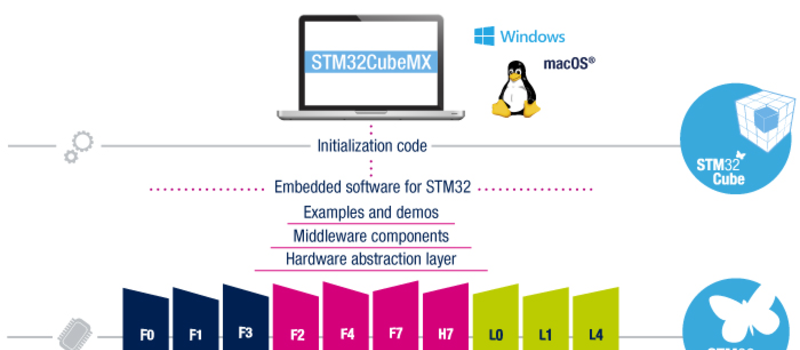
When hardware manufacturers make GUI code-generation tools, the resulting files often look like a canned-spaghetti truck overturned on the highway — there’s metaphorical overcooked noodles and red sauce all over the place. Sometimes we think they’re doing this willfully to tie you into their IDE. Not so the newest version of ST’s graphical STM32CubeMX, which guides you through a pleasant pin-allocation procedure and then dumps out, as of the latest version, a clean Makefile.
Yes, that’s right. This is a manufacturer software suite that outputs something you can actually use with whatever editor, GUI, compiler, or environment that you wish — even the command line. Before this release, you had to go through a hacky but functional script to get a Makefile out of the CubeMX. Now there’s official support for real hackers. Thanks, ST!
If you’re compiling on your own, you’ll need to update the BINPATH variable to point to your compiler. (We use the excellent GNU ARM Embedded Toolchain ourselves, which is super-easy to install on almost any Linux.) If you want to use STM32CubeMX with the Eclipse IDE, [kali prasad yadav] sent us PDF instructions — it’s not hard.
If you doubt that the availability of a free, open, and non-constraining toolchain can matter for a silicon vendor, we’d point to AVR and the Arduino platform that spun off of their support of GCC. Sure, Atmel still pushes their all-in-one wonder, Atmel Studio, which is better than the Arduino IDE by most any metric. But Studio is closed, and Arduino is open. We’d love to see the number of Studio users compared with Arduino users.
Congratulations to ST for taking a big step in the right, open-toolchain, direction.














Now If only they had some kind of documentation on their HAL library…
Actually, they have documentation: http://www.st.com/resource/en/user_manual/dm00122016.pdf
It’s pretty crappy, though.
God knows. Doxygen has turned out to be the bane of software engineering of libraries in my opinion, because it makes it too easy to generate useless documentation and then check off that task in your product release cycle.
SFML does it right, as one of the few:
https://www.sfml-dev.org/documentation/2.4.2/
This is done with doxygen.
But, yes, usually you get this https://dbus.freedesktop.org/doc/api/html/index.html
Haha, yes exactly. Kudos to SFML and shame to the other thing. I have no idea what SFML is, but taking a quick peek reminded me of another gripe I have about Doxgen-esque systems: there is no documentation of the relationship amongst the components — like timing, sequence, utility, etc. So you’re still left with a more-or-less flat surface of function signatures that you get to figure out what the relationship is amongst them.
Again, my complaint is primarily that Doxygen-esque systems are meritorious in their intent, but they fall short on their delivery. Additionally, I think they have a toxic effect of serving as an analgesia for the pain of having to produce genuinely useful documentation for your projects/products.
I curse Doxygen documentation every time I see it. It makes the code unreadable and it’s almost never up to par with real documentation.
Of course, that may be an unfair benchmark. If Doxygen is providing an easy enough system that those represent projects that would have otherwise gone undocumented, maybe it’s a good thing. (AKA: better than nothing.)
But meh. I have two monitors. Give me code in one and docs in the other any day.
I curse Doxygen documentation because I know that it is 87% likely to be nothing but the function signature anyway, maybe with the parameters. Duh! I can see that without the documentation. (and this HAL library documentation demonstrates my point). It also gives me a finger-in-the-wind as to the quality of the code, or at least the risks in using it. If you’re not proud enough about the stability, utility, and quality of your code to invest in good documentation, then ‘caveat programmer’.
There are chips/systems/services which I will not design in, because their support libraries are just too risky/expensive in work hours to get something useful. In the case of the STM products, I’m pretty happy. I would give them about a B to B+ on the library stuff. +points for coverage of functionality of the chips, -points for documentation on how to use it meaningfully. And the example code is toy code, but that’s been the case for many decades…
True. I also inherited some Doxygen documentation and I’m working hard to get rid of that utterly useless crap by having both useful external documentation and readable/well-documented code.
The future will thank you. And maybe you will thank yourself! I tend to forget everything I have done after about 6 mo.
I tend to forget everything I do after about 6 PM.
Neat! How does STM32CubeMX compare to libOpenCM3?
It can be used in closed-source applications, for one.
Going by the license, so can libopencm3: as it is LGPL, you just have to provide your application as a .a file that can be linked against someone else’s libopencm3 binary. (ABI compatibility is their problem.)
Code/style-wise: really different. Download and code up hello world stuff and you’ll see.
opencm3 has less coverage, but is also a ton less bloated. And it’s open. ST’s libs say that they can only be used with ST’s parts. Opencm3 has some degree of cross-compatability with non-ST ARM chips, although the devs do most of their work on ST parts, so it’s still slanted.
I still use the SPL for ST parts in C, so I’m not an expert, but I’ve played around with opencm3 and the HAL. Honestly, I wouldn’t hesitate to use any of them, although opencm3 will require you to know a little bit more what you’re doing because it’s a little rougher.
