
Things have gotten freaky. A few years ago, Google showed us that neural networks’ dreams are the stuff of nightmares, but more recently we’ve seen them used for giving game character movements that are indistinguishable from that of humans, for creating photorealistic images given only textual descriptions, for providing vision for self-driving cars, and for much more.
Being able to do all this well, and in some cases better than humans, is a recent development. Creating photorealistic images is only a few months old. So how did all this come about?
Perceptrons: The 40s, 50s And 60s
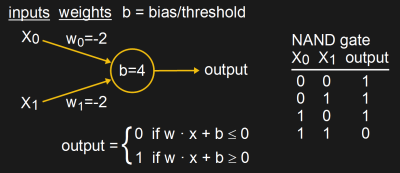
We begin in the middle of the 20th century. One popular type of early neural network at the time attempted to mimic the neurons in biological brains using an artificial neuron called a perceptron. We’ve already covered perceptrons here in detail in a series of articles by Al Williams, but briefly, a simple one looks as shown in the diagram.
Given input values, weights, and a bias, it produces an output that’s either 0 or 1. Suitable values can be found for the weights and bias that make a NAND gate work. But for reasons detailed in Al’s article, for an XOR gate you need more layers of perceptrons.
In a famous 1969 paper called “Perceptrons”, Minsky and Papert pointed out the various conditions under which perceptrons couldn’t provide the desired solutions for certain problems. However, the conditions they pointed out applied only to the use of a single layer of perceptrons. It was known at the time, and even mentioned in the paper, that by adding more layers of perceptrons between the inputs and the output, called hidden layers, many of those problems, including XOR, could be solved.
Despite this way around the problem, their paper discouraged many researchers, and neural network research faded into the background for a decade.
Backpropagation And Sigmoid Neurons: The 80s
In 1986 neural networks were brought back to popularity by another famous paper called “Learning internal representations by error propagation” by David Rummelhart, Geoffrey Hinton and R.J. Williams. In that paper they published the results of many experiments that addressed the problems Minsky talked about regarding single layer perceptron networks, spurring many researchers back into action.
Also, according to Hinton, still a key figure in the area of neural networks today, Rummelhart had reinvented an efficient algorithm for training neural networks. It involved propagating back from the outputs to the inputs, setting the values for all those weights using something called a delta rule.
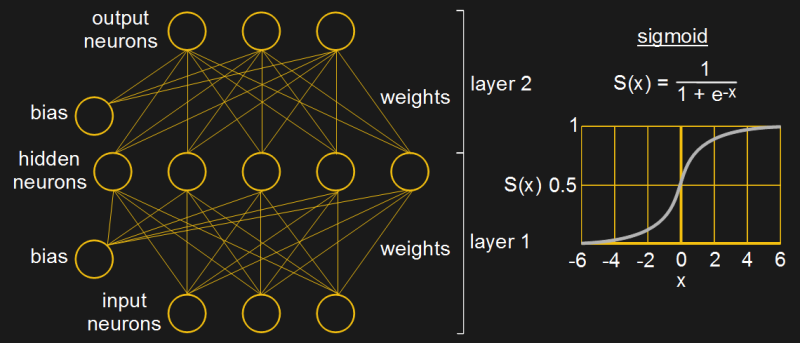
The set of calculations for setting the output to either 0 or 1 shown in the perceptron diagram above is called the neuron’s activation function. However, for Rummelhart’s algorithm, the activation function had to be one for which a derivative exists, and for that they chose to use the sigmoid function (see diagram).
And so, gone was the perceptron type of neuron whose output was linear, to be replaced by the non-linear sigmoid neuron, still used in many networks today. However, the term Multilayer Perceptron (MLP) is often used today to refer not to the network containing perceptrons discussed above but to the multilayer network which we’re talking about in this section with it’s non-linear neurons, like the sigmoid. Groan, we know.
Also, to make programming easier, the bias was made a neuron of its own, typically with a value of one, and with its own weights. That way its weights, and hence indirectly its value, could be trained along with all the other weights.
And so by the late 80s, neural networks had taken on their now familiar shape and an efficient algorithm existed for training them.
