
2020 is a year of reflection and avoiding regret, and one of the biggest practices we all know we should do better is back up our data. Inevitably there will be a corruption or accident, and we mourn the loss of some valuable data and vow to never let it happen again, and then promptly forget about good data retention practices.
I believe life is about acquiring memories, so it makes sense to me to try to archive and store those memories so that I can reflect on them later, but data storage and management is a huge pain. There’s got to be a better way (cue black and white video of clumsy person throwing up arms in disgust).
Nice Cloud You Have There; Shame if Something Happened to It
The teens of the century saw a huge shift towards cloud storage. The advantages of instantly backing up files and using the cloud as the primary storage for all your devices is appealing. It’s now easier to transfer files via the cloud than with a cable. With Google Docs and WordPress we have our most important documents and writing stored as database blobs on someone else’s servers. Facebook and Google and Flickr record all of our memories as photo albums. Unlimited storage is common, and indexing is so good that we can find photos with a vague description of their contents.
These things are instantly accessible, but lack permanence. Gone are newspaper clippings and printed photos discovered in a shoebox. When we aren’t in control of those services, they can disappear without any warning. Even some big offerings have packed up shop, leaving people scrambling to back up data before the servers were shut down. Google Plus is closed, Yahoo Groups is closed, MySpace lost all content created prior to 2016, GeoCities closed in 2009, and Ubuntu One closed in 2014. It’s safe to say that no online content is safe from deletion. It’s also safe to say that cloud storage is a difficult location from which to extract your data.
With the risk of data leaks and privacy violations occurring daily, it’s also safe to say that some of your files should probably not be stored in the cloud in the first place. So, how do we do it well, and how do we get in the habit of doing it regularly?
Mantra: One Local Storage Backup to Rule Them All

I think the solution is a single backup strategy for all content, where everything is coalesced into a single location at regular intervals, and the backup process is performed on the agglomeration. To that end, most of my files are organized by subfolder and stored on an external hard drive connected to my local router. This is known as a NAS (Network Attached Storage) scheme and has been around for about 40 years. It was a great idea then and remains so today.
This is accessible to all my devices, essentially giving me the benefits of a cloud (well, more like a fog since it’s so close), but stored on my own hardware. I have folders for projects, work, taxes, and photos, among other things, with subfolders extending many levels below that.
Are Those Thumb Drives Current?

We still use thumb drives all the time, and make quick changes to the files, but then don’t delete the files, and now we’ve got a bowl full of thumb drives with folders of things that are slightly different from their originals, but we don’t have the time to reconcile the differences. If I assume that anything on a thumb drive already exists on my other devices, and that the thumb drive is only a temporary storage medium for file transfer, then I don’t feel so bad about wiping the contents any time I need a thumb drive. They do not get backed up because they are not the original source of the document.
I recommend you follow my lead. Thumb drives lack a sense of permanence by their very nature and should be considered a scratch pad for data, not a stone slate for archives.
Gathering Your Flock of Devices
I have a laptop, desktop, tablet, and phone, which means four distinct streams of devices that all need backing up. Some may have project files stored locally for when I’m not on my network, and synchronizing those projects with my main NAS storage is sometimes tricky.
At the new year I take everything that’s in my local desktop profile, and copy it onto the NAS. This leaves a vulnerability as the year end approaches and a year’s worth of work is not backed up, but it’s better than nothing. It’s hard to decide what gets put into the NAS; does everything in the user’s profile get moved, including installers for applications, the downloads folder, bash history? What about settings for services that are running on my computer?
I’ve been lazy here, as I figure if a catastrophe were to happen it would be an opportunity to restart from scratch rather than recreate an environment with years worth of entropy and old applications. For a business backup where running services and configuration may be critical this is a bad idea, but for a personal server where things are more experimental and temporary, it’s not so important.
Email: Preserving Contacts and Correspondence
Backing up mail is debatable, but important to me. So many attachments and writeups are sent through this medium, and saving the threads for passive-aggressive “see this email from last year in which I answered your question already” is satisfying, but there is also a lot of useless garbage that doesn’t matter within days, and dedicating any additional time or energy or storage to it is counterproductive. I use Thunderbird for all my accounts. This has the benefit of having local storage of all the email, including all my Gmail and other accounts. This Thunderbird profile is stored on the external hard drive, so backing up my mail requires no additional effort.
Domains, Repositories, and Social Media
For each of the web domains I own I can go to the control panel and download zip files of all of their file contents and databases. This isn’t as easy with complicated AWS setups where data and settings are stored across multiple services. I imagine it would be possible to set up “wget –mirror” to copy contents from the remote location, but I’d still need to capture the database contents.
 In an ideal world all my projects would be in versioned repositories, backed up to a git server, and the local copy would be complete. This makes it part of the local storage that is already saved. If you don’t have copies of those repositories, maybe cloning them locally would be prudent. Since all my projects are in my projects folder on my NAS, I don’t have any additional work here, either. It is, however, a good idea to make sure that across all your devices your repositories are up to date before backing up your system.
In an ideal world all my projects would be in versioned repositories, backed up to a git server, and the local copy would be complete. This makes it part of the local storage that is already saved. If you don’t have copies of those repositories, maybe cloning them locally would be prudent. Since all my projects are in my projects folder on my NAS, I don’t have any additional work here, either. It is, however, a good idea to make sure that across all your devices your repositories are up to date before backing up your system.
When Europe passed the GDPR, one of the requirements around the law deals with data portability, specifically calling for people to be able to download data concerning them. This has led to many sites making it easy to get a zip file with everything. Facebook allows you to download your own data, which works pretty well. You can only download your own photos, however, not photos of you taken and uploaded by other people. I wish there was a better solution for that. I want to save photos other people took of me; not to violate copyright but to preserve memories. I also wish there was a way to save my Hackaday.io projects. While all my original files are stored in my local project folder, the writeups and logs are not. Still, this is another category where the goal is to download a zip file of all the content and save it to the NAS.
Photos
Between Facebook, Instagram, Flickr, Google Photos, and iCloud, among others, we probably each have a good number of photos spread around the web. The trick is not just in downloading those photos, but also making sure you don’t have duplicates stored elsewhere. Fortunately, each has methods available for downloading your content. Tools exist to find and remove duplicate files, but with terabytes of storage on my drives, the effort of pruning the data so far has exceeded my need.
