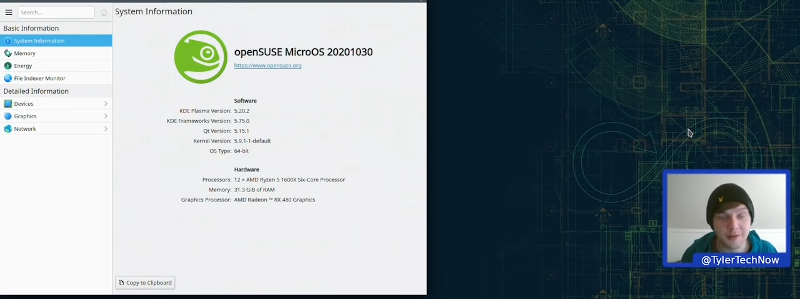
Linux finds a lot of uses in computers that aren’t desktops. But there is a problem. What happens if your mission-critical control computer or retail kiosk gets an update and then fails? Happens all the time with Windows and it can happen with Linux, too. The openSUSE project has an answer: MicroOS which bills itself as immutable. Aimed at container deployment, the operating system promises atomic updates with no disk changes during runtime. If an update does break something, the BTRFS file system allows you to roll back to a previous snapshot. [Tyler] installs the OS and gives it a walkthrough in the video below.
As [Tyler] found, there are not many applications installed by default. Instead, you are expected to install flatpaks so the applications live in their own containers, isolated from the operating system and each other.
Of course, this isn’t for everyone. On the other hand, there is something seductive about having a computer that is very reliable even in the face of updates. Of course, you can do snapshots with BTRFS or ZFS anywhere those are supported, but unless you are very careful, you might have problems with dependencies for applications and the wrong update can still ruin your day. The OS supports GNOME or KDE, with system requirements that claim you can run it in 1GB of RAM and 20GB of disk space. We’d imagine you’ll be happier if you have more, of course.
If you are interested in snapshot file systems for the PI, you can play with BTRFS on that platform. We imagine you could develop some super robust system using FUSE, too, if someone hasn’t already done it.














Another approach is what Guix and Nix have been developing: functional package management. This creates a deterministic image by on the packages selected.
I’ve been using Nixos on everything but by gaming rig for years. The learning curve is very steep but it’s well worth it. I found the nix pills useful for learning and then searching GitHub for others configs.
I also use home manager for my userland apps. I have been dabbling with flakes for my own derivations. It’s like a package.json and lock file so it’s not tied to the nix mono repo(s) which means I can self host.
I even build docker images using nix for work because bazel is mind bending and alpine is packing up the mess and not reproducable.
Sound like a reliable way to have a clean Trading box.
Loaded with only what you need.
Have to read more…
No only that but just a laptop in general where you want to have some monitoring of the system as you move from untrusted network to another. Not too mention the potentially for low resource usage.
“..having a computer that is very reliable even in the face of updates. ” … It is sad to accept that before we would have written “virus” instead of “updates”, but now we can replace the words ‘virus’ and the results remain the same.
latest one for me is windows 20h2, totally borks my wifi and even system restore to before it didn’t fix it back, also tried a format and fresh install of it and no go there either – so reinstalled build 2004 and prevented further updates till either i get a functional wifi driver for 20h2 or m$ fixes whatever the root cause is (Intel ProSet AC…)
Yeah, I have kinda accepted win10 is a new version of windows 98/ME, where the level of stability we got used to with win2k, xp and win7 is no more. Also, because some kinds of people ( marketing at MS, possibly, but in other places there also ) do not understand or appreciate the need for repeatability in a product. Their constant changes in the interface cause a big inconvenience when training users, or diagnosing issues.
And not only the big ones, even the small. One week the option for changing some setting is in some place and called A, then after an update that shouldn´t mess with it, the setting is called B and was moved to other place. When in other OSs we can have charts to follow, and in some cases can tell the user the steps to do from memory, over the phone, now we basically have to walk to the user, or manage to connect remotely.
And even so, when comparing working X non-working machine, one has a hard time, because due to different update level, settings may not be in the same place. ( or even have the same effect ) .
I was reluctant to leave w7, and maybe I got lucky, but my w10 machines have only crashed once in five years… my w7 crashed at least once a month.
