
Open Source software is always trustworthy, right? [Bertus] broke a story about a malicious Python package called “Colourama”. When used, it secretly installs a VBscript that watches the system clipboard for a Bitcoin address, and replaces that address with a hardcoded one. Essentially this plugin attempts to redirects Bitcoin payments to whoever wrote the “colourama” library.
Why would anyone install this thing? There is a legitimate package named “Colorama” that takes ANSI color commands, and translates them to the Windows terminal. It’s a fairly popular library, but more importantly, the name contains a word with multiple spellings. If you ask a friend to recommend a color library and she says “coulourama” with a British accent, you might just spell it that way. So the attack is simple: copy the original project’s code into a new misspelled project, and add a nasty surprise.
Sneaking malicious software into existing codebases isn’t new, and this particular cheap and easy attack vector has a name: “typo-squatting”. But how did this package get hosted on PyPi, the main source of community contributed goodness for Python? How many of you have downloaded packages from PyPi without looking through all of the source? pip install colorama? We’d guess that it’s nearly all of us who use Python.
It’s not just Python, either. A similar issue was found on the NPM javascript repository in 2017. A user submitted a handful of new packages, all typo-squatting on existing, popular packages. Each package contained malicious code that grabbed environment variables and uploaded them to the author. How many web devs installed these packages in a hurry?
Of course, this problem isn’t unique to open source. “Abstractism” was a game hosted on Steam, until it was discovered to be mining Monero while gamers were playing. There are plenty of other examples of malicious software masquerading as something else– a sizable chunk of my day job is cleaning up computers after someone tried to download Flash Player from a shady website.
Buyer Beware
In the open source world, we’ve become accustomed to simply downloading libraries that purport to do exactly the cool thing we’re looking for, and none of us have the time to pore through the code line by line. How can you trust them?
Repositories like PyPi do a good job of faithfully packaging the libraries and programs that are submitted to them. As the size of these repositories grow, it becomes less and less practical for every package to be manually reviewed. PyPi lists 156,750 projeccts. Automated scanning like [Bertus] was doing is a great step towards keeping malicious code out of our repositories. Indeed, [Bertus] has found eleven other malicious packages while testing the PyPi repository. But cleverer hackers will probably find their way around automated testing.
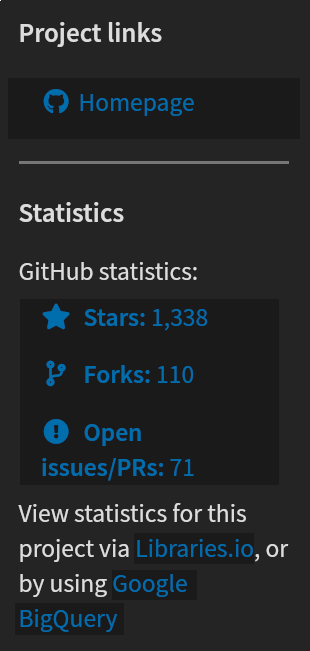 That the libraries are open source does add an extra layer of reliability, because the code can in principal be audited by anyone, anytime. As libraries are used, bugs are found, and features are added, more and more people are intentionally and unintentionally reviewing the code. In the “colourama” example, a long Base64 string was decoded and executed. It doesn’t take a professional researcher to realize something fishy is going on. At some point, enough people have reviewed a codebase that it can be reasonably trusted. “Colorama” has well over a thousand stars on Github, and 28 contributors. But did you check that before downloading it?
That the libraries are open source does add an extra layer of reliability, because the code can in principal be audited by anyone, anytime. As libraries are used, bugs are found, and features are added, more and more people are intentionally and unintentionally reviewing the code. In the “colourama” example, a long Base64 string was decoded and executed. It doesn’t take a professional researcher to realize something fishy is going on. At some point, enough people have reviewed a codebase that it can be reasonably trusted. “Colorama” has well over a thousand stars on Github, and 28 contributors. But did you check that before downloading it?
Typo-squatting abuses trust, taking advantage of a similar name and whoever isn’t paying quite close enough attention. It’s not practical for every user to check every package in their operating system. How, then, do we have any trust in any install? Cryptography solves some of these problems, but it cannot overcome the human element. A typo in a url, trusting a brand new project, or even obfuscated C code can fool the best of us from time to time.