Aggregation and Storage
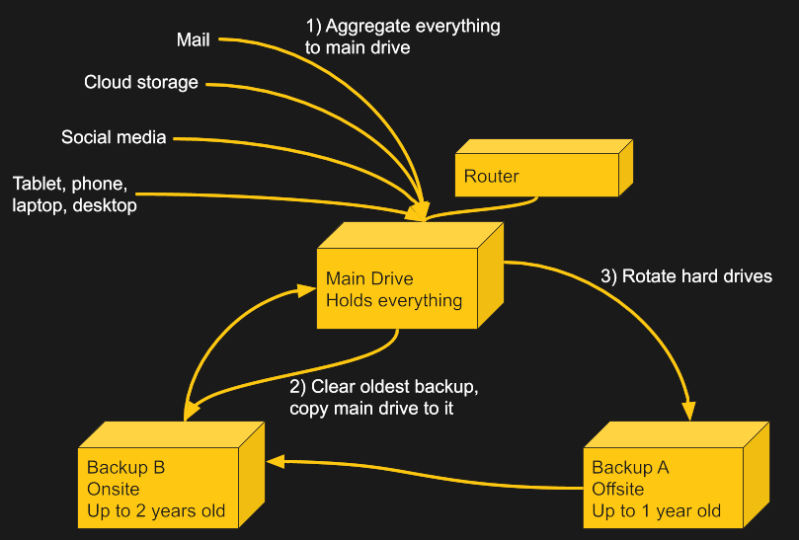
I have a total of three 5TB hard drives. One is for daily use, and two are the backups. One of the two is the most recent year, and is stored at a friend’s house. The other is from 2 years ago and is stored at my house. At the new year, I take the old one and erase it, then copy the daily one over to it and rotate the drives, moving the current one offsite, bringing the offsite one back, and turning the oldest one, which now has the newest copy, into the main drive. This way I always have a backup of my files that is a year or less old stored somewhere else in case of a local emergency like fire or flood, and one that is less than 2 years old in case of catastrophic failure of the daily and the external backup. I verify my backup by making the backed up drive my primary, which also serves to more evenly wear all of them.
Better Options?
They say a backup isn’t a backup unless it’s been tested, and I have only needed to look back on backups a couple times for missing files. But my solution isn’t the best. I know that even though I’ve captured everything (I hope) in the backup there are valuable things locked in a database file that would take a data archivist a long time to discover. My solution isn’t indexed or cataloged, and there are all kinds of duplicates, and things stored in strange places. It’s also time consuming, which is why I only do it once a year, and the later in the year before the next backup the greater the risk of data loss.
Some people swear by RAID for data redundancy, but that is NOT the same as data backup. We covered NAS options a little more than a decade ago, but things have changed a lot. What software tools or automation scripts make the process of downloading your special data easier or more efficient?
Creating a Legacy
A friend died recently, and there was a scramble to find photos and highlights of his life. It made me wonder what will happen with my legacy, which is primarily scattered across servers, condensed onto 3 hard drives, and difficult to search. I probably won’t be studied by historians in future generations, and curating my life’s digital content really only matters to me and a few people immediately close to me, so there’s a question of how much effort to put into this endeavor. Thus, in the beginning of the new decade, with so many more options available than when I started this pattern, I ask the community for suggestions on personal data storage and curation.














I’m really considering setting up a local NextCloud server on an old machine at home, using an external hard drive, and maybe considering adding Amazon Glacier for a durable, off-site backup of that. That sounds like a lot of moving pieces, though. Anyone set up something similar that’s working for them?
Nextcloud running on a linux box, which then backs up to crashplan for small business. Nextcloud sync works well for all my machines and the auto upload feature on my android phone works well too.
Highly recommended. Especially in a docker container with an external sql server in a different docker container.
I run a nextcoud box after loosing about 2 months accounts that I forgot to backup to an external hard drive. I could have used a cron job but nextcloud handles everything, and backs up my phone and home computers too, infact its proved invaluable. The most important thing to me is its automated, you cant forget what you dont have to remember.
I also keep another offsite little server thats synced to the nextcloud root folder so has a copy of everything.
I’d recommend it for sure.
I run a nextcloud install, and back that up with dirvish (http://dirvish.org/). The pre-backup script allows me to get the nextcloud server to do a mysql dump of the database before taking a backup of the full filesystem. It’s all locally stored at the moment (which is suboptimal) but getting a cross site rsync job up and running via cron shouldn’t be too hard, and there are open source scripts for pushing snapshots to amazon glacier.
Well…. There are only 10GB of files very important to me and 1GB of files ultra important to me. I am unmoved when anything rest is lost. This excludes project files, because they often reside in GitLab or similar place.
.
Most of my data loss be like, corruption root partition having OS, factory resetting smartphone, etc. These only consume some time at best.
.
Sometimes I lose photos & videos of a trip or occasion. But then, as long as I have the pleasant memory of it, it doesn’t matter to me if I lost it in digital format.
I’d say that’s a great time to set up Dropbox, OneDrive, and/or others. That’s easily within most online backup services’ free account limits.
TBC, those 10GB & my projects are well backuped. Everything else is one step away from hell’s door.
Meh, I love my backups but… What’s the worth of saving all this personal-ultra-important non-functional data. Maybe some intelligence in the far future will read it in bulk and analyse ‘ancient concious behaviour’. Or you might just keep it all stored because you’re a secret genius, ahead of its time, to be discovered by future AI.
And this only if your harddrive was one of the lucky ones to be preserved in those ultrarare coincidal circumstances in an anaerobic swamp.
Still gonna do my backups tho.
Just think if Pierre de Fermat had better backup than the margins of a book, or the Library of Alexandria burnable parchment.
I used to completely image my systems at home. Eventually I realized I only cared about a few types of data, so I put in a NAS and make backups to it. It has an app on board that syncs with Dropbox. I figure that any single event that destroys all three will leave me with much more immediate concerns than data recovery, assuming I survive it myself. :)
I don’t want to discourage backups and all. I’m just here to tell that there are people like me who never bother losing data. (BTW, I still backup those 10GBs & Projects)
I’ll say it, I absolutely cannot trust cloud services, even after ignoring the privacy perspective.
If a server is not managed by me, or is in the physical vicinity of me, I expect it to have the luck of Irish. I cannot trust any storage medium that I cannot hold in my hands. Sorry, that’s just how it is for me, and as i imagine, a lot of like minded people.
