
Modern-day hard disk drives (HDDs) hold the interesting juxtaposition of being simultaneously the pinnacle of mass-produced, high-precision mechanical engineering, as well as the most scorned storage technology. Despite being called derogatory names such as ‘spinning rust’, most of these drives manage a lifetime of spinning ultra-smooth magnetic storage platters only nanometers removed from the recording and reading heads whose read arms are twitching around using actuators that manage to position the head precisely above the correct microscopic magnetic trace within milliseconds.
Despite decade after decade of more and more of these magnetic traces being crammed on a single square millimeter of these platters, and the simple read and write heads being replaced every few years by more and more complicated ones, hard drive reliability has gone up. The second quarter report from storage company Backblaze on their HDDs shows that the annual failure rate has gone significantly down compared to last year.
The question is whether this means that HDDs stand to become only more reliable over time, and how upcoming technologies like MAMR and HAMR may affect these metrics over the coming decades.
From Mega to Tera

The first HDDs were sold in the 1950s, with IBM’s IBM 350 storing a total of 3.75 MB on fifty 24″ (610 mm) discs, inside a cabinet measuring 152x172x74 cm. Fast-forward to today, and a top-of-the-line HDD in 3.5″ form factor (~14.7×10.2×2.6 cm) can store up to around 18 TB with conventional (non-shingled) recording.
Whereas the IBM 350 spun its platters at 1,200 RPM, HDDs for the past decades have focused on reducing the size of the platters, increasing the spindle speed (5,400 – 15,000 RPM). Other improvements have focused on moving the read and write heads closer to the platter surface.
The IBM 1301 DSU (Disk Storage Unit) from 1961 was a major innovation in that it used a separate arm with read and write heads for each platter. It also innovated by using aerodynamic forces to let the arms fly over the platter surface on a cushion of air, enabling a far smaller distance between heads and platter surface.
After 46 years of development IBM sold its HDD business to Hitachi in 2003. By that time, storage capacity had increased by 48,000 times in a much smaller volume. Like 29,161 times smaller. Power usage had dropped from over 2.3 kW to around 10 W (for desktop models), while price per megabyte had dropped from $68,000 USD to $0.002. At the same time the number of platters shrunk from dozens to only a couple at most.
Storing More in Less Space

Miniaturization has always been the name of the game, whether it was about mechanical constructs, electronics or computer technology. The hulking, vacuum tube or relay-powered computer monsters of the 1940s and 1950s morphed into less hulking transistor-powered computer systems before turning into today’s sleek, ASIC-powered marvels. At the same time, HDD storage technology underwent a similar change.
The control electronics for HDDs experienced all of the benefits of increased use of VLSI circuitry, along with increasingly more precise and low-power servo technology. As improvements from materials science enabled lighter, smoother (glass or aluminium) platters with improved magnetic coatings, areal density kept shooting up. With the properties of all the individual components (ASIC packaging, solder alloys, actuators, aerodynamics of HDD arms, etc.) better understood, major revolutions turned into incremental improvements.

As happened in other fields, the physical limits on write speeds and random access times would eventually mean that HDDs are most useful where large amounts of storage for little money and high durability are essential. This allowed the HDD market to optimize for desktop and server systems, as well as surveillance and backup (competing with tape).
Understanding HDD Failures
Although the mechanical parts of an HDD are often considered the weakest spot, there are a number of possible causes, including:
- Human error.
- Hardware failure (mechanical, electronics).
- Firmware corruption.
- Environmental (heat, moisture).
- Power.
HDDs are given an impact rating while powered down or when in operation (platters spinning and heads not parked). If these ratings are exceeded, damage to the actuators that move the arms, or a crash of the heads onto the platter surface can occur. If these tolerances are not exceeded, then normal wear is most likely to be the primary cause of failure, which is specified by the manufacturer’s MTBF (Mean Time Between Failures) number.
This MTBF number is derived by extrapolating from the observed wear after a certain time period, as is industry standard. With the MTBF for HDDs generally given as between 100,000 and 1 million hours, to test this entire period would require the drive to be active between 10 to 100 years. This number thus assumes the drive operating under the recommended operating conditions, as happens at a storage company like Backblaze.