What’s the solution? How do we have any confidence in any of our software? When downloading from the web, there are some good habits that go a long way to protect against attacks. Cross check that the project’s website and source code actually point to each other. Check for typos in URLs. Don’t trust a download just because it’s located on a popular repository.

But most importantly, check the project’s reputation, the number of contributors to the project, and maybe even their reputation. You wouldn’t order something on eBay without checking the seller’s feedback, would you? Do the same for software libraries.
A further layer of security can be found in using libraries supported by popular distributions. In quality distributions, each package has a maintainer that is familiar with the project being maintained. While they aren’t checking each line of code of every project, they are ensuring that “colorama” gets packaged instead of “colourama”. In contrast to PyPi’s 156,750 Python modules, Fedora packages only around 4,000. This selection is a good thing.
Repositories like PyPi and NPM are simply not the carefully curated sources of trustworthy software that we sometimes think them to be– and we should act accordingly. Look carefully into the project’s reputation. If the library is packaged by your distribution of choice, you can probably pass this job off to the distribution’s maintainers.
At the end of the day, short of going through the code line by line, some trust anchor is necessary. If you’re blindly installing random libraries, even from a “trustworthy” repository, you’re letting your guard down.














something something, always build from source, something something package managers are the devil, something something use slackware, something something
something something, if you are not like me you don’t know how to use linux something something – what I’m betting most of the comments are gonna be.
lol what do all those somethings add to that sentance?
This is about Python code — it _is_ the source. Similarly the NPM attacks, etc.
The point is that there’s too much source out there, and nobody can check it all. But even if someone is, do you trust them? Did you even do the least bit of research? Or just
make config && sudo make install?Linux distros really put the bullet in the brain of building from source. Before we had linux distros we had to know how to type make and before autoconf even edit a bit of the top of a makefile. That being said, I don’t ever recall combing through source code looking for malice. About the only time I would colb through source code was to modify the way something worked to suit my needs or more often, if something would not compile. Back in the day, if someone put something malicious in some free code that got passed around they would be able to laugh their asses off as the users would have compiled their own problem. I think that is one of the big things a lot of the public does not get about open source. 99.9% of the users never poke through it. I doubt the people who build the packages for the distros comb through it. So it has the potential to be safer via the user community reviewing the source code but (1) we are assuming the user community is doing that. I am not, are you? And (2) we are assuming that the binaries we are running are built from that very same source which may or may not be the case.
This is why I also highly distrust the new, “improved” package management systems for Linux like Snap and Flatpak. The Flatpak developers at least try to build a somewhat trustworthy central repository (Flathub), with mixed success, while Canonical allows everybody and their dog to upload anything they like. They have already had at least two malware packages in their store, while I have never heard about a compromised package in the official Debian or Ubuntu archives.
As said in the article, having proper maintainers and a chain of trust is a required feature, not a bug.
thankyou!
FYI, Debian is on Google+, they post information about new found bugs almost daily.
(That certainly doesn’t stop me from trusting Debian, just the opposite.)
Kind of like the Docker hub.
If you have never heard of a malware on a specific repository, they most likely haven’t been noted yet. Right? Kkkkkkkk (laughs)
Interesting that this is a windows specific Python package. Not sure what to say about that.
Build everything from source? Not possible. I wouldn’t have a life. And that doesn’t buy you much unless you audit the source you are building from. So you are left relying on a chain of things and people at any event. Now if you install a specific and somewhat offbeat package like “colorama” you might want to be more careful and check things personally.
doing any sort of development under windows unless your hand is forced or you are writing MS software, its an ill advised choice fraught with difficulty and despair.
One strategy I have used is to look at the continuity of updates. If a package has one or more contributors working on it over time with sensible commit messages and proportionate diffs that means it is a lot more likely that it is A) real rather that fake and B) active enough that it is likely to have people fixing bugs and someone to review any bug fixes I may want to submit. (It sucks to incorporate a library into your project and discover that it is buggs and nobody else is working on it).
