
This month’s CES saw the introduction of max speed DDR5 memory from SK Hynix. Micron and other vendors are also reportedly sampling similar devices. You can’t get them through normal channels yet, but since you also can’t get motherboards that take them, that’s not a big problem. We hear Intel’s Xeon Sapphire Rapids will be among the first boards to take advantage of the new technology. But that begs the question: what is it?
SDRAM Basics
Broadly speaking, there are two primary contenders for a system that needs RAM memory: static and dynamic. There are newer technologies like FeRAM and MRAM, but the classic choice is between static and dynamic. Static RAM is really just a bunch of flip flops, one for each bit. That’s easy because you set it and forget it. Then later you read it. It can also be very fast. The problem is a flip flop usually takes at least four transistors, and often as many as six, so there’s only so many of them you can pack into a certain area. Power consumption is often high, too, although modern devices can do pretty well.
So while static memory is popular in single board computers and small devices, a PC or a server will not be able to pack gigabytes of static memory. Dynamic memory just uses a little capacitor to store each bit. You still need a transistor to gate the capacitor on and off some common bus, but you can really pack them in. Unfortunately, there’s a big problem: the capacitors discharge pretty quickly. You have to devise some way to refresh the memory periodically or it forgets. For example, a typical DDR2 module needs a refresh every 64 milliseconds.
Real devices use rows and columns of capacitors to maximize space and also to allow the refresh to occur on an entire row. That means a device that has, say 4096 rows would need a refresh every 15.6 microseconds so that each row retains its data. The refresh itself takes just a few nanoseconds.
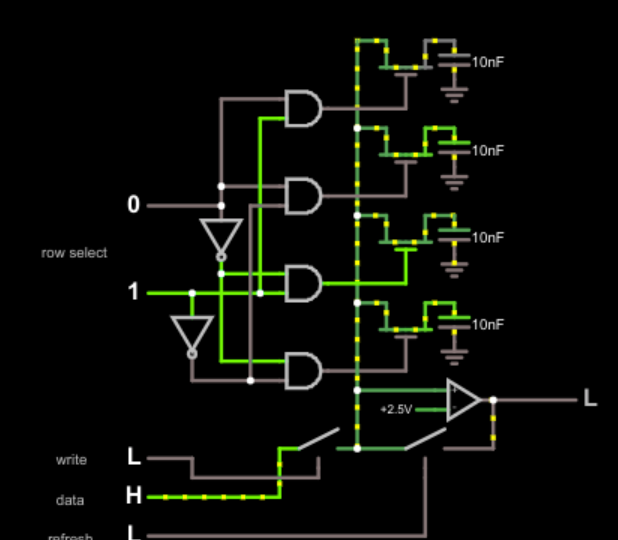 In a typical array, there is a row and column bus. A capacitor connects to a FET that can switch the capacitor on or off the column bus. The gate of the FET connects to the row bus. A row signal selects an entire row of FETs. The long column bus has some capacitance and resistance, so it takes a little precharge time before the signal is stable and then a multiplexer picks the bit off the correct column. Writing is just the reverse. You can play with a simulated line of dynamic memory if you want to get a feel for it.
In a typical array, there is a row and column bus. A capacitor connects to a FET that can switch the capacitor on or off the column bus. The gate of the FET connects to the row bus. A row signal selects an entire row of FETs. The long column bus has some capacitance and resistance, so it takes a little precharge time before the signal is stable and then a multiplexer picks the bit off the correct column. Writing is just the reverse. You can play with a simulated line of dynamic memory if you want to get a feel for it.
That’s dynamic RAM or DRAM. But what about SDRAM? SDRAM is dynamic RAM with a synchronous interface to a memory controller. The controller allows you to stack up several commands at once and the controller handles all the logic of handing the rows and columns and can even do the refresh step automatically. The controller buffers both commands and data to achieve higher bandwidth than is possible with many other technologies.
History
SDRAM goes back to 1992, and by 2000 had driven most other forms of DRAM out of the market. JEDEC, an industry group, standardized the interface for SDRAM in 1993, so you generally don’t have problems using different brands of memory.