Convoluting And Pooling
In 1979 a neural network called Neocognitron introduced the concept of convolutional layers, and in 1989, the backpropagation algorithm was adapted to train those convolutional layers.
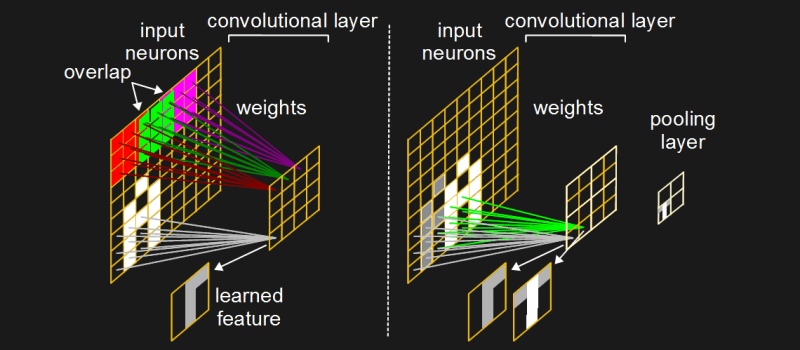
What does a convolutional layer look like? In the networks we talked about above, each input neuron has a connection to every hidden neuron. Layers like that are called fully connected layers. But with a convolutional layer, each neuron in the convolutional layer connects to only a subset of the input neurons. And those subsets usually overlap both horizontally and vertically. In the diagram, each neuron in the convolutional layer is connected to a 3×3 matrix of input neurons, color-coded for clarity, and those matrices overlap by one.
This 2D arrangement helps a lot when trying to learn features in images, though their use isn’t limited to images. Features in images occupy pixels in a 2D space, like the various parts of the letter ‘A’ in the diagram. You can see that one of the convolutional neurons is connected to a 3×3 subset of input neurons that contain a white vertical feature down the middle, one leg of the ‘A’, as well as a shorter horizontal feature across the top on the right. When training on numerous images, that neuron may become trained to fire strongest when shown features like that.
But that feature may be an outlier case, not fitting well with most of the images the neural network would encounter. Having a neuron dedicated to an outlier case like this is called overfitting. One solution is to add a pooling layer (see the diagram). The pooling layer pools together multiple neurons into one neuron. In our diagram, each 2×2 matrix in the convolutional layer is represented by one element in the pooling layer. But what value goes in the pooling element?
In our example, of the 4 neurons in the convolutional layer that correspond to that pooling element, two of them have learned features of white vertical segments with some white across the top. But one of them encounters this feature more often. When that one encounters a vertical segment and fires, it will have a greater value than the other. So we put that greater value in the corresponding pooling element. This is called max pooling, since we take the maximum value of the 4 possible values.
Notice that the pooling layer also reduces the size of the data flowing through the network without losing information, and so it speeds up computation. Max pooling was introduced in 1992 and has been a big part of the success of many neural networks.
Going Deep
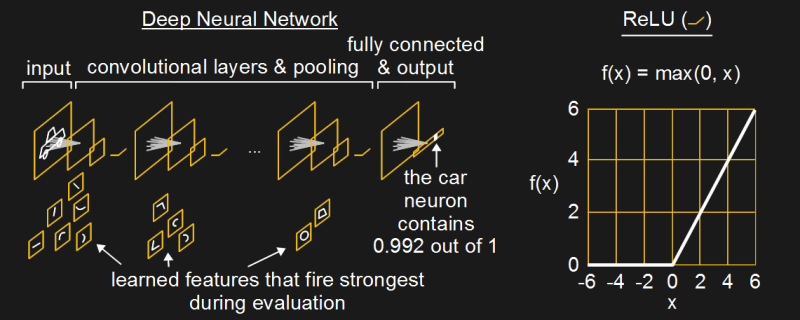
A deep neural network is one that has many layers. As our own Will Sweatman pointed out in his recent neural networking article, going deep allows for layers nearer to the inputs to learn simple features, as with our white vertical segment, but layers deeper in will combine these features into more and more complex shapes, until we arrive at neurons that represent entire objects. In our example when we show it an image of a car, neurons that match the features in the car fire strongly, until finally the “car” output neuron spits out a 99.2% confidence that we showed it a car.