Obviously, exposing a HDD to extreme shock (e.g. dropping it on a concrete floor) or extreme power events (power surge, ESD, etc.) will limit their lifespan. Less obvious are manufacturing flaws, which can occur with any product, and is the reason why there is an ‘acceptable failure rate’ for most products.
It’s Not You, It Was the Manufacturing Line
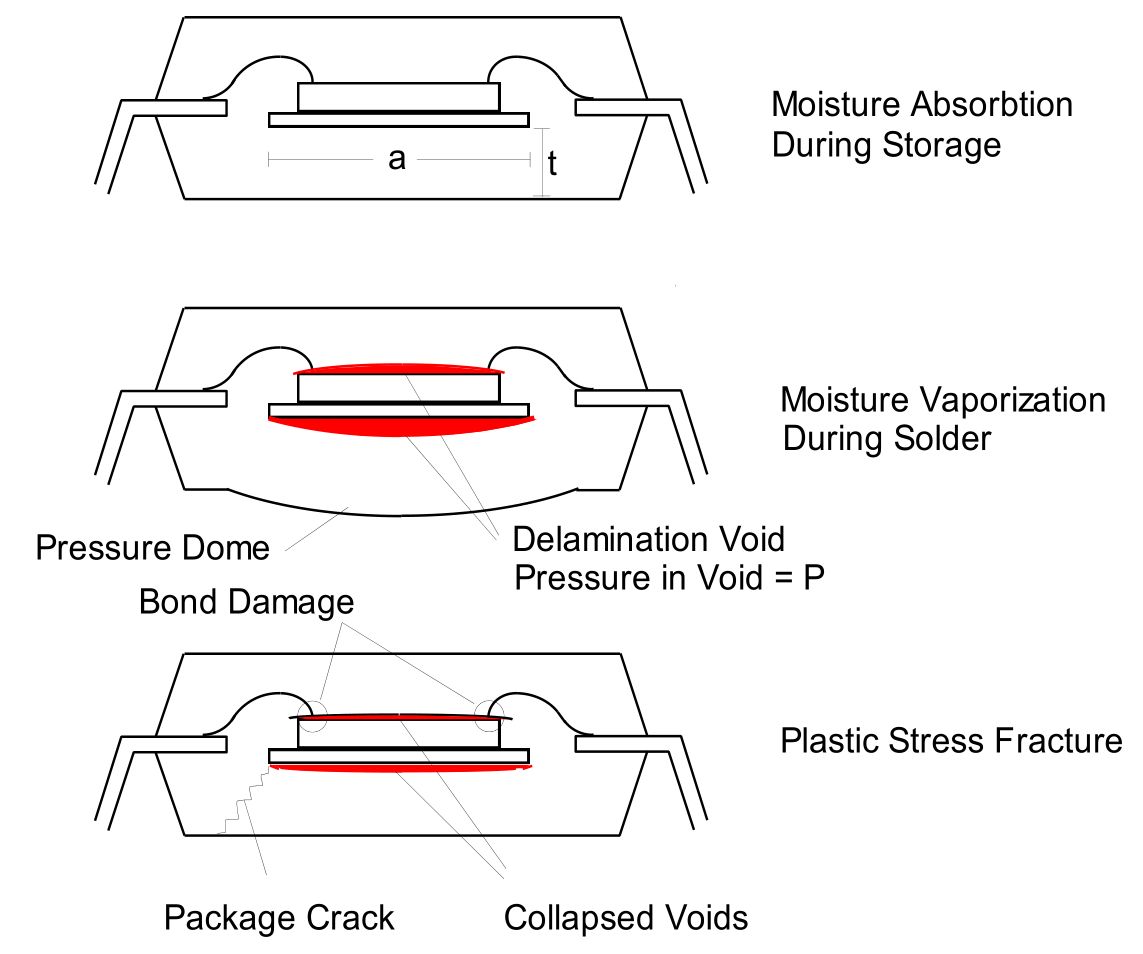 Despite the great MTBF numbers for HDDs and the obvious efforts by Backblaze to keep each of their nearly 130,000 drives happily spinning along until being retired to HDD Heaven (usually in the form of a mechanical shredder), they reported an annualized failure rate (AFR) of 1.07% for the first quarter of 2020. Happily, this is the lowest failure rate for them since they began to publish these reports in 2013. The Q1 2019 AFR was 1.56%, for example.