Normal SDRAM can accept one command and transfer one word of data per clock cycle. Eventually, JEDEC defined a double data rate or DDR standard. This still accepts one command per cycle but reads or writes two words in that same clock cycle. It is able to do so because it transfers one data word on the rising edge of the synchronous clock and the other at the falling edge. In practice, this means the internal read on one command is two words and this allows the internal clock to be less than the I/O clock. So if the I/O clock is 200 MHz, the internal clock could be 100 MHz, but the data transfer will still be two words for every I/O clock.
 This worked so well, they invented DDR2, which reorganized the RAM to be four words wide internally, and then sends or receives four words in a burst. Of course, the clock speed didn’t really change, so you increase latency. DDR3 doubled the size of internal data again, with the corresponding increase in latency.
This worked so well, they invented DDR2, which reorganized the RAM to be four words wide internally, and then sends or receives four words in a burst. Of course, the clock speed didn’t really change, so you increase latency. DDR3 doubled the size of internal data again, with the corresponding increase in latency.
DDR4 was a departure. It did not double the internal memory bus, but interleaved access between internal memory banks to increase throughput. A lower voltage also allows higher clock speeds. DDR4 appeared around 2012 although it didn’t reach critical mass until 2015.
It sounds like memory bandwidth is on the rise, right? Sort of. The increase in bandwidth has tracked — more or less — with the rise in multicore processors. So while the raw bandwidth has increased, the bandwidth per core in a typical machine hasn’t changed much in a long time. In fact, with the rapid expansion of core count in a typical CPU, the average is in decline. So it is time for a new standard.
DDR5
Now we have DDR5, defined in 2017. According to reports, a DDR5-3200 SDRAM will have 1.36 times the bandwidth of a DDR4-3200 and could go higher. We hear, too, that the prefetch size will double again, at least optionally.
| Type | Bandwidth | Voltage | Prefetch | Year |
|---|---|---|---|---|
| SDR | 1.6 GB/s | 3.3 | 1 | 1993 |
| DDR | 3.2 GB/s | 2.5 | 2 | 2000 |
| DDR2 | 8.5 GB/s | 1.8 | 4 | 2003 |
| DDR3 | 8.5 GB/s | 1.8 | 8 | 2007 |
| DDR4 | 25.6 GB/s | 1.2 | 8 | 2017 |
| DDR5 | 32 GB/s | 1.1 | 8/16 | 2019 |
As you can see from the above table bandwidth from the original SDR memory is up by a factor of 20 over a 26-year period. Not bad. The 16 word prefetch is especially interesting since that will allow the chip to fill a typical PC’s cache in one fetch.
There are some other advantages, too. For example, if you’ve ever tried to interface an SDRAM with your own circuitry or FPGA design, you’ll appreciate the loopback mode. If you are a memory hog, the top size for modules is now 64 GB, up from 16 GB.
By the way, there is an LP-DDR5 spec which is a low power version for things like cellphones. That specification was released last year and we haven’t heard a big rush for products in that area yet. The LP-DDR4 spec allowed two frequency scaling points so you could trade speed with power. LP-DDR5 has three different possible settings. Then there are the GDDR standards — up to GDDR6 last time we checked — for graphics processing and other high-performance application. For perspective, LP-DDR5 clocks in with 6.4 Gb/s bandwidth per I/O bit, while GDDR6 boasts hundreds of GB/s depending on the bit width.
So What Now?
Unless you are running a busy server or something else that really loads up all the cores of your CPU, you aren’t going to really feel much practical difference between DDR4 and DDR5. But then again, who doesn’t want good benchmarks?
Besides, for a typical workstation load, the real trick is to have enough RAM that you don’t need to hit the disk very often. This is especially true if you have a rotating disk platter which is notoriously slow. The time spent reading and writing RAM memory turns out to not be the long tent pole in your real-world performance. With solid state disks, this isn’t as bad as it used to be, but typical solid state drive throughputs are just a bit faster than DDR3, even though faster drives are probably on the horizon. So unless you are doing very intense multicore workloads, you are probably better off having 32 GB of DDR3 than 4 GB of DDR5 because the larger memory will keep you from having even slower operations as often.