I really wish this technology would make its way to consumers soon, so that I do not have to keep buying harddrives (or spinning rust as the youngsters call them) to pacify my hoarding needs.
https://en.wikipedia.org/wiki/5D_optical_data_storage
Just code all of it in your DNA so your descendants can enjoy it too.
Get some extremophiles from a volcano vent or somewhere, code wikipedia in their DNA, shoot them to Venus, then the visiting Aliens or subsequent Venusians in a billion years, will know about what went down on planet 3.
Some of the wisest words said: “remember that the “cloud” is really an HP server somewhere in Tennessee with a dead power supply and a degraded raid array”
I worked for a few years at a three letter storage company making very expensive backup appliances. The kind very large banks buy lots of in case planes fly into their primary data centers.
So, I totally get your paranoia. I have seen the most obscure Byzantine data corruption bugs.
But, I will tell you that unless you can validate every part of your storage stack down to the behavior of specific scsi commands, you’re no better off than outsourcing your storage to the cloud. The controllers on spinning disks and FTLs on flash drives are extremely complex beasts often running full RTOSs which you have no insight into. Then there’s the disk controllers, cpu north bridge firmware, memory controller magic, and then you get to the kernel where even then you need a level of aptitude for storage devices and stacks that isn’t common among your standard kernel developer.
All that to say, the only backup that matters is the one you can get to and verify your data. And no one has lost their job backing up to S3 as far as I’m aware. Food for thought.
The only catasstrophy recently, windows 10 failed to recover from sleep mode, suggested I click repair, and it erased the entire drive.
One TB of pictures lost, but the thumb drives saved my bacon.
There seems to be a glitch with Win10 regarding that right now.
We had drive A and drive B. Both store data and are not the boot drive. A was in the computer during Win10 install. Computer was shut down and A was swapped for B. Win10 was booted back up, and before it even got to a login prompt, the following took place:
-Win10 recognized B as being A
-OS wrote cached data from A to B, corrupting it
We log in and check the file explorer, and it reports that A is still present. Even see some of the contents from A inside.
It’s not until we go into Device Manager and scan for new hardware that Windows 10:
-Realizes that B is not A
-Tries to mount B
-Detects that the drive is corrupted
-Attempts to recover the drive
And poof, 90% of the contents of B are gone. It took us two corrupted drives before we figured out what was going on.
I was reluctant to move to Win10 before, I’m sure as hell not doing it now. This is precisely why I specify all my partitions by UUID in fstab under Linux.
In case anyone is wondering, it was a proper “please shut down my computer” shutdown.
The concept of a complete shutdown just seems to have been abandoned by Microsoft in recent times, in favor of faster boot times coming out of partial hibernation.
“You wouldn’t change anything inside the computer we built for you, right?”
Ah, yes, Shut that puppy down.
After my poor Windows 10 sleep performance, I decided, “Failure Is Not An Option”.
I changed all options to “Shut Down”, as (power button) (close lid) and (Sleep button, Do Nothing)
Haven’t lost anything since.
As to the cloud, yes, it’s just a server somewhere not local. Admined by an ESL student intern.
Just read about a “New” cloud backup company.
Named for a Japanese condiment. Wasabi.
The claim to fame is “We Invented A New File System”.
Seems like 4k blocks were too space intensive, so they dropped the concept.
I assume the customers are on a “No Need To Know Basis” as they don’t explain much.
Blocks on ssds don’t mean anything. They’re doing FAST style tiering anyway between nodes.
https://www.usenix.org/legacy/events/bsdcon03/tech/full_papers/thorpe/thorpe_html/index.html
tynipic.com closed in 2019
I always found it odd that hackaday.io wasn’t based on a git repo. Something to consider.
I went through this exact process a month and a half ago, when one of my 2 TB hard drives suddenly got a corrupted filesystem, and of the two 2TB backup drives this one had all my documents and photos.. I bought a 6TB Seagate external and managed to recover maybe 80% of my files, but now I have a larger external drive with which to potentially lose data to corruption with :| What makes me feel really stupid about this whole episode though is that I work in IT, and have had numerous clients lose data to user error or catastrophic failure, and my answer to them is alwayss the same – “I assume you had a backup ?”, which they never do…
In the early 1990’s my workgroup bought its first 1GB drive (IPI format?).
We were pretty excited about how much data it could hold and we wouldn’t have to “hang tapes” to retrieve the data when needed. Then it occurred to me how much data we would “lose” if the drive crashed.
Having suffered a few data loss events, I finally decided I’d had enough and started being good about backing up my data. While I like what the author is doing here, I think there is room for improvement. Some thoughts on how I do it:
My main issue here is how much depends on manual work and remembering to do things (also, the REALLY long times between swapping hard drives. Do you really want to lose a year of data?)
Rather than a router with an external drive, an old Linux server offers more flexibility and can be built pretty inexpensively. All the computers in the house use the shared drive on the server as their main storage, and anything local to the machine is automatically backed up to the server each night. The main benefit of running a server over a router (for me) is being able to use ZFS which makes data loss detectable and in many cases correctable, and it can take snapshots of the current content with almost no overhead. Snapshots let me recover from deleted files, unintentional changes, and even ransomware. If possible, include redundancy in the drives so a single hard drive failure doesn’t result in any data loss at all.
I set up a second server (out of a bunch of old parts that didn’t cost much) and put it at my office. It connects back to my main server once an hour grabs any changes using ZFS to efficiently send only the changes, these updates don’t take long or use much bandwidth.
This was more work to set up, I imagine, but not a lot, and probably cost more, but not that much, and results in a backup strategy that is totally automatic, and will never lose more than an hour of data (and then, only if my house is destroyed) I’m very happy with it!
Yes I wouldn’t really trust the router not to mung the disk at some point, or have bugs that leak the whole thing to the interweb at large or just a few blackhats in particular, state sponsored or private enterprise. At most I’d use it as a backup aggregator, something you collect up the backups from a dozen machines/devices on and commit to something safer every week or so and remove from that. Public files you want to continuously share are probably fine though.
Openzfs + random hardware == data corruption.
If anything openzfs is particularly picky about ram type, and also he likes it very much.
So for 8TB of backup storage openzfs reuiqres minimum of 8GB ECC ram.
I can not stress enough of the ECC part.
Store all your files on Microsoft OneDrive. OneDrive is perfect for everyone!