Despite the great MTBF numbers for HDDs and the obvious efforts by Backblaze to keep each of their nearly 130,000 drives happily spinning along until being retired to HDD Heaven (usually in the form of a mechanical shredder), they reported an annualized failure rate (AFR) of 1.07% for the first quarter of 2020. Happily, this is the lowest failure rate for them since they began to publish these reports in 2013. The Q1 2019 AFR was 1.56%, for example.
As we have covered previously, during the manufacturing and handling of integrated circuits (ICs), flaws can be introduced that only become apparent later during the product’s lifespan. Over time, issues like electromigration, thermal stress and mechanical stress can cause failures in a circuit, from bond wires inside the IC packaging snapping off, electromigration destroying solder joints as well as circuits inside IC packaging (especially after ESD events).
The mechanical elements of an HDD depend on precise manufacturing tolerances, as well as proper lubrication. In the past, stuck heads (‘stiction‘) could be an issue, whereby the properties of the lubricant changed over time to the point where the arms could no longer move out of their parked position. Improved lubrication types have more or less solved this issue by now.
Yet, every step in a manufacturing process has a certain chance to introduce flaws, which ultimately add up to something that could spoil the nice, shiny MTBF number, instead making the product part of the wrong side of the ‘bathtub curve’ for failure rates. This curve is characterized by an early spike in product failures, due to serious manufacturing defects, with defects decreasing after that until the end of the MTBF lifespan approaches.
Looking Ahead

HDDs as we know them today are indicative of a mature manufacturing process, with many of the old issues that plagued them over the past half decade fixed or mitigated. Relatively major changes, such as the shift to helium-filled drives, have not had a noticeable performance on failure rates so far. Other changes, such as the shift from Perpendicular recording (PMR, or CMR) to Heat-Assisted Magnetic Recording (HAMR) should not have a noticeable effect on HDD longevity, barring any issues with the new technology itself.
Basically, HDD technology’s future appears to be boring in all the right ways for anyone who likes to have a lot of storage capacity for little money that should last for at least a solid decade. The basic principle behind HDDs, namely that of storing magnetic orientations on a platter, happens to one that could essentially be taken down to singular molecules. With additions like HAMR, the long-term stability of these magnetic orientations should be improved significantly as well.
This is a massive benefit over NAND Flash, which instead uses small capacitors to store charges, and uses a write method that physically damages these capacitors. The physical limits here are much more severe, which has led to ever more complicated constructs, such as quad-level (QLC) Flash, which has to differentiate between 16 possible voltage states in each cell. This complexity has led to QLC-based storage drives being barely faster than a 5,400 RPM HDD in many scenarios, especially when it comes to latency.
Spinning Down
The first HDD which I used in a system of my own was probably a 20 or 30 MB Seagate one in the IBM PS/2 (386SX) which my father gave to me after his work had switched over to new PCs and probably wanted to free up some space in their storage area. Back in the MS DOS days this was sufficient for DOS, a stack of games, WordPerfect 5.1 and much more. By the end of the 90s, this was of course a laughable amount, and we were then talking about gigabytes, not megabytes when it came to HDDs.
Despite having gone through many PCs and laptops since then, I have ironically only had an SSD outright give up and die on me. This, along with the data from the industry — such as these Backblaze reports — make me feel pretty confident that the last HDD won’t spin down yet for a while. Maybe when something like 3D XPoint memory becomes affordable and large enough might this change.
Until then, keep spinning.














Thanks for the history lesson! HDD tech has come a long ways. No doubt about that! Every time I crack open a no longer functioning HDD, I am amazed that it actually works as well as it does.
Until the price of SSD technology per byte gets close to HDD, there will always be a place for HDD. Right now the price for SSD is affordable for OS and programs and some data in my computers… but for lots of data, the HDD still reigns supreme. My ‘affordable’ price point is about ~$100. That will buy today a 1TB SSD which is really a lot of disk space for most uses. Anyway, for me the only place I have HDDs anymore is my server and external backup drives.
Time is soon 1tb nvme drives are in the 150ish range
The mechanical clearances between the recording medium and the read and write elements of the head are three orders of magnitude smaller than your article suggests. In modern HDDs there is only one or two nanometers clearance while the HDD is actively reading or writing. Extraordinary!