Nice to see the ball still rolling for better memory performance.
Add on to your last statement, 32GB of RAM is always better than 4GB of ANY ram if you plan on crowding 4GB and start caching to disk! My normal is now 16GB for desktops/laptops and my workstation with VMs is 32GB. All DDR4 of course. Avoid disk thrashing at all costs regardless of how much ram you have. Always have more than enough RAM (price depending of course). Right now memory is relatively cheap.
As demand for DDR5 rises, second-hand DDR4 should become cheaper. I picked up 96 GB of DDR3 for $50 recently, which is still 96 GB of disk cache whether it’s old technology or not.
This old man’s first computer had 128 bytes of RAM, now we are approaching 1,000,000,000 times that! :-D
Multiply by 3 and thatd be a decent Blade Server RAM. One Blade.
Mine had 512. ET-3400.
Mine had a whopping 1K! I never got the expansion for my ZX81.
I bought the Memotek 32K expansion for mine, largely because it had a connector on the back so the I/O port was not blocked.
Using 2114’s, I hand-wired a 6KB static RAM expansion module to my MICROACE (ZX-80 kit), which gave me a full 8KB of RAM! I also added a HEATHKIT leaf-spring full-size keyboard to the MICROACE.
Peace and blessings.
Later in the 80s, when everything was dirt cheap, I got a ZX-81, RAM expansion and keyboard, was gonna make a badass ZX-81 system, and use it for interfacing experiments etc. The family owned Spectrum was off limits for such. I only had it all hooked up for a day or two when it burned out badly. Huge burned trace from the 7805 right down the board, looked like the ULA burned too. It was beyond my skillset to fix at the time. I guess either the RAM pack maker or keyboard maker didn’t count on there being other peripherals and warn about overstressing the supply. Also with the ram pack sitting over the edge connector I think convection cooling from that aluminum slab was much reduced. Some time later I sourced a replacement victim. This one must have been from a kit build, it was early revision, had the keyboard soldered to the PCB so I couldn’t do the keyboard swap easily, and it had weird glitches… I tried a ROM swap from the later one, hoping that some were software issues, but it just gave me the black rectangle, never initialised properly. So nothing much happened with that one, kept it “stock” and futzed around with it in a desultory fashion every few weeks trying to figure out what the flip it’s issues were.
Same here, but I soldered in another 128bytes for blazing performance. :)
Pocket calculators do not really count. :-) My first computer was the C64.
A 20 fold increase in 26 years is terrible. If we assume Moors law is no more, was only at 50 percent over the period That would mean a doubling of processing power every 3 years. That would require a total of 256 times increase to match the historic processor / memory speed ratio. I suppose we just rely on additional cash to compensate these days.
I’d have to agree with you there, the rate of progress slowed down, at the 64 bit mark, for consumers, numbers of transistors, frequency, from about 2006, improvements began to crawl along. They were up against physics and finance, the tech wreck, was in full swing, the biggest leaps in technology, then came in flash memory, number of pixels, low power RAM, leading to the smartphone and tablet. PC’s and laptops moved slowly, with compact software, apps, being more successful, such as Android and iOS, in market share, I have a laptop, 12 GB of RAM, 250 GB of flash, i7, touchscreen, it’s 6 years old and runs the latest Windows 10 software.
Internet speed has greatly increased, in the last 4years, my internet speed, is 50 times faster, graphics have advanced too, my NVIDIA Shield TV, cost $165 US and has 256 graphics processors. Runs 4K UHD, like a dream, it’s all about breaking the bottlenecks, 64 bit mobile devices, with compact software, pumping flash, internet, pixels, or good chip architecture, for running photo, VR, security, communications, natively.
2006 is when Intel very securely held the crown. Then Intel stopped progressing at Intel Core and started milking consumers for money while moving forward as little as possible.
Moore’s law was about the number of transistors in a device, not the processing power.
There is an implicit link between transistor size and maximum clock rate and processing power is linked to total numbers of transistors. It’s not all linear as there is also a limit of total power and there have been a couple of definite pauses in the expansion of processor power.
