In the old days, big computers often had some form of external array processor. The idea is you could load a bunch of numbers into the processor and then do some math operations on all of the numbers in parallel. These days, you are more likely to turn to your graphics card for number crunching support. You’ll usually use some library to help you do that, but things are always better when you understand what’s going on under the hood. That’s why we enjoyed [RasterGrid’s] post on GPU architecture types.
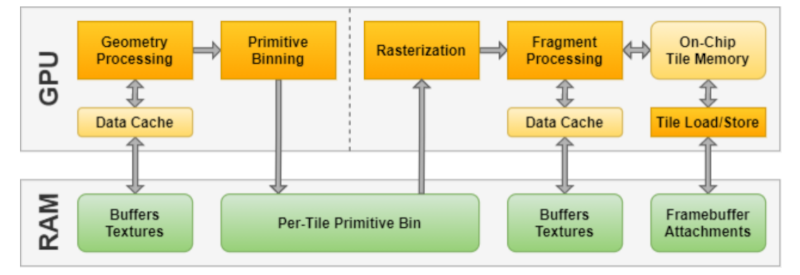
If you can tell the difference between IMR (immediate mode) and TBR (tile-based) rendering this might not be the post for you. But while we knew the terms, we found a lot of interesting detail including some graphics and pseudo code that clarified the key differences.
Which architecture is better? As the post points out, that depends on how you define better. Each can boast it is better at something, but the flip side is that each is also worse at something else. In general, IMR GPUs wind up in desktop computers and mobile devices tend towards TBR. It also depends on the specific task you ask of the GPU.
Granted, you normally don’t need to know any of this. For graphics, you are probably not directly controlling the device and for computation, you will likely use CUDA or OpenCL. But you don’t need to understand an engine to drive a car, but the best-performing drivers do know how an engine works.














Woo! ROCm!
“If you can tell the difference between IMR (immediate mode) and TBR (tile-based) rendering this might not be the post for you.”
Pepperidge Farm remembers the Kyro. Impressive graphics for the time.
I am an inefficient space heater.
Pulled mine for Earth Day, but only then realised how good a job it was doing.
I am a tilemap and sprite based GPU. <3
OpenCL is “portable” between architectures, but not performance-portable. One must have a deep understanding of a particular GPU (or any other compute device) architecture in order to write an efficient OpenCL code…
I am TMS9128.
Quite the article on the other side of that first link.
An interesting read to say the least.
Graphics rendering both 2D and 3D is interesting topics and there is plenty of ways to approach the problem of generating a final 2D output image from some dataset.
Though, it is a good question if one can honestly split the whole concept of rendering into just two categories. But I don’t study graphics processing, I spend my time developing CPU architectures as a hobby, so graphics isn’t innately a strength of mine.
As yes. The IBM 3838. Got a lot of mileage from that before the Cray showed up. Never had the chance to use a Floating Point Systems box.