The first 6.3GB HDD I had installed some 25 years ago had a MTBF translating to 95 years, yet suffered OOBF or Out of box failure. Just my luck.,
IBM Deathstar. Had a couple. Didn’t end well.
https://goughlui.com/2013/03/01/hard-drive-disassembly-the-ibm-deathstar/
Interesting. Last week, a former client said that he owes me a beer. In late 2018, I wagered a Ruination IPA that the spinners embedded in the production-line controllers would be more reliable than the systems having SSDs. Systems comprised 53 having HDDs and 34 having SDDs, where there was ONE HDD failure (it failed gracefully, no data or time lost) and there were SEVEN SSD failures. And the HDD failure was in a system with a 2015 install date. The FDDs were all installed in early 2018.
Hard Disk Drives are an interesting field to say the least.
It’s impressive how a device with such spectacular flatness is such commonplace. And the rather nifty tricks hard drive manufacturers use to get to higher storage densities are also interesting.
Though, the sentence in the article “spinning ultra-smooth magnetic storage platters only micrometers removed from the recording and reading heads” is very outdated….
The distance between the read/write head and the platter itself tends to be on the order of nm, not µm. And singular nm at that…. Though, the distance is also proportional to the air pressure within the drive, ventilated drives thereby have a max altitude rating. Above that altitude, a head crash is practically imminent. (Helium filled drives aren’t ventilated, nor is a bunch of other drives as well…)
If Heat Assisted Magnetic Recording is going to be a breathtaking step forward, or just a decrease in power efficiency is a thing worth seeing. (In my own opinion, it isn’t all that interesting…..)
Also, in regards to water vapor related failure during chip manufacturing, this is indeed a very large issue to contend with. Something not all electronic manufacturers cares much about to be fair. When a chip goes “pop”, then it is obvious, but the vast majority of the time, it is not going to show any signs.
Diablo Printers had a problem with that in some control boards back in the late 80’s or early 90’s. Supposedly when they’d pop it’d send full power to all the motors. Imagine a big daisy wheel printer slamming its heavy carriage at top speed across 15″ while spewing paper. Would be quite a show. Make me wonder if it’d send the “lp0 on fire” error?
No mention of how disk capacity and cost-per-MB was horribly stalled in the 90s, with no obvious way forward? The whole industry was rescued by solid basic science research that led to the discovery of Giant Magnetoresistance (GMR). It enabled heads that dramatically increased drive capacity and decreased cost, first brought to market by IBM (1997) but quickly by all the other manufacturers. The discovery of GMR rightfully got the Nobel prize in 2007.
Guess what..It is even more stalled today. Now it is more of a problem with the writing process and the materials used for the writer being at the edge of the magnetic field power density they can apply to the disk. For many years the data Arial density increase averaged about 60% a year. During about ten years the increase has only averaged about 3% a year. What the HDD companies have been doing is put more disks in drive. An 18TB drive has 9 disks in it. The form factor of the box is only 1″ tall so they are really squeezed in there. The form factor could be changed to be taller and fit more disks. The problem with that is there is so much legacy server equipment that take 1″ tall only and the customers that buy the majority of the production for new installations do not want that as of yet. One of the many reasons of putting helium in the drive was it allowed some metal plates that were between the disks to be removed. That space was needed and used for more disks. Hammer, once it gets all the bugs worked out, is hoped to provide that path to a jump in Arial density. On paper it is believed to not be a one time jump but have room to grow for a while as this complicated system gets better understood and fine tuned.
Spent $700 dollars for a 10MB MacBottom hard drive back in the day…
Apple used to charge that for a replacement 800K floppy drive for the first Mac’s.
Reminds me of something which is true in many parts of life: it’s not any harder to do things the right way than the wrong way, once you learn how. It’s a real blessing that HDD prices keep going down even as the technology keeps getting more and more perfect!
I still think of spinning media as the solution for long-term storage, even as I use flash of one sort or another for all of my working files. I’ve had so many HDDs, I’ve seen them die every which way, but in general I like that they tend to die gracefully. I’ve gone through a bunch of hassle to get old data off of a “dead” HDD and only once have I failed to get most of my data back. And for 20 years, I always use RAID1 mirroring and I never lose anything once it’s in that repository. I’m warry of SSDs for storage because the stories of sudden 100% failure are so common. It seems like they’re really opaque, probably the information is still in there but the firmware has tripped and decided it won’t let you have anything. I don’t know what the cultural difference is but every HDD I’ve ever had was happy to keep talking to the controller (sometimes after a reset) even as the error count went through the roof.