Many developments have contributed to the current success of deep neural networks. Some of those are:
- the introduction starting in 2010 of the ReLU (Rectified Linear Unit) as an alternative activation function to the sigmoid. See the diagram for ReLU details. The use of ReLUs significantly sped up training. Barring other issues, the more training you do, the better the results you get. Speeding up training allows you to do more.
- the use of GPUs (Graphics Processing Units). Starting in 2004 and being applied to convolutional neural networks in 2006, GPUs were put to use doing the matrix multiplication involved when multiplying neuron firing values by weight values. This too speeds up training.
- the use of convolutional neural networks and other technique to minimize the number of connections as you go deeper. Again, this too speeds up training.
- the availability of large training datasets with tens and hundreds of thousands of data items. Among other things, this helps with overfitting (discussed above).


To give you some idea of just how complex these deep neural networks can get, shown here is Google’s Inception v3 neural network written in their TensorFlow framework. The first version of this was the one responsible for Google’s psychedelic deep dreaming. If you look at the legend in the diagram you’ll see some things we’ve discussed, as well as a few new ones that have made a significant contribution to the success of neural networks.
The example shown here started out as a photo of a hexacopter in flight with trees in the background. It was then submitted to the deep dream generator website, which produced the image shown here. Interestingly, it replaced the propellers with birds.
By 2011, convolutional neural networks with max pooling, and running on GPUs had achieved better-than-human visual pattern recognition on traffic signs with a recognition rate of 98.98%.
Processing And Producing Sequences – LSTMs
The Long Short Term Memory (LSTM) neural network is a very effective form of Recurrent Neural Networks (RNN). It’s been around since 1995 but has undergone many improvements over the years. These are the networks responsible for the amazing advancements in speech recognition, producing captions for images, producing speech and music, and more. While the networks we talked about above were good for seeing a pattern in a fixed size piece of data such as an image, LSTMs are for pattern recognition in a sequence of data or for producing sequences of data. Hence, they do speech recognition, or produce sentences.
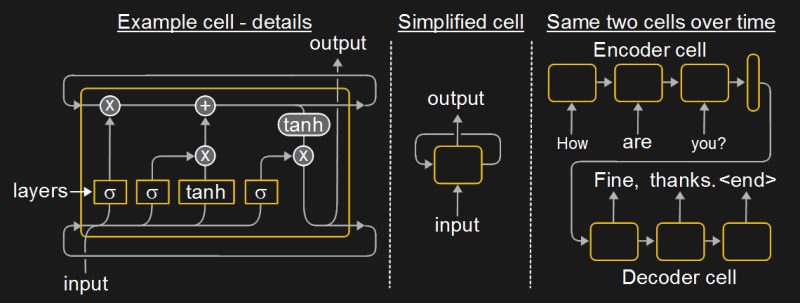
They’re typically depicted as a cell containing different types of layers and mathematical operations. Notice that in the diagram, the cell points back to itself, hence the name Recurrent neural network. That’s because when an input arrives, the cell produces an output, but also information that’s passed back in for the next time input arrives. Another way of depicting it is by showing the same cell but at different points in time — the multiple cells with arrows showing data flow between them are really the same cell with data flowing back into it. In the diagram, the example is one where we give an encoder cell a sequence of words, one at a time, the result eventually going to a “thought vector”. That vector then feeds the decoder cell which outputs a suitable response, one word at a time. The example is of Google’s Smart Reply feature.
LSTMs can be used for analysing static images though, and with an advantage over the other types of networks we’ve see so far. If you’re looking at a static image containing a beach ball, you’re more likely to decide it’s a beach ball rather than a basket ball if you’re viewing the image as just one frame of a video about a beach party. An LSTM will have seen all the frames of the beach party leading up to the current frame of the beach ball and will use what it’s previously seen to make its evaluation about the type of ball.