It indexes your files, backs up your files, and makes them available anywhere, all for a small monthly fee!
Never mind that you are paying for the bandwidth, both ways, and we get to see everything on your PC to confirm you are genuine, and can disable your OS at our whim, it’s a small price to pay.
Your files are our files. Your disk space is our disk space. Your cpu, is our cpu.
We also do a complimentary scan of all your files for:
viruses
illegal files
child porn
content we can use and profit from.
never mind the small amount of false positives. the onus is on you if we do something incorrect, we certainly can live with that!
Exercise: Replace OneDrive with GoogleDrive, iCloud, Dropbox and so on => result is the same.
The question is, why 99% of people keep insisting that it is not the case? One thing is to admit it but take the risk believing it is under control (it’s not), and another is plainly refuse to believe that once you give control away, you are somehow still in control, because reasons and companies wouldn’t do that.
Use Cloudberry backup in two stage mode. It automatically first backs up compressed to a local drive and then to the cloud of your choice encrypted with a key of your choice. I backup to a USB 3 4TB drive then to Glacier. You set retention times, it does block level incrementals, it automatically deletes expired backup data. I’ve tried them all. Cloudberry is far and away the best. I’ve been using it for over two years. Rock solid reliable. I can restore deleted or previous version of files quickly from local and have disaster protection of cloud. It also recovers from dropped internet connection and resumes. It’s well worth the cost. I’ve restored random files from Glacier to confirm reliability.
Hey!
I hadn’t thought of keeping all my thumb drives in a bowl!
Thanks for the idea!
Heh, I thought “Bit of a random object to throw your flash drives in” for 2 seconds, then it dawned on me that the random plastic thing that I throw my random use drives in probably also fits the the description of a bowl, derp.
They are a bit of a pig to store in a tidy/compact fashion, because every 6 months or so you go to buy a new batch, the case shapes have probably changed. Bowl at least lets you furtle around and grab one out easy I guess. Mine somehow just gravitated towards my random plastic bowl thing to stop them sliding off the desk.
However, would be desireable I think to leverage the one common dimension they all have, the USB plug, and cut holes in high density antistatic foam to receive them, with decent spacing to let fingers grab and take account of case weirdnesses. Then what? Cookie tin? IDK you’ll get opinion split on “perfect” protection and what’s easy to keep on your desk and get into on a regular basis.
Yet another idea. Live in a rural gated community that is sparsely populated (about 50 houses spread over 2500 acres) with only satellite or RF ISPs. No phone, sewer, or water mains – power is the only infrastructure. Our local group of four houses is connected via a WAN/LAN setup, with two routers and servers connected to an RF data link as our ISP. Each house has an encrypted hard drive that mirrors the three other houses drives. And each house has a data server for their own local daily backups. Our main hazards, in order of likely occurrence, are wildfire / data corruption / lightning / earthquake (power loss is minimal issue because our solar systems all have islanding from the grid). We are experimenting with rotating hard drives to a site several miles distance, but are concerned with the site’s commercial stability.
Another backup story. Wife’s employer had a double whammy last year – Ransomware + power surge roasting servers and some desktop machines. She had bought an external drive that gets backed up every time it is brought home, and her company laptop gets backed up every night at home,then the laptop HD is ‘wiped’ to minimize space issues. We have no idea what her employer’s IS minions are doing, as they has no usable backups after their dual disaster. When my wife indicated that she had copies of, they demanded the external drive. I sold the external drive to them for $1. The encryption key cost them much more, and the other stuff on our community’s servers will cost them even more…
Set the wayback machine to stun.
A clever engineer decided to save a ton of money, and ran a fiber cable on the ground from a power gen station, down hill to an existing office. About 2,000 feet, over bushes, in culverts, etc.
I took two days for the local vermin to chew the cable to pieces.
We repaired the damage, installed conduit, and eureka, it worked again.
Yes, the repair came out of maintenance budget, not construction.
That’s how they roll.
I just went off the deep-end on this one and got a used enterprise SAN solution. An HP fibre channel p2000 g3.
It is massive overkill, but all of my data will be aggregated into multiple tiers of a single storage network.
“Irreplaceable” data will be mirrored to another onsite NAS and excrpyted, and then weekly uploaded to backblaze B2 or amazon.
“Important” data will just be mirrored to the second NAS.
And then “Bulk” data will just sit on its own RAID array. It will have parity and snapshots, but not a real backup.
I still have things like family photos on an offline medium. DVD at the moment because I like the permanence of m-disc, but I have been reading that the archive blu-ray discs are also extremely stable so I may be moving to that so I only need to burn a single disc.
The lady next door has a two TB NAS, so I hooked up my backup into a hidden folder over there.
She’ll never know..
Plus she saves all her snapchat pix there..
;-)
Recently had ransomware and I went about improving my backup system. The biggest piece of the improvement involved splicing in a small relay to the +5V wire in a USB 3.0 extension cable to an external drive. Relay is controlled by an analog outlet timer. So at a preset time during the week, timer turns on, relay closes, drive shows up, free file sync runs, backing up files and then scripts eject drive and the analog timer cuts power. Have a duplicate drive at an off-site location I visit frequently to swap out pretty frequently.
Works great until the one time the backup doesn’t finish in time, because software is fun like that.
“Oh, you were writing to the main filesystem table? Oops.”
I don’t trust the cloud, this is what I do.
Most important files (stuff I have created, email etc):
Use FreeFileSync to copy files to my server if I done some work.
Every few days I sync this stuff to a flash drive (Veracrypt) that I always carry with me.
Stuff I don’t want to loose (software, music, videos etc):
Every week or so I copy to a big USB hard drive. Drives are normally off.
Every month or so I sync my USB drive to another big USB hard drive.
The photo at the top shows a WD MyBook storage device. I don’t know about recent models, but the older one I own had a proprietary partitioning scheme. If the device failed and you removed the drive and plugged it into a desktop, it couldn’t be read. I know at the time some other brands of external storage gadgets used things like proprietary SATA connectors or soldered connections and other wonky things. All these things mean you are dependent on the gadget not failing since you could not likely recover the drive contents even if the drive survived.
If you are going to get an external drive solution for backups, make sure you get a generic drive case and generic hard drive, even if it means paying a bit more than some proprietary option.
I don’t know if I was just unlucky, but of the two drive failures I have had over the years (excluding occasional “click of death” zip drives late last century), one being a desktop 3.5″ drive, and another a 2.5″ usb connected drive, both were WD, and both seemed to be controller related. I tend to go for seagate or toshiba now.