I guess just to stir the pot, I’m gonna mention SMR :) My most recent (8TB) acquisition turns out, in hindsight, to be one of these drives with non-disclosed SMR. I did notice when I set up the initial RAID1 mirror, it took longer than I expected, but it was done in the morning before I woke up the next day. It didn’t even occur to me that might be the result of something unusual until I read about SMR a few months later. Personally, I’m still tickled to have reliable cheap storage that keeps growing in capacity for the same price each year. For 20 years, I’ve been buying the slowest drive I can find (like “eco” label) because I believe that heat kills, so I guess I’m the ideal target market.
I have had ssd’s die (always bought used ones for the practically throwaway second hand laptops ID use in work ,am a mechanic so i go through them, so just build em as cheap as possible) Anyways, yeah, when a hdd fails you get corruption, or mibby a dry bearing that you can coax to life 1 more time , or worst case a head crash, and a head swap will get you one last stab at getting your data. but ssd’s , one day the work fine, next it wont even get recognised by the controller. no half way house, no warning. thats my experience, now any machine I care about with an ssd has backups set up automatically. to spinning rust.
Many consumer grade SSDs have a ‘self bricking’ feature. Once the failed blocks reach a specific threshold, the device just shuts down, no more writing or reading allowed. I could see shutting off writes to protect against further degradation and potential corruption but disabling reading the contents is just mean bullshit.
What should happen is disabling writing so that the owner can get the data copied off, then have a “nuke” function that writes zeros several times to all blocks *then* shots off read capability to ensure nobody can pick it out of the trash to read stuff off it.
Make the destruct function a physical switch on the board, one that’s difficult to move and physically, permanently, locks when moved to destruct position.
Intel’s enterprise grade SSDs don’t self brick when their error count gets high. They continue to allow full speed reading but slow down writing a lot.
As yet I’ve only had two pieces of solid state storage die. One was my first USB flash drive. 128 megabytes with a physical write protect switch. Just up and became unreadable one day. The other was a 64 gig SanDisk Micro SD in 2017. I deleted some files and decided to try a secure erase that wrote zeros to all unused blocks.
The card became very secure. Un-writeable but still readable. Not worth the bother to send in for warranty replacement. IIRC it cost me less than the 128 meg USB thumb drive had several years earlier.
>Intel’s enterprise grade SSDs don’t self brick when their error count gets high. They continue to allow full speed reading but slow down writing a lot.
This is incorrect. You bought marketing lies. In reality this is what happens: https://techreport.com/review/26523/the-ssd-endurance-experiment-casualties-on-the-way-to-a-petabyte/
‘supposed to put the 335 Series in a read-only, “logical disable” state.’
‘attributes were inaccessible in both third-party tools and Intel’s own utility, which indicated that the SMART feature was disabled. After a reboot, the SSD disappeared completely from the Intel software’
‘According to Intel, this end-of-life behavior generally matches what’s supposed to happen. The write errors suggest the 335 Series had entered read-only mode. When the power is cycled in this state, a sort of self-destruct mechanism is triggered, rendering the drive unresponsive.’
according to intel self-destruct on reboot is the desired behavior! :o)
One of my favorite physics experiments for kids is to ask them what makes two hard disk platters stick to each other the way they do, as I demonstrate it with some sacrificial platters. (The extraordinary flatness creates interesting effects when interacting with the atmospheric air pressure.)
debug g=DC00:6
fdisk
format c:/s
Whatever, man. mkfs is how Real computer folks format their drives, MSDOS was always for weenies.
Partly correct. The first step isn’t a DOS application, it’s ROM code on the disk adapter.
Command line low level formatting a SCSI drive connected to an Adaptec AHA-154X
You forgot to manually enter the defect list. ;)
For a Western Digital MFM controller it was
debug G=C800:5
Just had an exchange about faux low-level formatting like a week ago, so will just repeat myself:
You _cant_ low level format SCSI drives. SCSI “low level” format utilities like aspifmt.exe are sending SCSI Command 4 called “FORMAT UNIT”, it does the same thing PC3000 “SelfScan” does – regenerate P-List and zero out G-List (sector mapping, bad sector list, sector translation). Its a fire and wait until drive reports success/error type of command, non interactive no progress bar, drive internal type of deal. You can look it up in SCSI standard (or SCSI Commands Reference Manual), it was never called low-level format by T10 Technical Committee.