Generating Images With GANs
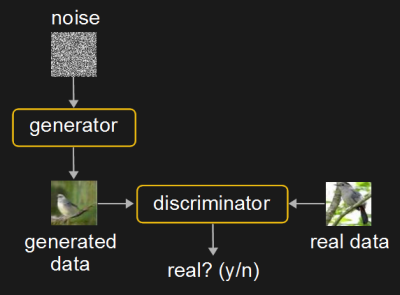
Perhaps the most recent neural network architecture that’s giving freaky results are really two networks competing with each other, the Generative Adversarial Networks (GANs), invented in 2014. The term, generative, means that one network generates data (images, music, speech) that’s similar to the data it’s trained on. This generator network is a convolutional neural network. The other network is called the discriminator and is trained to tell whether an image is real or generated. The generator gets better at fooling the discriminator, while the discriminator gets better at not being fooled. This adversarial competition produces better results than having just a generator.

In late 2016, one group improved on this further by using two stacked GANs. Given a textual description of the desired image, the Stage-I GAN produces a low resolution image missing some details (e.g. the beak and eyes on birds). This image and the textual description are then passed to the Stage-II GAN which improves the image further, including adding the missing details, and resulting in a higher resolution, photo-realistic image.
Conclusion
And there are many more freaky results announced every week. Neural network research is at the point where, like scientific research, so much is being done that it’s getting hard to keep up. If you’re aware of any other interesting advancements that I didn’t cover, please let us know in the comments below.















“A deep neural network is one that has many layers. As our own Will Sweatman pointed out in his recent neural networking article, going deep allows for layers nearer to the inputs to learn simple features, as with our white vertical segment, but layers deeper in will combine these features into more and more complex shapes, until we arrive at neurons that represent entire objects.”
Do the deepest layers incorporate memory where it could eventually have a library of common “objects”?
The layers themselves could theoretically be the memory as they have to be trained as such and thus could possibly use multiple GANS in both reverse and forward to get common shapes and compare it’s likeness to one-another.
The other thing would be to simulate a neuron in range of other neurons activating each-other ready for sending, like patches of ASICs with variable distances and mismatched signal pairs etc to create delays at random so the system has to learn the likely communication between parts of it self, preferably using an in-ASIC broadcast (ASIC self-address).
That way the parts that learnt something new but has no common can try other surrounding items for feedback in a layered approach so that paths of data could be built in such a way that the propagation of information can simulate a learnt hierarchy of the system’s major inputs
The GANS feeding into a discriminator and back can be used as a verifier that the input is real and to give ideas of possibilities, even if not real (i.e. imagination, that odd experience that made no sense, LSD, that quick thinking to save your or someones life, and IMHO Religion-comprehension: To believe in something that cannot be proved or disproved.)
The more of this Neuro-Network research I hear about, the simpler the base concept of the brain feels, the more it feels that we are more a chemical reaction than a humble outer-dimension has-a-voice-and-plan-for-us-thus-thinking-speaking being who supposedly created us… BTW just another view on things, no offense meant to those who do believe.
Sounds more like short-term memory. I’m sure there’s a reason long-term memory is a separate system from information filtering.
Long term memory could easily be the same thing but takes longer to convince, yet quick to feed back with anything that triggers them, i.e. a picture that matches the learnt state of said neurons, hence the self broadcasting ASIC-Neuronet idea (The ASIC learns until it is stable == short to long term conversion).
The way that an Action potential[Wikipedia] affects surrounding neurons gave me the idea, even if not correct:
Seems as though it was a local area broadcast, “Hi I’m ready to talk to Y’all” and/or addressing a chunk of brain (Locally initiated DMA-like effect, maybe?).
Like I said: Idea, unlikely anywhere near correct. Also I fell asleep when trying to read the whole thing.
Yes, whilst society reads them selves to sleep with harry-potter and 50-shades. I read myself to sleep with datasheets, articles, discoveries, news, etc… ;)
The problem with eventually having a library of common “objects” is that with current technology, after having trained the network, if you then start training it for new objects, you “overwrite” the previously trained objects. Really you’re overwriting the weights with new values — the weights are what hold the knowledge, the neurons have values only when they fire. That analogous to the way neurons are connected in the brain defining the knowledge, not the neurons themselves (though the brain may be more complex than that with all its different types of neurons). So to add new objects, you have to add them to the training set of all objects and retrain the neural network.