If you want to help write future libs and give back to the community, go opencm3. If you just want to use the code and get running ASAP, go Cube/HAL. (IMO.)
And if you want to use STM32F0 chips, don’t use libopencm3. It has major shortcomings for that family (at least, as of February of this year) that make it verge on useless. For a good, open STM32F0 library, I recommend ChibiOS, whose HAL can be used without an RTOS if you really don’t need one.
Some years ago I chose the AVR for use in a mass-produced telecommunications product (a PABX multi-extension I/F card), primarily on its gcc support. (That was where PIC lost out) I’ve used the AVR ever since in private projects, because once you accumulate an understanding of the peripherals, and a code library to support them, jumping ship is unproductive. What I have not changed between PowerPC, V850, AVR, etc. targets is the toolchain – gcc & binutils handle them all.
Writing makefiles is no big deal, especially if you have the O’Reilly book on hand. (Just don’t forget the tabs. ;-)
Not hard, but if one is going to use a tool that generates code it makes it much easier to tie into everything else if it’s as clean as possible. There could even be said to be efficiency reasons for keeping it clean.
By the way, does anyone know the way to integrate makefile-based project into IDE? I’m particularly interested in graphical debugging.
Most binaries with debugging symbols have enough information in them for a reasonable debugger to pick them up and find their source files once you point them to the root of the source tree. The debug symbols gcc adds with -g or -ggdb can be read by ddd, eclipse, or DS-5 and probably a number of others. The trick is to get the debugger to find the source tree, which the makefile does not particularly help with. I’m an old fart though, so I usually use gdb or gdbserver, where you can use the directory command or -d cli option to specify the source search path.
FYI, the ARM part of Atmel Studio is using GCC tools.
Agreed, you can download the asf libs separately and with the aid of the arm-none-eabi toolchain and custom Makefile, start developing for samd21s or other atmel/microchip parts under Linux. Downloading binaries can be done via Arduino bootloader or jlink which supports also supports Linux.
STmicro have also recently completed adding low level apis to the stm32 libs for all of their parts. These low level apis are more granular than the stm32cube HAL, use less memory and mimic the SPL. http://www.st.com/content/st_com/en/about/media-center/press-item.html/n3949.html
Hot damn! I just read the blurb, haven’t tried the code yet, but that sounds like _exactly_ what I’ve been looking for. (In _any_ microcontroller family, honestly. For the last fifteen years!)
Will check out. Maybe even review if it’s cool enough.
Thanks, thanks for the tip!
The link to the GCC toolchain is outdated; new versions are published only on the new ARM site: https://developer.arm.com/open-source/gnu-toolchain/gnu-rm
The fact that you need a graphical tool for generating code for the “HAL” API only shows the quality of said API…
Or the complexity of the chip.
Many of the pins have multiple functions, and using a GUI to map them all out really is handy.
I agree that the CubeMX Software is handy for this purpose. But I find it only handy for the purpose of ensuring pin configurations do not overlap with/prevent proper function of attached peripherals during the schematic and board layout process. The code generation is absolutely horrid if you need to maintain your code base and actually understand it. CubeMX for planning and SPL seems like the happy medium. It would be nice if you could control the degree to which CubeMX generates code…
As someone who hates setting up toolchains (I can do it, but I hate it), I’m glad to see ST making some progress in this area.
Also realize that the complementary product, STM32 System Workbench, is essentially a packaged up gcc toolchain, openocd, and also Eclipse for C++ preconfigured. You don’t have to use the Eclipse part if you don’t want to, the gcc command-line stuff is accessible as well. Anyway, much easier setup than, say, yagarto of years past.
The STM32CubeMX is essentially a options configurator (which is pretty wonderful for complex parts with a zillion clocking/pll options) which emits stuff like makefiles and skeleton code. If you’re careful about how you edit that skeleton code, you can round-trip back-and-forth with CubeMX changing things (which I sometimes have to do more frequently than I would care to admit).
Some of the libraries leave things to be desired (USB), and fair warning, ST sometimes changes the libraries in incompatible ways between versions.
But overall, it can get up up and running from scratch pretty quickly.
Very useful, thanks Elliot. USS HAD would break up and sink without trace if it wasn’t for the quality articles you people like AL post.
Anybody know a good tutorial for learning how to use this makefile? configuring openOCD and gdb ect? I can’t really find anything for the stm32.
Hmmm, Youst found this thread… but really, as we write 2021, I still have issues liking the CubeIDE way of doing makefiles…
Or rather, setting up a project at all. I have existing projects using for example Stm32h743vit, using gcc and my own makefiles. Compilable from commandline, if needed, and these projects may be imported into most IDEs which supports custom makefiles, crossplatform and easily ported. Just not with CubeIDE.
Eclipse do support custom makefiles projects, but to have full debug capability with jlink/stlink one need to create the project as a STM32 project from CubeIDE. But then creating a project which should accept both existing code and custom makefiles seems to be a banned option. And if using the option to create a “empty STM32 project” the project, to import own files later, is anything but empty, but it is readdy made with a set of source files like startup , memory map and main, and the project settings are scattered troughout workspace and setting files and, well, NO custom makefile.
Why oh why cant CubeIDE just support a projectsettup where one could point to a folder, the existing project folder with the existing code, and a custom makefile, and then just ask for board type or CPU, and be happy with it… It is fairly easy and any other… well, most other IDEs can do it except for the debug capabilities with sfrs and such, which is the only benefit so far with CubeIDE over the others and is why I want to use it,.
I am able to use C:b and codelite and commandline whenever that is required, but CubeIDE is smoother when it comes to debugging but the project settup is dreadfull… Or, a bit frustrating at least… Isn’t it possible to use custom makefiles with Cube??? Sorry for my english though,