I’m starting to see a lot of failures in early 21st century drives, pre 2010 say, higher than 90-99 era, and yes, the controller has gone bonkers, but seemingly from bit rot in the flash firmware.
WD MyBook or Easystore don’t work when they get 3.3V. I don’t know why. If you want to shuck the external drive for use as an internal, you can clip the 3.3V wire going to it. There’s a couple other cleaner solutions here: https://www.instructables.com/id/How-to-Fix-the-33V-Pin-Issue-in-White-Label-Disks-/
I am using rsync for nightly back up of my project files to a USB drive on my router. The Tomato firmware I like is no longer updated, but a different person have picked it up. This is the 2nd time that this has happened.. It is kind of a thing in the open source world for small hobby projects. So the moral of the story is that relying on router might not be the best long term strategy. I can’t avoid keeping up with updates for security reasons.
Sadly, the new firmware for the router no longer shows the drive as a share SMB device for easy retrieval. The backup is still being made, so a retrieval is still possible but much less convenient.
I always get a chuckle out of this kind of noise:
With the risk of data leaks and privacy violations occurring daily, it’s also safe to say that some of your files should probably not be stored in the cloud in the first place.
The on line backup system we used to use encrypted everything with AES before it went over the wire. The only fly in the ointment of course is you can lock yourself out if you loose the key. I crack up because people are worried about someone sneaking a peek at their porn collection and won’t use the same on line backup system their bank probably uses. If the encryption a good on line backup service gets broken, you have a lot more to worry about than your porn collection being spied upon.
Did you say that with a straight face, 2 financials and 1 health services company that I previously dealt with have had to send me a “maybe you were in a data leak” letter.
It’s a moving target, at the moment I use a cloud service called Mega.nz. First 50G free. This shares folders between devices, one of the devices is a Raspberry pi. It’s job is only to hoover up the files and periodically do a local backup to a non cloud folder. This pi backup machine can be duplicated as many times as you like, and anywhere on the net. This provides simple sharing of ongoing work, and a backup service.
Sound plan, putting 100% reliance in an entity that DoJ and FBI have a boner to take down again, whether they have to plant the evidence or not, because they didn’t get satisfaction last time.
All data is stored both locally and in NZ. Also, from the previous encounter Kim. Com has learned the value of end to end encryption. Plausible deny ability. Something the others have yet to learn.
I turned my old PC (built 2013 or so) into a nas with a software RAID 5 array, so everyone in the house can save files to it. Admittedly RAID 6 would be a much better option but windows 10 can’t do software RAID 6. When the time comes to replace that box I’m thinking of going with ZFS RAID Z2.
I find that an HP “Workstation” class tower, ships with hardware raid. (Z800)
Comes with two drive controllers, SATA, and SaS.
Hot swap of course.
< $200.00 most days from surplus vendors.
The last one I grabbed was 48 gig ram, 2 TB drive, DVD, Win 10 Pro Dual Xeon quad core @2.80
That should be enough for a NAS.
I have 1 TB HDD in my PC as a backup, 2nd store is a NAS running Xpenology in a garage and 3rd is a old HP thin client running Debian which powers on weekly, opens VPN to a NAS a do rsync of all required folders. HDD and NAS contains similar data, but offsite includes only private/important data (photos, private videos, DB backup, websites I’ve created).
Day the Data Died
https://www.youtube.com/watch?v=CKnMNjh9Z6I
Loose Bruce Kerr
Empty PC
http://www.daveross.com/emptypc.htm
Dave Ross
For ‘small’ amounts of non-changing data, flash drives are pretty good, no? (I haven’t actually looked at how long before bits start to fade…)
Our family keeps some super-critical documents on flash drives, and we all pass around copies when we get together (few times a year) if anything’s changed. Will, copies of deeds, passwords to bank accounts, etc.
I understand Bob’s reluctance to trust a mobile medium to serious duty like this, but if you label the drive clearly and put it in a super-safe place, I think it’s a good solution for the most important, and least volatile, data.
All my personal stuff, I have a local RAID backup that I fire up once a week, run an rsync script on, and hope for the best…
About 8 years ago, when the “CDs go mouldy, flash drives are MUCH more reliable than they used to be” noise was going on, I tried using an 8GB Verbatim flash drive for daily work, bookmarks, documents etc.. and killed it in 8 months. I didn’t think I was even writing more than a dozen things a day to it, and only deleted the odd thing, but I’m guessing autobackup of office docs and other progs that do similar, might have been doing more like a 100 writes/deletions a day. Still, it seemed far short of the 100s of thousands to millions.. of cycles the flash industry was touting at the time. I haven’t had a “mouldy” CDR/DVDR yet.
So that has made me a bit nervous of them, particularly leaving backup drives plugged into windows machines that might write indexes and thumbnails to them unbidden.
I do use them as part of a multiply redundant and easily accessible backup, but I make a point of not deleting stuff off them for trivial reasons, and using file transfer rather than letting applications write to them.
I guess really my backup strategy is a bit of a mess in general, there’s a core of “important stuff” that gets onto DVDR, flash, and multiple HDD, but then there’s a lot of “work to find again” stuff that I maybe only make it slightly less work to find again, zipped up and spread around the network somehow, and dumped to removable storage sporadically.
I’ve got a whole media collection on DVD-R or similar, and probably half the files have bad spots, and maybe 15-20% are unplayable. They’re only 10-15 years old.
In `98 I backed up a HD to 32 floppy disks, and one disk was already bad 2 months later.
“All my personal stuff, I have a local RAID backup that I fire up once a week, run an rsync script on, and hope for the best”
I like to go the other way and keep the accessible copy on RAID, and backup just on a disk. But rsync has a lot of advantage IMO, I just love it.
Others commented something similar, and as a personas that has greater will to test new Linux that hability to handle them, after two mayor incidents with hard disk that asked for full formatting and reistalation if the OS, I use Dropbox. Well contained process, save my data and now complies with european data law, very importante in my work.
Only thing is… If the device is always on, is it really a backup…. My setup includes a NAS device, however, I have the rule of 3, with one on-site backup, one off-site backup, and cloud backup (all encrypted, and per my cloud service, there drives are all backed up)… This setup is not the cheapest, but with all photos going digital, some things you just can’t replace (family photos, videos, etc)
This is what my workplace (VRT Systems) does:
– The file server takes responsibility of gathering all the data for a system back-up, scheduled daily.