Quote:
” if you then start training it for new objects, you “overwrite” the previously trained objects”…
True…
Though the opposite of that is cognitive dissonance:
New info contradicts the old and learnt info and the recipient cannot and/or refuses to see the new info.
Sometimes they’re just confused as the mind tries every way to fit said info into their world view (Happens to myself sometimes, Within the forms of ASD I have: that is one of the enhanced spectrums in my case)…
On the other hand the person gets extremely agitated and sometimes violent…
Esp when religion is involved…
Have fun with the flat-earther’s comments on both the flat-earth and round-earth youtube videos and yes, in some videos it is clear that said flat-earthers used inverted (slightly Concave or lesser convex) lenses to make the upper-mid atmosphere look flat. The ground looks curved before flight thus giving away their deceit… LOL.
And they don’t even attempt to fly to the upper atmospheres that their Quad was capable of.
But what’s the equivalent psychological disorder for someone who overwrites old memories with new? Retrograde amnesia is close (https://en.wikipedia.org/wiki/Retrograde_amnesia) but you only lose access to the old memories. I guess you might overwrite them over time, but overwriting isn’t the cause of the problem.
About the bird, the bird is the word…..
That fake bird picture however, It also looks real in peripheral vision:
I actually looked to the side of the picture intentionally,
looking at the edge of the words to the right of the picture.
My brain filled in the gaps:
Added/corrected the eyes by inverting the light creamy-brown feather colour between the brow and the thin brow-like fake eye area,
smoothed out the wings whilst filling in feathers that wern’t there,
corrected the beak,
other auto-tweaks the brain does to improve what it thinks it is seeing from the lower resolution parts of the eyes
Concluded that it looks like a common house finch.
.
If I saw that in the corner of my eye, I’d thought a bird was actually there….
Until looking directly at it.
I noticed the same thing. It’s a bit disconcerting.
But it also gets at the heart of the difference between seeing and perceiving. Brains are weeeeird.
https://github.com/hanzhanggit/StackGAN
If anybody is interested in exploring or improving the code for StackGAN.
“achieved better-than-human visual pattern recognition on traffic signs with a recognition rate of 98.98%”
Not hard to do as less than 70% of humans with drivers licenses seem to actually recognize street signs.
They have to get past the stage of recognizing the following first:
They are human,
What a driver’s license really means,
The fact they are even on the street, how they got there and in what….
All that before they even start to begin to comprehend the signs they might not be suited to the road!!!
Yeah, but just wait until we give th AI a cell phone to text on! ;-)
19th century?
Fixed. Thanks.
“Convoluting” = convolving.
BTW, the Air Force had a project using bundles of “neuristors” in the 1950’s. I have it in a book from then. A quick search shows plenty on a later device, but not the old project.
> We begin in the middle of the 19th century.
So, uh, Chuck and Ada invented neural networks, too?
Ada did. Chuck made the CPU and GPUs… Fixed. Thanks.
I’ve been working independently on a system where programs also flow through the network and not just data. By programs I am talking about truth tables for simple Turing machines and the flow of data and programs interact in loops within the network as bit streams passing through shift registers. I am implementing it as low level logic in a simulator but it could transfer very directly into a FPGA. I have no idea if it relates to anyone else’s work as I have been more interested in playing with it myself than reading enough of the literature to discover if I have any peers in this regard. I am at the stage where it is producing patterns and structured sequences in a manner that is “interesting” enough to suggest that it is worth exploring further.
Essentially if is a completely dynamic neural network cellular 2D automata hybrid. 3 or more dimensions are possible and having the connections also defined dynamically is a logical step too, then it is n dimensional, and completely self reconfigurable, able to truly evolve or learn.
And Skynet is born. :-p
LOL, yeah well I was thinking of taking the work onto an isolated network for other reasons but there is that too.
“Neural network research is at the point where, like scientific research…”
So then, neural network research is most definitely not scientific research. Sounds reasonable, particularly if neural network research is at all tied up with AI–whatever that is.
They should first develop an AI that can mimic a modern politician, then a simple animal, then a human.
Maybe throw an insect between that list somewhere.
Turns propellors into birds… just like the ancient civilisations putting wings on gods and “angels” etc because they come from the sky? Definitely an interesting find imho.