For myself, Windows 10 has been exceptionally reliable. I have described it as “Mac like” in execution. I’m not going to say it’s perfect, but on my particular set of machines, everything “just works”. This includes everything from 10+ year old laptops to self-built desktops. My self built machines have always been ASUS Intel motherboards as the Ryzen hardware that has offered a compelling reason to switch vendors arrived after I built my most recent machine.
I considered Windows 7 to be very reliable and crash free, but my experience with Windows 10 has been completely crash free.
Same here. After an early update took out my video by unchecking a box in the settings, I was worried but have not had any problems since. Win 7 64 is bulletproof though lol. I had machines with years of uptime on that and XP. At work our win10 nearly city block of racks just chew thru anything that gets thrown at them. I really wonder what the breakdown of downtime of 32 bit vs 64 bit Win environments are. I think that might be the rub as pc manufacturers have always shat on folks by providing them with the 32 bit version of windows and bare minimum ram like it has always been. Probably mostly 32 machines getting borked.
This is happening because some idiot Marketing youngster at Microsoft is chipping away at Control Panel trying very slowly (and very badly) to move everything over to Settings.
Why not just release software once it’s done, instead of having people use a half-baked product? Constant updates should not be the norm.
That’s the price you pay for having a computer hooked to the internet.
That isn’t true. I always turn updates off on any operating system I use, and I’m on the internet right now. The risks are overrated.
My local hospital network just had all of its systems wiped out by a ransomware attack. They had to resort to calling up every regular patient to ask about whether they had any appointments scheduled.
The thing about security is that it doesn’t make any difference, until suddenly it makes all the difference in the world. Most of the time, having open security vulnerabilities isn’t a problem, until suddenly there’s a worm or ransomware attack or the like which happens to target that vulnerability.
Right, and I’ve had my credit card information stolen once before. It happens. In the long run though, security vulnerabilities have cost me less time and money (1 day and $0 after sorting it out with my bank) than bad updates have.
Kinda agree, but also that hospital didn´t have what we could call correctly implemented protective measures. Most places will not segregate their networks, or reserve some systems for only some functions, because it is always easier to leave them more open, and not generate support calls, than it is to train people, implement and follow correct procedures.
Many systems have no need to be in any way connected to the internet, or to open machines where people can bring their flash drives to show their dog pictures or connect their cell phones, but it is always easier to deny someday a problem could occur and just do the least work to protect things.
@rogfanther Ok I agree… this is the textbook answer right? Make the hospital network locked down and not connected to the inTERnet but only the inTRAnet…
So that means no remote work at all — no analysis, no reporting, no deploying updates, no helping others, no changing setting, no deployments unless you are from INsIDE the network.. so no WFH unless you have a solid VPN..
And people like to do stuff remote…
Ok so let’s say it’s only an intranet.. every cpu station is hooked up to the inTRAnet.. and can communicate between them.. group policy forbids internet access and flash drives..
All it takes for one node (cpu) to be compromised for the whole network to be attacked.. serious question, what other security measures need to be implemented?
Reliable and timely storage backups should be part of any comprehensive security suite. Not sure why there would not be a robust backup system at a hospital. You could buy all of the gear you needed to for the cost of one lawsuit.
Also, is there no A-Team that just goes and staples these ransomware dbags to the floor with a .45? I mean I did my fair share of scambaiting and complete local network destruction of these losers 10 years ago now. How has no one figured out to stop the users?
If you are forced to use Win10… disabling updates is not easy. Microsoft has placed several “watchdogs” to prevent permanent update disablement. In fact the only solution I have found to work has been to alter a few items in the registry and renaming a couple of the win10 update dlls.
And how has your experience with it been, then ? Have these measures solved the inconveniences of win10 updating itself at the worst moments, and also those very long “black screen moments” when we have to reboot the machine and it sits there, digesting its last load of updates ?
One of the “to-do” itens here on my table is to research exactly about those ways to prevent automatic updates for win10. Too much inconvenience when 30 people have to sit idly, waiting for a machine that decided it would take two hours first thing in the morning to think about its updates. Or dealing with the aftermath when the user gets frustrated or desperate and shuts down the machine ( a couple times ) while it is trying to do its updatey thing.
I took another route; I blocked all the Microsoft domains that host the updates by installing acrylic DNS (local DNS server on windows) and pointing NIC properties to DNS=127.0.0.1.