There was a very good talk on modern chip fabrication at HOPE in 2012 called “Indistinguishable From Magic – Manufacturing Modern Computer Chips” if you want to understand the monumental tasks in making the current generation of silicon devices, it is well worth a watch.
https://www.youtube.com/watch?v=NGFhc8R_uO4
Interesting video. Started it but couldn’t read the charts so I inboxit to myself so I could on my computer Thx for the link Even though it’s from 2012 it’s very interesting to the less informed.
It is not that old it does at least touch on the problems that would be involved in going to a 7nm and 4nm process.
Which, even now, could help to explain why Intel’s next-gen DG2 produced on the 7nm node will be produced by TSMC, and not by Intel’s in-house.
My first was a DEC Rainbow with two proprietary floppy drives. 64K RAM standard and I had ‘upped’ to 256K. I was ‘swimming’ in memory at that time! Even used Turbo Pascal (Ran on CPM/86 I believe) on that box for college/fun projects. Helped not via for time on the school VAX computer.
Yep, times have sure changed since the 80s…
Sadly all the memory bandwidth in the world won’t help with the class of problems that inherently involve true random access… Caching helps some if your working set is small or you can batch a pile of requests together and dispatch several independent-but-colocated items together…Hash tables and the like suffer greatly from main memory being such that reading 1M random words over 1G is two or three orders of magnitude slower than reading 1M adjacent words.
It’s hard to construct a pipeline long enough to eat 70ns of latency productivity when each stage is only 500ps long. There are, of course, tricks to assist here (Out-of-Order execution, Simultaneous MultiThreading, large caches, speculative execution) but these bring with them Meltdown & Friends…
A sufficiently large set of SMT like contexts might be able to hide much of the latency (a’la Parallax Propeller but with “real” CPUs) but ultimately that requires a major rethink of software architecture to really take advantage of that without running afoul of Amdahl’s law… — anything with a true data dependency must block of course, but the hard part is avoiding any spurious blocking.
I thought you were going to say:
“Sadly all the memory bandwidth in the world won’t help with the class of problems that inherently involve from poorly written software”
… but that works too. :P
^ This
The Tera (who bought Cray and rebranded themselves as Cray Inc.) MTA series had very high SMT thread counts – wikipedia says 256 threads on the MTA-2 and I think I remember it was at least different on the MTA-1. This was done to “hide” memory latency, like you said. Eventually this would be sold as the Cray “Yarc”, basically a hardware Graph Processing machine. And graph algorithms have notoriously bad locality. I don’t know happened to them – I saw a publication from someone(s) at Oak Ridge that was combing the “PubMed Central” repository building Knowledge Networks on a Yarc, but that was a few years ago.
Cray is like the Brooklyn Bridge of computer companies – it’s had A Whole Lot of Owners. :-) Latest is Hewlett Packard Enterprise. A very small part of me wants to see HPUX on a YMP, and if anyone can do it, they can.
True random access is not such a problem, a problem would be sequential processing random access. You can request a bunch of randomly positioned data at a time at high bandwidth (though admittedly not as quickly as same-row), what is slow is [fetching one value->using that value to find next address->fetching next…]
There’s something else on the memory front that is going to change lots of things. It’s lumped together as “storage class memory” (SCM) – basically a few ways of making slow RAM that doesn’t lose its memory when turned off. Intel has started shipping “Optane DIMMs”, not to be confused with their Optane SSD products (great branding there, Intel…)
Cons: By RAM standards it’s really slow (350 nanosecond access times). But by NVMe SSD standards that’s amazingly good. And very few (only Cascade Lake?) Xeons have memory controllers that can use it. All your assumptions about RAM versus secondary storage are going to have to be revisited – all databases, relational or noSQL, need to be re-architected to take full advantage of it.
Pros: Persistent memory across power outages. Byte addressable instead of only block addressable (this is a big deal). A fraction of the heat (per gigabyte). All your assumptions about RAM versus secondary storage are going to have to be revisited – all databases, relational or noSQL, need to be re-architected to take full advantage of it. (yeah, it’s in both categories).