– We use BitBucket for git repository storage: a script updates a local clone of each and every git repository, this is stored with our other to-be-backed-up content. This script uses the BitBucket API to pull a list of current repositories so that new repositories are automatically added.
– The file server backs up a list of local directories to a dated destination directory on an external (USB3) hard drive. This is done using
cp -alto hard-link clone the previous copy, then usingrsync -aHAXP --delete-beforeto update the clone with the latest content.- Symbolic links to the "previous" and "current" back-up are replaced.
- If the day is a Sunday, the back-up is tagged as a "weekly" (a file named WEEKLY is
touched)- If the day is the first day of the month, the back-up is tagged as a "monthly" (a file named WEEKLY is
touched)- The contents of this new on-site back-up are pushed to two "NAS" boxes using
rsync -aHAXPrunning through SSH. One of these back-up boxes is on-site, the other VPNs to the workplace and lives at the house of the managing director.- A clean-up script deletes old back-ups so we have a certain quantity of daily, weekly and monthly back-ups.
Does this work? Pretty well! A few years ago we had one person's laptop hit with the CryptoWall ransomware. He didn't report it to us until about a month or two after, during this time the malware had connected to network drives and tried to encrypt the whole lot, including a not-backed-up directory of virtual machine images.
I was able to recover nearly all files encrypted from weekly back-ups. The half-dozen files we did lose were some VMs for mine sites that had long expired support contracts, and thus were not of great concern to the business.
Forgot to mention, a separate cron job runs twice a day to snapshot servers’ configurations and stash those on the file server for disaster recovery. So it polls a list of servers, running a script on each to prepare a back-up of that server, and pulling that back-up back. It gets stashed in a place where the above procedure will find it.
> If the day is the first day of the month, the back-up is tagged as a “monthly” (a file named WEEKLY is touched)
Of course I meant “a file named MONTHLY”… serves me right for composing this before 6AM without the influence of caffeine.
I don’t like to delete things. I’ve looked into cold storage, but it seems my yearly expenses would let me buy a new server every 3 or 4 years, so I opt for running two servers instead, and let them run until the oldest become unreliable, then I will buy a new, throw out the oldest and dedicate the next-oldest to mostly-cold backup.
I’ve got two machines in two different locations, one is a “current” machine, it’s got 9 x 5 TiB drives in raidz3.
It scrubs automatically once every other month.
It’s hosting my openvpn installation, and providing access to the files via samba and ssh.
My computers mostly access it via cifs over the vpn.
The second machine has 10×3 TiB drives in raidz, it is usually disconnected.
Once a month I hook it up to the internet via a fiber NIC and power it through an ups and a dedicated surge protector in front of and after the UPS, then I do a backup using the rdiff-backup package, twice a year, I run zfs scrub.
RAID1 keeps the current copy online when a single device fails. It’s not backup because it doesn’t stop `rm -rf` but still very useful because no restore is required when a device fails.
Use ZFS snapshots for backups. Snapshots are incremental, so you can use daily snapshots going back 3 years without requiring 1,000 times as much storage as the current copy. RAID1 for the zpool as well obviously.
Use cron and rsync to back up automatically at 1pm for workstations and laptops (when they’re on and present but you’re having lunch) and 3am for servers (when customers are asleep).
I have a home Linux ‘data server’. Never will trust or put stuff in the ‘cloud’ unless it for a ‘temporary’ purpose. All important ‘data’ is located on the server. It is also not directly connected to internet unless I manually connect it to do a quick OS update. Then disconnect. I don’t have to worry about my Linux laptops and Linux desktops being ‘backed up’ as the ‘data’ is all on the server. Therefore I can wipe laptops and workstations at anytime. Note that I do periodically backup to the server the /home directory on one workstation as it holds our email and web browsing favorites etc. (yes, we ‘download’ our email, and don’t access/hold it ‘in the cloud’). Then periodically (manually) backup the data server to multiple external usb HDD drives when I feel it is necessary. Every January, I do a complete backup to a new usb drive and store off site. Sometimes, if new data is really important (say wedding pictures), I’ll make an off-site backup during the year. Simple as there will always be a backup somewhere.
That’s what I do, and it works for us.
If there less than 2 backups, there is no backup…
One server/NAS for everyday, + two 4TB external disk freuently, one here, the other in another place : the house may burn, but my files will survive ;-) + some scripts using rsync (and of course git for text versioning)
I really need to update my setup. Currently running two “nas” servers, one is a original model raspberry Pi with a 1Tb drive.. the other is another single board computer running windows 10. Using outdated SAMBA to share the drives between each system and bash scripts and Rsync keep them synced together. I even have scripts that send me SMS messages if either system doesn’t see the other. So far it has worked out great. I simply store my files on the windows 10 box, and they get copied and mirrored nightly. But the system is too old. The samba it uses is not recognized by modern windows 10, and it has been so long since I wrote the scripts and set up the file shares, that I don’t think I could even remember how to do it all again. I am thinking about going with off the shelf NAS boxes next time and maybe only using a Pi to run scripts to keep them in sync. But, I can’t decide on what kind of storage to use. Spinning hard drives or ssd drives.
Several years ago I lost my primary hard drive. I recovered with a 6 month old backup. I’ve implemented the following so that I’ll never lose stuff again.
Desktop PC (all drives encrypted)
– Primary Drive – Two 1TB NVMe drives mirrored
– Amazon Sync Drive – Two 1TB SSD drives mirrored
– Backup Drive – 2TB SSD
– Primary Drive backs up an image to 2TB Backup Drive weekly.
– All phones backup photos and vidoes to Amazon Cloud Drive, plus all of our family photos for the last 20 years are stored there.
– Amazon Cloud Drive syncs to the Amazon drive on my local that is mirrored.
– All drives on my PC are backed up continuously using Backblaze Unlimited Backup.
Timeshift on Mint let me recover once from an unfortunate incident, but I could also have just reinstalled and it would have taken less than an hour. So I’m not sure it’s worth it to backup anything but my data. I also wonder if I’d remember how to run the backup software on my wife’s PC (which does incremental backups and stores in a proprietary format). So I tend to just copy and paste my whole /home periodically.
