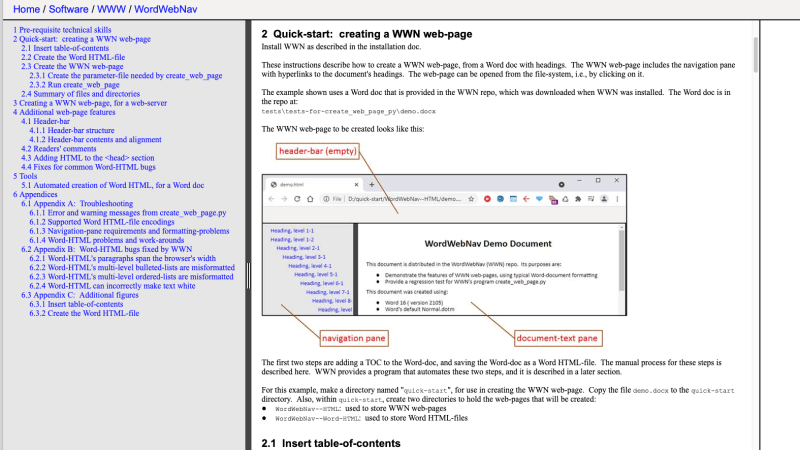
If you’ve ever examined the messy HTML that results from doing a Save As HTML from Microsoft Word, you can appreciate [Jim Yuill]’s motivation for his WordWebNav (WWN) project. [Jim] uses Word to document his technical projects, and wanted an easy way to generate web pages. Not only is Word-generated HTML nearly unreadable, [Jim] notes there are known bugs, as well. His project attempts to solve these shortcomings, and adds new features like a navigation pane and headers, among others. Here is a link to a dummy project which shows off these features.
There are, of course, other ways of generating web pages from your technical documentation — there is the Markdown / Pandoc combination, various Wiki solutions, or GitHub Pages, for example. If you’re Python-focused, there’s always the Jupyter Notebooks / JupyterLab approach which we wrote about in 2019. But these presume the source documents are in a certain format. If you have years of existing documentation in Word, or you prefer (or are required) to use Word, [Jim]’s WWN tool might be of interest.
The open source, Python-based program can be found in the project’s GitHub repository. [Jim] has a lot of experience writing software, and the clean and well-organized source code reflects this. Do you convert project documentation to HTML for browsing, be it local or online? If so, share your techniques in the comments below.














Hint: use TeX.
Hinthint: LaTeX ( Texstudio is my preferred editor)
Plain TeX is… *Tilt*
IMO, the best way to publish and distribute a lengthy technical document in MS Word is to print it to a PDF. I find it annoying when I stumble upon a technical document worth saving/archiving and it’s presented in HTML – damn awful to print too.
Bring back FrontPage Express!
/passes out
*plasters everything with “Proudly made with Notepad” buttons*
*ahem* notepad++
edlin or bust. Had a co-orker who wrote a term paper in high school with it.
Word is great for normal text, but terrible for technical papers. I had lost count of how many times I got a script from Word and all dashes and quotes are helpfully changed.
I use Markdown for that, it’s made for it. TeX works too, but it’s way more easy to learn Markdown. I reserve TeX for scientific papers.
Back in the day, I had a Markdown++ that I’d do academic work with, and a Python pre-processor that would turn it into either Latex for publication or Beamer/Latex for presentation, depending.
It was all hacks and regex text substitutions, but it make life easy.
Then along came AsciiDoc, which basically sorted that whole biscuit. https://asciidoc.org/
The html files created with WordPerfect are completely fine.
20-ish years ago, whatever was the then latest (and last from whomever was the owner of Word Perfect at the time) Word Perfect for Windows was completely useless for HTML. I started a simple document and saved it. When I re-opened it, it was a horrible mess. I closed it then opened the HTML file in Notepad. I dunno what Word Perfect did but it was like the transporter incident in that early Star Trek movie.
The HRML word spits out is awful, and each version is slightly different, but (within a version) it is consistent.
I worked on a big project to convert hundreds of large word docs to HTML, and later to a domain-specific markup language.
The key things are:
– make sure your word doc is consistently formatted. It’s generally much easier to fix that in word than later.