Low-level format is writing Track and Sector markers to a raw disk medium. Formatting floppies does this, as does low level format on MFM/RLL drives accessible by using debug .com and jumping to C800:somewhere. On newer drives density was too high for a drive to initialize itself, manufacturer has to do this at the factory. “SelfScan” and “FORMAT UNIT” can only scan for defects and reinitialize P-List/G-List/T-List, they all operate at translation level, one above the physical sector hardware level. TLDR low level format is about laying down physical sectors, “SelfScan”/”FORMAT UNIT” can only operated on already defined sectors shuffling them around in a translation tables.
“Low level format” just sounds so strong and reassuring. Thats why all those utilities keep pretending to do it to self legitimize :) Even Seagate nowadays lies directing users to SeaTools zero fill utility calling it low level :/, while all it can do is trigger Smart bad sector remap (growing G-List).
“The question is whether this means that HDDs stand to become only more reliable over time, and how upcoming technologies like MAMR and HAMR may affect these metrics over the coming decades.”
Well.. if they go the way most things do then they will continue to become more reliable only to be replaced by something more disposable. SSDs with their limited number of writes sounds like a good contender to me. Consumers will go right along with this because old tech isn’t shiny.
If I could get the data off HDDs as fast as SSDs …. I think I’d still be on HDDs. There is just something about an OS booting in a flash, programs up instantly, and fast compiles of code …. But HDDs aren’t there, so to the ‘back of the bus’ or into the ‘back room’ for them!
yes speed is great for operating system but if you wana store masses of data you have to be rich to do it with SSD. I just bought a 1T flash for something like $120 while a 18T HDD is under $600. The internet you phone texts movies all that stuff lives on rotating storage. As it is the demand for storage is so large, and growing at a rate that is unbelievable, that SSD foundries do not have the capacity to supply it.
Spinning drives in modern laptop computers are just begging to fail from mechanical issues after years of getting thrown around, dropped, etc Everything else in a laptop can withstand terrible abuse. Look at the amount of packaging needed to protect a spinning drive in transit, it’s like they are eggs or delicate glass figurines.
How true. My main problem thought was ‘speed’. The replacement sata SSDs I put in my Linux laptops and a Linux notebook at the time ‘really’ put new life into them… besides the durability factor (although I don’t recall any incidents though with killing a laptop drive).
I still have my old Palm LifeDrive. Changed the 4 gig Hitachi Microdrive to a 4 gig compact flash after the Microdrive died. MUCH FASTER!
What really hurt the LifeDrive was Palm’s bait and switch. Early review units were sent out with a 5 gig Seagate drive that had onboard cache and was just inherently faster. LifeDrive garnered praises for how snappy its operation was.
The shipping to retail LifeDrive was equipped with a cacheless and very slow Hitachi 4 gig drive. #1 gripe (aside from the overall bulk of the device) from reviewers of the retail LifeDrive was the abysmal lack of speed.
Interesting article. I started my “computer career“ in the 70s with IBM, Amdahl and DEC and their associated disk drives and tape drives. Now 45 years later, I’ve been swapping out my desktop hard drives for SSD thinking I was doing something great; however, after reading the article and comments, I’m having second thoughts. I find the SSD’s to be much quicker, but that could simply be due to the age of the HDD’s. Everything is backed up locally on HDDs and to the cloud. Thoughts/recommendations?
HDDs make precision engineering commonplace.
VCR: Am I a joke to you?
*adjusts tracking knob*
The data density of HDDs far exceeded that of VHS a very long time ago. The effective capacity of a VHS tape is just a few GB, even with the VHS tape having a lot of surface area.
Enterprise Tape storage is still very much alive, altho due to mergers its down to afaik two players, IBM and Fuji
https://www.youtube.com/watch?v=PNTNmAoxNbg
At the end of a day you need a long term storage medium, and SSD is not it with its 6-12 months unpowered and poof no data technology.