Where Timeshift came in handy for me is when I tried to upgrade a Linux Mint system. Went badly, but with Timeshift I was able to get back to where I was in just a few minutes. So if upgrading a system, I’ll use TimeShift. Otherwise I just use straight rsync for backups of data. Never the internet cloud though for any backups.
I got my student gmail account from years back which gives me unlimited Google drive storage and I also got several student MS accounts which gives me a few TBs of storage. Anything that I upload to the ‘cloud’ is first encrypted using 7-Zip. It would be nice if I had a nice 1Gbps upload, but sadly I don’t. I of course also keep local backups.
i just cut out potentially trillions of years of entropy and just delete it now. i do yearly data culls in order to keep things manageable. i figure ita about 90% pirated “linux isos” anyway.
DVDs for me: no chance of lighting strikes or virus that can wipe them out.
I have 500GB is family photos videos.
I still have CDrs from 1990s that are still good too but now I back up via 2 copies to different brands of DVDs.
Also, I put copies on old hard drives and give them to a friend for off-site.
(I don’t trust USB drives at all. I don’t want my stuff in the cloud.)
good luck finding drives to read them. one day i had a situation where i needed a dvd drive, and i had four laying around. they all worked last time i used them. but all for were non-functional. i even tried them in different computers/external enclosures. so i did the only thing i could do, wave off the situation as unsolvable and scrapped the drives for parts.
Your secondary backup is a year old? I wonder how that’s going to work for you the day you need it.
After a data loss I got really conscientious. I have three 5tb external USB drives, two located where my laptop spends most time, one in an alternate location. The two in the same location use different backup software, the one in a remote location uses the same software as one of the local drives. These are backed up weekly. In addition, BackBlaze cloud backup syncs every night. (I have metered satellite internet with an unmetered period from 3AM to 6AM, so that’s when Backblaze calls home. Otherwise it would backup continuously)
Local RAID1 Linux server backed up daily to a well known cloud service. Backups encrypted client side because I only trust the cloud a little bit.
I’m only in trouble if I have a dual drive failure and my cloud provider goes out of business on the same day. Or if I lose my keys :)
Or you have a power-bump that corrupts one half of your RAID1, which takes it offline, and oh whoops it contained your crypto keys. Can’t restore your backup now…
Nah, extra copies of the keys elsewhere.
Considering the download throttling of cloud providers, you might be SOL if it happens in the same few months.
I picked up an old QNAP TS 209 NAS for cheap and installed a pair of 2TB drives. I’d like to be able to use it to serve video files so my Samsung TV can play them from it via WiFi link to my LAN instead of having to copy files to flash drives.
Someone told me how to install SMB 1.0 support in Win 10 (after plenty of others said essentially to just spend hundreds of $ on a new NAS) so now my computer can *see* the NAS but I’ve not yet been able to gain access to put files on it.
I’ve never put my only copy of anything on a “cloud” service since having my ISP (Cyberhighway) get bought by another (Fiberpipe) and having everything go *poof* on the eve of Thanksgiving back in 1998 or 1999. Fiberpipe had continued business as usual for Cyberhighway customers (*stabstabstab* Nothing has changed, only the name of the king!) everywhere except in Idaho. For here they sent in a crew to shut down and cart away everything from Cyberhighway’s op center, leaving behind one guy with one phone to answer all the pissed off customers.
At the time my sister worked for Domino’s Pizza. She got a call to deliver a pizza to the Cyberhighway office and a request to find out WTH was going on then call the guy back. The lone guy at the CH office was glad to have the pizza, and happy to tell my sister WTH happened.
Do. Not. Ever. Trust. The. Cloud.
1. I forget its name but it finds duplicate files (first by hashing, then by bytes) and will hard link them on a big disk. So the Thumb1 through ThumbXfer won’t take duplicated space.
2. the 3-2-1, three copies (original is the 1st) in different places, 2 media, I forget the rest. I usually use SSD for images and have two Amazon lightening 8Tb drives from different vendors. I swap between the one in my storage unit. Gather your disks, and the old stuff put in Amazon cold storage. OR see what magtape is capable of today.
3. Spinrite, or at least dd if=/dev/disk of=/dev/null monthly.
I haven’t thought of encrypting things and adding it as metadata to a series of 0.00001 BTC transactions on the blockchain…
There is also MDISK multilayer blu-rays. EMP and magnet proof.
I’ve though about a pair of Drobos…
SyncThing can be your friend here. At least over the LAN if you can run it to your (not attached) garage.
Not mentioned in the article is if the cloud storage has your (not well or at all encrypted) backup, what happens if there is a subpoena or worse. The IRS might be curious about your double book entry keeping. Or do you really want THOSE pics…
“. I forget its name but it finds duplicate files (first by hashing, then by bytes)”
Cheese?
Nope, that wasn’t it,
how about fdupes?
My solution so far is a Synology Rack Station in the small server rack in the closet with 4x 4Tb drives.
My laptop has a small Synology system tray app that backs up selected folders automatically with files being stored with a 5 version history.
My phone has the Synology file station app and backs up my photos and videos etc from my phone automatically too.
The next step is to purchase the 4-bay expansion unit for my NAS and fill it with more drives (some will be upgraded to 8Tb at the same time, the 4Tb drives are getting full now) to provide drive mirroring capability.
And last step is to find a secure, private and decent offsite storage service that isn’t Dropbox, Microsoft, etc and isn’t too expensive.
Back it up on-site to something redundant and again off-site for any definition of that you’d like. And on some write once permanent media if it’s necessary for business.
If all that burns I’ll just write it off. Food and shelter are important; everything else I can re-create.
You may want to “google” the term “Bit Rot” if you use write once media for archival data.
this is why we have par2.
Take a look into reddit subs:
/r/DataHoarder
/r/selfhosted/
Several years ago I did my Hackaday Prize project on this – the idea was a stack of:
* freebsd
* zfs
* rsync
* little web interface
main software on a CF card or similar, an entire (big) second drive dedicated to the storage. It was called “BupBox”… but I got bored and moved onto other things. Maybe I should get it back out of storage.
https://hackaday.io/project/1164-bupbox-backup-software-and-two-test-pcs
You can never have enough backups! I have three computers and two laptops in my home. Two computers perform backup duties to their own RAIDed drives and onto removable standard 3.5″ SATA drives. I have multiple removables that get rotated. The backups to the drives are made with “rsnapshot” and with multiple snapshots per drive. I should probably also mention that all my systems do run Linux. So this solution probably won’t work for win users. But it would on macs.
