Suppose you ran a website releasing many articles per day about various topics, all following a general theme. And suppose that your website allowed for a comments section for discussion on those topics. Unless you are brand new to the Internet, you’ll also imagine that the comments section needs at least a little bit of moderation to filter out spam, off topic, or even toxic comments. If you don’t want to employ any people for this task, you could try this machine learning algorithm instead.
[Ladvien] goes through a general overview of how to set up a convolutional neural network (CNN) which can be programmed to do many things, but this one crawls a web page, gathers data, and also makes decisions regarding that data. In this case, the task is to identify toxic comments but the goal is not to achieve the sharpest sword in the comment moderator’s armory, but to learn more about how CNNs work.
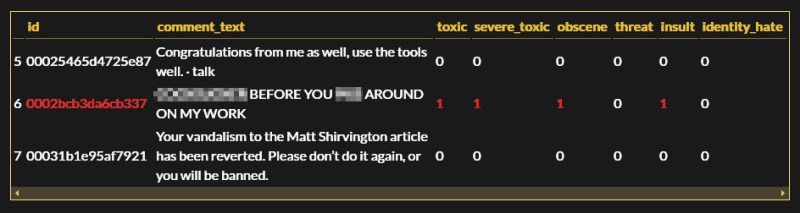
Written in Python, the process outlines the code itself and how it behaves, setting up a small server to host the neural network, and finally creating the webservice. As with any machine learning, you need a reliable dataset to use for training and this one came from Wikipedia comments previously flagged by humans. Trolling nuance is thrown aside, as the example homes in on blatant insults and vulgarity.
While [Ladvien] notes that his guide isn’t meant to be comprehensive, but rather to fill in some gaps that he noticed within other guides like this, we find this to be an interesting read. He also mentioned that, in theory, this tool could be used to predict the number of comments following an article like this very one based on the language in the article. We’ll leave that one as an academic exercise for now, probably.













Sounds like the most direct path possible to elitist dystopia.
Only humans are “human and humane”.
Love the “identity_hate” flag, clears any confusion as to the motivations behind the project.
…prrreeeeventing identity hate as well as other kinds? You… say that like it’s bad.
I’m not a fan of identity politics, nothing about this project is unbiased from the onset.
Silencing someone doesn’t “prevent” their opinions. That’s how authoritarians think.
Looking for “offence” and “hate” is probably impossible and likely counterproductive and a possible risk to free-speech, but if you could just detect anything rabid and angry that would do a fair bit of good and might be easier to detect (short sentences, BLOCK CAPITALS, tabloid like phrases, common profanities in excessive use without context). Whatever the sentiment behind whatever comments got through atleast it would calm the debate down a bit, sure the sides still hate each other but now they have to say so calmly and their hate looks more ridiculous when they have to form it as proper sentences Ensure that the opposing sides found themselves talking to a normal member of their opposition rather than to the most raging of fanatics. A kind of cure for this https://www.smbc-comics.com/comic/2013-04-07 .
I can’t imagine any of the comments on THIS article becoming super toxic! /s
@jnesselr, there’s one already above yours.
” If you don’t want to employ any people for this task, you could try this machine learning algorithm instead.”
Or use both. It doesn’t have to be either/or.
“He also mentioned that, in theory, this tool could be used to predict the number of comments following an article like this very one based on the language in the article. We’ll leave that one as an academic exercise for now, probably.”
Trigger words and degree of reaction.
This is a really poor design/implementation. Right off the bat you’ll see it only examines the first N characters of a comment.
“MAX_SEQUENCE_LENGTH is used in the preprocessing stages to truncate a comment if too long.”
“Probably doesn’t need much more for the network to discern it’s a toxic comment”
Once the max length is passed, a comment could get away with containing any amount of toxicity.
It appears very intentional. Maybe he tried this without length/word restrictions and it took too long.
Consider if this was run on thousands or millions of comments per day. You’ll want to reduce the computational expense. Sampling fixed-length substrings is an easy out and should be “good enough” for most purposes.
Maybe use random offsets. Longer comments may get by if there’s a small sprinkle of profanity. Super long comments could be sampled multiple times.
A website releasing many articles per day about various topics, all following a general theme? Preposterous!
Your vandalism to Bryan Cockfield’s article has been reverted. Please don’ do it again, or you will be banned. :)
Sounds like a brilliant tool for keeping on top of spam users on hackaday.io…
A quick peruse of https://hackaday.io/hackers?sort=newest shows a few entries from a certain Polish spammer that really shouldn’t be there.
I got pretty far detecting those accounts without convolutional neural networks (I just looked at what words were being used and who previously used those words), however the real fix is something that runs on SupplyFrame infrastructure, not “bolted to the outside” like mine was.
My project basically shut down because I kept getting IP-blocked which lead me to conclude that SupplyFrame actually _want_ the spam.
You report ’em, our web folks delete ’em. If you see any spammy projects, it’s just because they/we/you all can’t keep up with the influx. We will eventually, though.
Why would you get IP blocked? If that’s a real problem, definitely take it up with Sophi. That shouldn’t happen. Nobody wants spam.
This is an interesting use for machine learning. I’m a little more interested in it’s use in senolytics/cancer research though.
what is a toxic comment?
A comment can be toxic in the same way that a cigarette is. Any single episode is unlikely to cause noticeable physical or mental damage. But over time, if left unchecked, the body’s resilience will eventually be overcome.
(For the record, cigarettes are toxic.)
Any comment made with smoke signals using hydrazine and dinitrogen tetroxide.
I see the fReE sPeEcH brain geniuses have logged on to comment on an article about commenting on articles