– use styles! It makes conversions much easier
– double-check everything at every stage, and at the end do a text comparison with the original doc.
Technically, we used a mix of word macros to scan for and fix word formatting issues, Perl scripts for the bulk of regexing (fixing up word’s html, removing spurious rubbish from the files, and some sanity and internal consistency checks), and nodejs for manipulating the DOM and final consistency checks.
*HTML
… please can we get an edit button?!
I dunno HRML seems a pretty good description of Word’s HTML :-) Hyper Really Messy Language
HaRMfuL
For the love of whatever, don’t use UTF-8 or any other multi-byte representation (such as “HTML Friendly” codes that start with an ampersand) of any character that’s in the extended ASCII set. Except for one character in Norwegian, every character for any language whose alphabet is based on the English alphabet is in Extended ASCII, and that includes things like left and right single and double quotes. I’ve run into a large number of documents where for some reason ALL punctuation was there with multi-byte encoding. Why? Who the heck knows because there was no reason at all to have it that way.
I had to convert them for PalmOS software and nothing on PalmOS supports Unicode, so without pre-processing away the multi-byte characters, the punctuation would either all come out as ? or would get removed and replaced with nothing, not even a space.
Back in the day I would have happily paid money for software to add Unicode support to PalmOS 5.
For gits and shiggles I’d like to see an entire HTML document converted to UTF-8 codes, WITH the leading zeroes that are optional for character numbers under 1000. Displaying such should be part of the ACID web browser test.
These are good suggestions.
They take me back to 2001 or so, when a new intern’s CV included HTML/web development experience, which we quickly realized consisted of formatting in Word to get the desired look, then saving as HTML. Since she was an intern, it wasn’t the end of the world, and devoting time for training is part of the job.
The issue I used to see was that most colleagues (and I) were trained in Word at Jumprightin U, seldom used styles or constant formatting, and kept reformatting individual portions of a document until it passed muster on a printer.
There I was, thinking golf was the archetypal “invented by sadists, for masochists” activity
I had never considered converting a Word doc to HTML (ahem! HRML) before reading this article.
So, I opened a recent Word doc to Save As: an HTML file, just to see how “bad” it could be.
I did not see an HTML option, just a couple XML options, and the one I tried didn’t turn out bad.
The doc had a number of photos and a couple of tables along with the text, but it was still readable…
Oh, come to think of it, the file I used didn’t have any URLs…
LibreOffice Writer supports exporting as HTML.
Plus LibreOffice is free, open-source, cross-platform, available with an installer or portable, and it doesn’t spy on you. I’m very experienced with both Microsoft Office and LibreOffice, and I struggle to understand why someone would prefer Microsoft Office, especially since Microsoft is data harvesting for money and clearly moving toward a cloud-based SAAS business model. Before it’s too late, jump off the Microsoft Office train now so you can ease into LibreOffice at your own pace.
It’s better than copy con>whatever.html or whatever the syntax used to be, but it’s something I’d rather do on pre-aol Netscape as opposed Word
Back in the day I used to write autoexec.bat and config.sys with Edlin and low level format hard drives with debug.
Irrelevant, incompetent and immaterial.
Heard the saying “every day I don’t have to wear a suit is a good day”? I feel the same way about Word. If I’m using Word (or another word processor), it means I’m doing something I’d rather not be doing.
There are many better tools than Word for web pages. For electronic distribution of more formal and/or printable docs, PDF is my preference. (but probably composing in Word or Open Office [sad face] then converted)
I’m annoyed at how rare it is to see a pure-HTML word processor. 99% of what I’ve ever done in a word processor could be done in HTML4 with a small chunk of CSS to make it all pretty. Even fancy things like Word’s auto-outline function could easily be done with HTML and some basic parsing. Especially since HTML can be viewed on the vast majority of computing devices nowadays, and if you can mentally parse HTML, on pretty much any computing device ever created.
Some years ago, I had a word processor that did exactly that, it just used HTML as it file storage format, the top of the file contained some CSS to define the various styles and formatting used in the document. The program itself was a tiny statically compiled binary that produced some very clean HTML. The version I had was forked and rebranded by my employer, and I’ve completely forgot what the original was called.
Could we all just Markdown, mmmkay?