As a side note: I’ve also rooted my Android devices so I can backup my critical apps and data, which also gets stored on the server and backed up to removables. The truth is that their usefulness is limited. I don’t have much data to lose if one falls in a lake. Its the apps that I desire to keep the most. As I have them frozen at the best version for me. Its amazing how so many improvements take away usefulness.
I have considered cloud storage for backups. The only way I can see that working is to make a tar ball and encrypt it (OpenSSL | GPG | or my own code) then store the results on the cloud. The cloud service would then have no way of getting into it short of a highly targeted and advanced attack to get my key.
For me that would be the easiest way to have an off-site backup in case of local physical disaster (fire, volcanic eruption, …). But the upload time would be way too long. So for now I content myself with knowing that I take a drive with me when I go on vacation and when/if the sheriff knocks on my door to have us evacuate I grab the last backup from the server on my way to my rig.
I decided to split my NAS into a portion that’s the collected and cleaned archive, and one holding the regular, automated backup of my portable devices.
It was originally motivated by an unusual SSD failure where all files were accessible, but many old ones were silently corrupted. I don’t want such files being synced back to the main NAS storage and silently working their way up the backup chain.
It works out that if a device gets stolen, then I have a recent copy of it that was automatically made. Anything that’s important enough to keep I copy over to the appropriate place in the archive manually when I know it’s good. Because both are typically on the same device it tends to be quite quick.
Then when I take backups from the main storage, I plan to be doing it with single drives formatted with ZFS. The data is check-summed to detect corruption while in cold storage, even if there’s to redundancy in the backup itself.
it is checksummed but you need to have redundancy for “repairing” the files, it checks the checksum and if its bad the file get swapped from the redundancy.
I would go for good ECC Ram as well as HGST HDDs. You find lots of useful information on reddit. On the freenas forum there are a lot guys showing off their build, saying that if you can’t max out gigabit connections it is not worth it.
There are a lot of cheap old servers that you can use, some even bring IPMI.
I worked for HGST for a while, they made a trade-off of capacity for reliability in their products.
In this case I don’t care about repairing files. I only want to know when a given backup is bad. At that point I grab a different copy.
I do use (plenty of) ECC, but that is completely unrelated to my backup strategy. As for fancy hard drives, I don’t have the money for that. I just build as much redundancy into the main array as I think I need, and update/check cold backups regularly.
As for performance, I literally couldn’t care less. I’m running 100Mb/s links on some of my machines and my NAS itself is built using an old Athlon chip. The advantage is that it draws less than 30 watts, hard drives aside.
I use a ZFS machine with freenas. The problem with raid5 is if your system dies (surge, systemcrash etc) and parity data is beeing written, you can loose all your content. ZFS even error correcting itself. There are settings that the same data does not get saved twice physically so snapshots do not take that much space. I run a raidz2 on there so 2 disks can fail the same time without loosing anything.
With freenas sharing data is also really easy and the settings take maybe 1 minute.
I use syncthing, time machine and genie timeline for automatic backups and have 2 cheap dedicated 2tb roots that have a backup from the most important stuff in two locations.
I lost some data when I was 15, I put so much efford in it to organize it and than poof gone. Almost like a family member dying.
I set something up recently for myself. It might be a bit crazy, but works for me.
I have a lot of video footage for a YouTube channel I work on, and that footage gets updated every week or two. I’ve also got all my personal photos/video/projects/etc.
In my main Linux desktop I have a few TB worth of storage and use SnapRAID for local redundancy. I then have an old PC offsite that does a nightly rsync pull of that large storage pool. The pull seemed important to me so that if my main machine got infected by something I clicked on it would be less likely to get access to my backup server. The rsync script uses hardlinks for files, so I’m able to keep several versioned backups of all the files. I then also use SnapRAID on that machine (with a bit less redundancy than locally) to make any drive failures easier to recover from.
It certainly isn’t perfect (online backups are more vulnerable to wear and attack, SnapRAID is optimized for larger files over quantity of files), but it means that I should never lose more than a day or two of data in the event of anything short of a meteor taking out my city.
I use a Linux NAS running ZFS, everything gets backed up to that, and then that is backed up via CrashPlan. I have survived several data loss events with this configuration, including a power supply failure that cooked all the drives in the NAS.
How does that work, if the NAS drives are cooked?
(and please don’t answer, “just fine, thank you!”)
B^)
How do you write an article about data retention and not mention zfs? On a “hacker” website. For reals.
Things you need to know about:
– end-to-end checksums will detect+correct silent corruption by your drives or cables
– no losing a whole stripe if one drive has a corrupt block (RAID5 checksum error: discard which block?)
– no RAID write-hole => no need for battery-backed caches etc. Use plain old drives.
– multiple redundancy for arbitrary N-of-M storage
– low-cost snapshots in unlimited quantity; go back to old versions of any file
– transfer block-level deltas between storage, i.e. instant and perfect incremental backups
– compression that *increases* your throughput even on SSD, and hugely so on spinning rust
– much better in-memory caching (ARC) than other filesystems
– caching from SSD (L2ARC) for large multi-drive volumes
– journal to SSD (ZIL) for fast synchronous writes to large multi-drive volumes
I have a big zpool (5 of 6TB in RAIDZ1) in my main machine. I incrementally back it up to an offsite zpool (12 of 2TB in RAIDZ2) that lives in my desk-drawer at work. I bring the backup array home every couple of months to sync it up, and between those sync-ups, I store a bunch of weekly deltas on USB/SSD/BD-RE/whatever that live with the backup array. If my main machine is lost, the backup array plus sequence of deltas will bring it up to being a complete and fresh copy no more than a week old.
I have had several hard drives die or silently corrupt data since I started using ZFS and have never lost data. I fully expect that I will never lose data again unless I do something really really dumb.
Many believe it is snake oil compared to, eg, rsync. If you mention ZFS. you have to be prepared for a lot of abuse getting thrown around, mostly by the ZFS advocates who deny that there is any other way that works, and they deny that they have to make any tradeoffs. Once you mention it, they’ll fry you for admitting there are options.
So it is better not to mention it, and just hope the comments can survive the needlessly fraught topic of “backups.”
I do it in an incredibly simplistic way: take external hdd, select folder, copy, paste, skip identical files. Once every few months, copy the contents of the external HDD to another external HDD that i keep at my parents’ house, after which i delete the unused files from my computer.