It has a handy ‘hosts’ format that looks like >domain.com which means every sub-domain that ends with that pattern gets resolved to a set IP (and currently people recommend using 0.0.0.0 rather than 127.0.0.1 as windows gives up faster).
I tend to only do this on my Win10 ‘lab’ virtual machines that I (re)create every few months but never expose to the world and don’t want fundamental behaviors to shift as I clone them. My main office machine I tend to let update itself, as IT would kill me if they found me blocking updates (although they don’t know that the ‘office’ machine they remote into to install software and whatnot is itself a Win10 guest living alongside my ‘lab’ guests..).
Set your connection to the internet as ‘metered’ and you won’t be asked to update at all.
Stop doing new things with your computer and we can fully bake the software.
Deal.
As an ex-Microsoft employee, I can get behind this. 95% bug-free is shipped like it’s 100%.
Continuing ‘updates’ are also part of ‘security’. Having a mutating architecture and topology makes it difficult for ‘hackers’ to reverse engineer something. I have no problems with just incarcerating or shooting anyone who does damage to a system for the sole purpose of dishevelment or profit. These guys that write rootkits and then hold the computer hostage should just be killed. Medical and government systems are prime examples of what damage can be done by people who have no morals or ethics. If you could eliminate that aspect of software engineering to focus more on writing concise, clear, bug free code I think things would work much better. This whole scenario is just one example of how ‘law enforcement’ is one of the bigger exploits in our world today.
Because defining “done” to mean “we know every possible thing someone could do with this software, and have verified behavior in every scenario” would result in software never being released. Expand that to every possible combination of software in an OS, and things get even farther out of hand quickly. Now do that with an open source OS where the components come from a ton of different authors with a ton of different testing procedures.
I’ve actually been a release engineer at SUSE, and you’d be amazed how much testing they do (OpenSUSE testing has a lot of overlap). Things still get through, though a lot gets caught. Taking snapshots of the system is a very good option which allows you to protect yourself from unexpected problems, and from general user errors. Change a config file? Do it in a snapshot so you can easily roll back if it doesn’t work as expected. And you get a full historical audit log to look at if errors aren’t immediately noticed. I left SUSE, but still use read-only root with OpenSUSE Leap on several of my systems because it works.
TLDR: Having zero errors isn’t gonna happen, but having a reliable way to recover from errors is possible. Backups exist for a reason. ;)
“What happens if your mission-critical control computer or retail kiosk gets an update and then fails? Happens all the time with Windows and it can happen with Linux, too.”
Same thing my router does. There’s a bit of firmware that if an upgrade ever fails it presents a bootloader that one can present a new (old) image to install without bricking the unit.
Yeah, the nice thing about this approach is that it just keeps the old version around when you update, and the common data is de-duplicated, so you can roll-back without having to either have enough storage space for two full images, or a separate manual step to recover from an old image. And if you have some kind of watchdog on the boot process, you could even just automatically roll back if the new system doesn’t doesn’t come up and report that it’s healthy within some kind of timeout.
I’m using a similar system with Fedora Silverblue for my main system, and I’m liking it pretty well so far, if I were to build an embedded system in the future I’d definitely consider ostree or MicroOS or the like.
I’ve been using Fedora Silverblue as my main system for a few months now. It uses rpm-ostree for a similar snapshot based install, which rather than using a fancy filesystem like btrfs, just uses hardlinks to provide multiple different views while deduplicating common files.
I will have to say that the Fedora 32 to 33 upgrade was pretty painless, but I am a bit frustrated by the fact that there are now 3 different ways to install software each of which has tradeoffs. I can install using rpm-ostree; that allows applications to have access to the full system, which is useful for system utilities and my main editor. But that installs into a new snapshot, which you then need to reboot into to access the software. Or I can install using a flatpak, which is generally the most convenient for graphical applications (including proprietary apps like Discord), but a bit of a pain for things like editors or IDEs which need access to all of my compilers and libraries. Or you can use Toolbox, which is just a simple interface to spinning up containers using Podman (a Docker alternative), which is the best way to just easily be able to install dev tools and libraries using the full RPM database, but is an isolated environment so it’s a pain if you need root.