Intel’s approach, and it’s a typical one, is to either change the crystal “phase” of a material or force it to flip-flop between a crystal and an amorphous solid. The latter calls back to the previous article on solder types, of all things – “tin pest” is when Sb switches from crystalline Beta form to amorphous Alpha form and turns to powder. Small world.
Depending on your workload, it’s not 100% clear how you should architect for SCM. You could use it as really, really slow DRAM and let the L1/L2/L3 caches “hide” the slowness. In this case, having terabytes of RAM-like storage and never having to tap secondary storage, either as paging space, swap space, or being forced to use an algorithm friendly to secondary storage, might be a big win. Alternatively, it might be worthwhile to count on your executable code being tight enough to fit in the L1 to L3 caches, having just enough DRAM to boot and run your code, and use the SCM as really, really fast secondary storage. Intel ships a driver that makes it look like a regular block device and you can format a regular filesystem on it. Finally, you might want to write your applications so that when you call new() it creates a persistent object in SCM that works just like any other object in your language – think about something like Hibernate (java) that doesn’t have to “save” an object before your program quits.
Since it’s byte-addressable, instead of having to access whole blocks, all the assumptions about how to do durable data storage just got turned on their proverbial ear. For one thing, database servers probably aren’t going to use buffer pools. Further, lock processing will be thousands to millions of times slower than storage device access now (only because the devices just got so much faster). Lock-free architectures for concurrency control were, honestly, kind of a research curiosity that just suddenly got interesting again. A good jumping off point might be to look at the architecture of VoltDB and ask “where do you want to go from here?” And, presumably, hope Michael Stonebreaker doesn’t beat you to it, but whatever, it’ll be fun. :-)
Maybe – speculation here – we’ll change a lot more. Intel put 16GB of RAM right there on the die with their “Knights Landing” Xeon Phi generation. Imagine if that morphs into 16GB of L4 (or 5, or 6…) cache to be filled from 350 ns SCM? Sure, architectural challenges abound trying to turn on-chip DRAM into yet another layer of cache, but challenges are there to be solved, right?
More: https://www.tomshardware.com/news/intel-optane-dimm-pricing-performance,39007.html (comparison to RAM price is outdated already – RAM is cheaper per byte again but the heat is becoming a big deal)
My purpose in writing this epistle (sorry for the length / not sorry) is that Hackaday has a decent concentration of people who might see this and run with it. There are some serious hacks (and theses, and dissertations) lurking in this stuff – hardware and software.
didn’t know about SCM DRAM, so interesting.
MRAM is also a hot topic, especially in embedded as it get rid of slow and chunky flash and the software paradigm change is not so big (in fact it simplify a lot a thing). But there is still a lot of unknown for MRAM reliability in the long term.
Meanwhile I still use a laptop with DDR2 and my desktop was upgraded to 12GB of DDR3 – can’t afford any more. New computers seem to have taken off in every number including price.
I bought a new MB recently and I still had to choose between DDR3 and DDR4, and the only reason I got DDR4 was because of specific unrelated motherboard features.
Looking at the specs above, I doubt DDR5 is going to make it into very many consumer devices. The bandwidth numbers they list are not actual real-world numbers, and DDR4 is already not actually any faster than DDR3 in a desktop computer or laptop.
DDR3 might come way down in price though, as the high end and server machines switch to DDR5.
Not sure if the dates on that chart is wrong or if it’s not suppose to be release dates, but ddr4 came out in 2014 not 2017
And DDR3 is 1.5V, or 1.35V in the case of DDR3L
hey there,
hate to break it to you but I’m with Bento on this…DDR4 was a 2014 PUBLIC release while DDR5 just started sampling to manufacturers….apples to apples here would be correcting DDR4 to 2014 and stating that DDR5 is likely to see public release in the 2021-2023 range OR stating that DDR5 just began sampling and DDR4 sampled in 2012 – a 7-8 year difference depending on how you count months.
We knew DDR4 more than we knew DDR3…I don’t like misrepresentation or ignorance of the facts.