:
pi@raspberrypi:~ $ free -m
total used free shared buffers cached
Mem: 862 490 371 6 20 247
-/+ buffers/cache: 221 640
Swap: 99 0 99
and top says the same:
top – 18:29:38 up 28 min, 4 users, load average: 0.01, 0.03, 0.06
Tasks: 119 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.0 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem: 883096 total, 502616 used, 380480 free, 21416 buffers
KiB Swap: 102396 total, 0 used, 102396 free. 253896 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
934 pi 20 0 5112 2500 2140 R 0.7 0.3 0:07.14 top
484 root 20 0 341560 180764 32352 S 0.3 20.5 1:08.57 python3
…
The size of the files for you images are around the same as mine too (around 200k) but that doesn’t mean you’re not keep multiple in memory at the same time.
Any chance you can show me your main() and any other function you’ve modified. It may also have something to do with the way you’re using TensorFlow, like having create_graph() in the wrong place. That’s something you want to do only once. In the original code, create_graph() was called from within run_inference_on_image() because there was no loop in the original code. But run_inference_on_image() is something we’re both doing in a loop now.
Just for feedback. You were right, I had left ‘create_graph()’ being called from within ‘run_inference_on_image()’. I also hadn’t realised that I had to edit ‘run_inference_on_image()’ to return ‘human_string’ back to festival. Thank you for an interesting project, which taught me a little bit about AI but mainly to read code and comments more carefully.
I’m glad to hear that fixed it. Thanks for letting me know. Be sure to take it places and show people, they have a lot of fun with it. I’ve even been asked to bring it along to a party this coming Friday.
Oh, and regarding the effort you have to do to make it portable… for my first version I cut a hole in a cardboard box for the camera to look out and just threw everything else in it. People still enjoyed it.
You can use this package I write here at https://thedatamage.com/face-recognition-tensorflow-tutorial/
It simplifies a lot the pipeline you will write.
I’ve tried this myself, but after running inference a few times, ram and swap memory fill up and the pi freezes, would you happen to know why?
I haven’t run this in a long time but when I did, it was often in a hackerspace where it was handed around and so was run continuously doing easily 20-30 inferences.
Did you move the create_graph() call from run_inference_on_image() to main() as the article above says to? The original sample code from Google was intended to do only one inference per execution but you don’t want to create the graph each time. Pay careful attention to the changes I recommend in the article.
Another thing is that I copied the inception neural network onto the SD card and load it from there (see the snapshot of the command line above where I run it using the –model_dir argument with /home/inception). But the software then loaded it into memory in order to use it so I’m not sure how that would make a difference. By default, the software downloads it over the network into a RAM disk.
I also did this back in 2017 and Tensorflow has gone through a few versions since then so maybe something’s broken since.
I also did it on a Pi 3B in case you’re using an older Pi.
Interesting. For an extra $40, you can use a older/cheaper bbb with a gen 1 movidius, run ssd net,… and do the same thing. In a smaller package. Been there. Much easier.