I’ve taken apart a lot of drives, for the magnets (and the platters, they look nice even if I can’t figure out a use).
Low capacity drives have a bunch of platters, while higher capacity get by with one. Not a detailed story, but I was surprised that as higher capacity drives were trashed, they went to fewer platters. I haven’t taken apart one of my 340gig drives.
> (and the platters, they look nice even if I can’t figure out a use)
Along with the enclosures, they’re raw material for casting.
5.25″ aluminum HDD platters are ideal for windchimes. I made a clock out of a dead 3.5″ full height drive.
I reused a HDD casing as a shielded enclosure for a high end audio DAC.
https://github.com/NiHaoMike/OpenDAC-HD
Tesla turbine?
the industry is doing about 2TB per each 3.5″ disk these days so a 18 TB HDD has 9 disks in it.
Spinning rust isn’t derogatory at all. Spinning rust is equated with reliability at the cost of speed, when compared with SSDs.
Also, settled on just a couple of platters? No. Only low capacity drives have just one or two platters.
Otherwise, good!
too bad they have not used rust in many decades now..The disks recording magnetic are made with many layers of different elements. These are put on with similar technology as ICs are made.
> As improvements from materials science enabled lighter, smoother (glass or aluminium) platters with improved magnetic coatings, aerial density kept shooting up.
Little wee typo there. It should be /areal/ density. Oh and what’s with the aluminium, is the writer British?
https://en.wikipedia.org/wiki/Areal_density_(computer_storage)
aerial – existing, happening, or operating in the air.
It’s amazing to see how far things have come in a fairly short time.
I still VIVIDLY remember the first 1 Gig hard drive I ever handled – because it slipped off the forklift and broke my foot.
Some years ago at an auction I saw a massive IBM multi-tape data storage system. Like a bunch of washing machines in a row for the drives, and a control cabinet the size of a couple of upright freezers. I looked up the specifications and added up the capacity. Fully loaded with cartridges (similar to but rather unlike LTO) the total raw capacity was just a titch over 2 gigabytes.
At the time a 2 gig USB thumb drive had just been released. The tape system got no bids, not even from scrappers. “Hey boss, you know that quarter million dollar 2.1 gig tape storage system that’s holding the building down?” “Yeah, what about it?” “I just picked up two of these 2 gig thumb drives at Best Buy for $85 each.”
Around the same time I was at a scrapyard and saw a couple of very large cabinets loaded with slots for hard drives. The whole bottom of each cabinet was all power supplies and fans. Inside the building was the stack of drives removed from the cabinets. Each drive was 9 gigabytes, most likely some kind of SCSI but with some weird-o proprietary connector. I was into old Mac computers at the time, if they’d had SCS80 plugs I would’ve bought a couple. I went out and counted the drive slots, did the mathematics and marveled at the sheer mass and power suckage of a ONE TERABYTE array, which I suspect had been replaced by one wee little PC with a pair of 1TB 3.5″ hard drives (or four 500 gig if they were pinching $) and a tape backup.
In the 70’s there was also mandatory maintenance on HDDs. The heads crept forwards and so would become misaligned. So about every 3 months the heads needed to be realigned using a master (CE) disk pack. Maintenance was a forgotten cost, and it was a significant cost too!
I found a old bill sorting out some papers a few months ago. About $100K for (a total) of 32GB of hard disks.
But if the author hasn’t had failures, he hasn’t been using them much. If you have 6 disks in your pc (not uncommon till recently), assume a failure prob of 2% per disk, over a 5 year period you have about a 50/50 chance one of the disks will die.
I have more disks than that, and it would be an unusual 3 year period that I don’t have a disk die (and I buy the best disks I can).
Don’t start. For enlightenment, have a look at the operations manuals for some IBM storage clusters.
They’re also good for bird scarers. Just like CDs, but more durable.
Recently my primary failure mode for HDDs is dropping them accidentally. I’m really starting to wish RDX was as cheap and common as it should be, or that LTO was practically priced for home use.
Some of the earliest SCSI drives were MFM/RLE drives with an adapter board. Those would actually perform a low-level format. But it didn’t last long once integrated drive controllers happened. It also happened with IDE, but that might still have done a low-level format for a couple more years, until devoting an entire side to servo tracks became a thing for a while. Eventually disk formatting became more complex, and CHS was just another way to specify a block address.