Also. I am far from a style Nazi when it comes to code (I recognize that different developers find different styles intuitive and don’t believe in a “one true style guide to rule then all”) but if the code of a project is either intentionally obfuscated or so counterintuitive in it’s style that I find it hard to follow I am likely to pass it over in favor of a more comprehensible one not just because it might contain sneaky subroutines but also because if I’m debugging my project and have to trace (backwards or forwards) through an unreadable soup it makes debugging miserable.
I ‘ve been around the block a couple times though and these heurisics may be harder for a new developer to use (because the portion of legit code that may seem opaque starts out large and shrinks with experience and fluency) so it is by no means a one-size-fits-all approach, however the effort of faking a well-maintained lively project with readable code and obfuscations so clever as to avoid raising any red flags could easily outstrip the payoff of such a scam (I.e. someone who’s a skilled enough developer and willing to sink enough time into the enterprise as one would have to would likely get a better payoff for their time if they took a job as a computer programmer for some legitimate outfit).
Interesting viewpoint on code style – we had a discussion at work about this (code review depth), which split into two camps:
1. Odd-looking code will get reviewed more carefully and in depth ‘because it smells funny’
2. Odd-looking code will be less likely to be reviewed in depth ‘because it’s hard’.
Microsoft published a talk on using an AST along with a lot of machine learning to identify malicious looking PowerShell code based on frequency of use of various language features.
Hmm, somehow that sounds like recognizing those fake email’s with bad spelling :P
Yes, but Microsoft charged Certified Microsoft Professionals a lot of money for them to be able to identify them in that way.
B^)
Another data point: TWICE in 2016, the official distribution chain for BitTorrent client Transmission was intercepted, and so their official builds of Mac OSX clients contained ransomware.
https://www.macrumors.com/2016/08/30/transmission-keydnap-os-x-malware/
It is impossible for open-source repositories to police everything that goes into them. The software universe is simply Too Big, there are Too Many Contributors, and no way to ensure that any organization could test for these sort of things. Further, the chain can be compromised at any point – from a malicious developer on down to a shady distributor, a hacked compiler, whatever.
One of the eye-opening things about participating in FOSS (for me, via GitHub) is finding out just how many critical packages are run by one or two guys in their free time. Did you know the BZIP2 website went down recently because there’s no maintainer to keep the site up? We all assume the important stuff is carefully managed by a big organization who can keep track of these things. It’s very revealing, and scary, to peek behind the curtain.
This is also the same for Go packages and even worse as there is no central authority.
What about Fdroid?
The thing you will have these Open source zealot screaming when you will submit the idea of signing packages or raising the bar, remember signed add-ons in Firefox.
I am a FOSS user for 19years now but I am really afraid of the GitHub/NPMization of the Open Source softwares for the last 5-7 years
I’ve worked with the Fdroid guys, and I’d trust their packages far more than the Google play store. They’re just about paranoid with review and package security.
So why is open source so great again?
Only big OS software projects are checked for malicious or even non-malicious code.
When there are problems discovered, no one is held accountable.
Like if Altium AD was bricking workstations, Altium would see a drop in sales, so they’re motivated to prevent that.
What motivation do KiCAD programmers have?
Hiding source code is just as bad as software without financial accountability IMHO.
Reputation is the motivation. If a KiCAD programmer intentionally put malicious code into the project, he would be kicked off the project, as well as his reputation tarnished forever. That’s part of the reason many projects require using real names for all code submissions.
So they’re motivated by the reputation of a possibly real name on projects big enough where their code is actually reviewed?
What’s the accountability again?
What does this have to do with OSS? It has more to do with package management than OSS. Everything could have been closed source and it wouldn’t make it much more difficult. The headline implies the malicious code was pushed upstream to the original repo. It was not.
The malicious package was the result of the source code from a legitimate project being copied into the new, malicious project. That particular attack vector isn’t possible with closed source, and is one of the common reasons people give for not open sourcing their otherwise free programs.
Good that you know who to trust and who not to.
“If you ask a friend to recommend a color library and she says “coulourama” with a British accent, you might just spell it that way”
We say and spell Colour correctly in New Zealand too.
https://hackaday.com/2018/10/31/when-good-software-goes-bad-malware-in-open-source/ amazing article, highly recommend it