Overall, I’d say it’s a fairly good experience, though it has a few rough edges that still need to be smoothed out. As someone who previously maintained an Ubuntu derivative for a hardware appliance, and had to deal with all kinds of problems when doing system updates as well as not being able to roll back if something went wrong, I have to say that I’d definitely choose a snapshot based approach like this for any future embedded systems.
I was going to ask how this MicroOS was different than Atomic Host (and the different flavors) and just remembered that Silver blue is the GUI version of it.
I leave the link for others to checks out. I read many months ago that Red Hat purchased ClearOS and intents to make it work this way for hosting containers, but I have not read any recent news about it.
The idea of the OS is making it reliable. For example, as you apply an update, it will reboot, yes. But if the reboot fails to load, it will got back to the prior version.
https://www.projectatomic.io/
Seems like what Alpine Linux does is more elegant, though it requires more RAM which can be cumbersome for “heavy” set-up.
Can you elaborate on “what Alpine Linux does”? A quick Google makes it look like you just switch to a newer release’s package repo and upgrade your packages from there, which seems like what most traditional package managers do.
I watched Tyler’s video, as always he did a great job.
For now, Fedora silverblue looks more advanced than OpenSuse MicroOS, in terms of immutable OS.
However, both look promising.
I read somewhere that MicroOS will abandon their KDE version, and thus, as for silverblue, there will be only gnome as a DE . Hopefully I read it wrong.
What advantage is this over rolling your own distro? Kernel + Busybox + application. Or using Yocto?
You could use buildroot or linuxfromscratch. But this might even be easier: https://github.com/ivandavidov/minimal and their https://github.com/ivandavidov/minimal-linux-script
Only 20GB really?
Don’t get me wrong, I think most real work can be done in less than 1GB if you choose lightweight software without a lot of extra visual fluff. I remember running computers that did every truly important task and then some with hard drives measured in the MBs.
But with today’s bloated software..
And flatpacks, doesn’t that mean every application has it’s very own copy of every (probably bloated too) shared library…
And the filesystem is keeping how many copies of this in case you need to restore?
In case of btrfs “copy” could be cheap thing – both to create, to store, and to apply as new state. CoW would only store blocks that differ from original ones. Therefore “copy on write” name. That is, initially both copies share all blocks and new “copy” only gets new block allocated if it happens to differ from original. That’s true for both “snapshots” and “reflinks” that are at the end of day are sets of blocks that could have more than 1 reference, unlike in classic fileystem designs that assume block either references once (part of some file) – or not at all (free space). Actually, you can even de-duplicate btrfs to state when it would share certain sets of blocks between some files. It don’t even have to be formally declared “shapshot”. CoW would transparently handle new writes, allocating new blocks as copies diverge.
So vaguely speaking, you can keep quite many snapshots – assuming they don’t diverge too much. Much like it happens in VM software like VMWare or Qemu using CoW “disks” and “snapshots”. But these work on block level and it’s less flexible approach.
So creating snapshot is almost instant. Reverting snapshot is alsmost instant as well. And I’d say I’ve made tiny Debian for ARMs that only takes like 30Mb without GUI (yea, Suse, take that :P) – yet also enjoys btrfs (it’s cool). Though their package list would take yet another 100Mb space – that’s what you get for 20 000 packages in repository.
I also use btrfs in embedded. One of reasons is: it can do DUP storage scheme, raid-1 like but using just single storage, so it merely places 2 copies of data and metadata into different places. Checksums make it quite smart – if one copy goes nuts, it simply repaired from another one. And show goes on. Which is very valuable in embedded uses, btw. Not to mention you get early warning your SD/eMMC/whatever is flaky long before device would fail to boot.
So while I don’t use SUSE, I appreciate their efforts on btrfs. Honestly, it saved me a lot of grey hairs.
SuSE isn’t the first to having an immutable Linux OS. tinycorelinux.net has been doing it for around 15 years. It’s latest release was in April 2020 so it’s still maintained.
Though it has gotten larger in size tinycore’s Core image is *11megs*. If you need more: TinyCore is 16MB while CorePlus is 106MB. There are also extensions (packages) of applications.
The boot from the base image and pivot to run out of RAM. So it’s disk image is immutable unless of course deliberately repackaged.
By the way this is not just command line terminal only. TinyCore comes with X11 extensions. It’s available in x86 32 and 64-bit, for the Raspberry Pi, and for allwinner a10 & a20.
At the moment doesn’t do flat packs, containers, Etc out of the box.