
I’ve tried a lot of the “newer” languages and, somehow, I’m always happiest when I go back to C++ or even C. However, there is one thing that gets a little on my nerves when I go back: the need to have header files with a declaration and then a separate file with almost the same information duplicated. I constantly make a change and forget to update the header, and many other languages take care of that for you. So I went looking for a way to automate things. Sure, some IDEs will automatically insert declarations but I’ve never been very happy with those for a variety of reasons. I wanted something lightweight that I could use in lots of different toolsets.
I found an older tool, however, that does a pretty good job, although there are a few limitations. The tool seems to be a little obscure, so I thought I’d show you what makeheaders — part of the Fossil software configuration management system. The program dates back to 1993 when [Dwayne Richard Hipp] — the same guy that wrote SQLite — created it for his own use. It isn’t very complex — the whole thing lives in one fairly large C source file but it can scan a directory and create header files for everything. In some cases, you won’t need to make big changes to your source code, but if you are willing, there are several things you can do.
The Problem
Suppose you have two C files that cooperate. Let’s say you have A.c and B.c. Inside the A file, you have a simple function:
double ctof(double c)
{
return (9.0*c)/5+32.0;
}
If you expect to use this inside file B, there needs to be a declaration so that when you compile B, the compiler can know that the function takes a single double argument and returns a double. With ANSI C (and C++) you need something like:
double ctof(double c);
There’s no actual programming, just a note to the compiler about what the function looks like. This is what you call a prototype. Normally, you’ll create a header file with the prototype. You can include that header in both A.c and B.c.
The problem is when you change the function in A.c:
double ctof(double c1, int double c2)
{
return (9.0*(c1+c2))/5+32.0;
}
If you don’t change the header to match, you’ll have problems. Not only that, but you need to make the same change. If you make a mistake and mark the arguments as floats in the header, that won’t work either.
The Program
Assuming you’ve installed the software, you can simply run it passing all the C and H files you want it to scan. Usually, the glob *.[ch] will do the trick. You can also use it with .cpp files and even a mix. By default, this will pull all the global variable declarations and global functions you define into a series of header files.
Why a series? The program makes an odd assumption that makes sense once you think about it. Since the headers are automatically generated, it doesn’t make sense to reuse the headers. Instead, each source file gets its own customized header file. The program puts in what is necessary and in the right order. So A.c will use A.h and B.c will use B.h. There won’t be any cross-dependency between the two headers. If something changes, you simply run the program again to regenerate the header files.
What Gets Copied?
Here’s what the documentation says gets copied into header files:
- When a function is defined in any .c file, a prototype of that function is placed in the generated .h file of every .c file that calls the function. If the “static” keyword of C appears at the beginning of the function definition, the prototype is suppressed. If you use the “
LOCAL” keyword where you would normally say “static”, then a prototype is generated, but it will only appear in the single header file that corresponds to the source file containing the function. However, no other generated header files will contain a prototype for the static function since it has only file scope. If you invoke makeheaders with a “-local” command-line option, then it treats the “static” keyword like “LOCAL” and generates prototypes in the header file that corresponds to the source file containing the function definition. - When a global variable is defined in a .c file, an “
extern” declaration of that variable is placed in the header of every .c file that uses the variable.
When a structure, union, or enumeration declaration or a function prototype or a C++ class declaration appears in a manually produced .h file, that declaration is copied into the automatically generated .h files of all .c files that use the structure, union, enumeration, function or class. But declarations that appear in a .c file are considered private to that .c file and are not copied into any automatically generated files. - All #defines and typedefs that appear in manually produced .h files are copied into automatically generated .h files as needed. Similar constructs that appear in .c files are considered private to those files and are not copied. When a structure, union, or enumeration declaration appears in a .h file, makeheaders will automatically generate a typedef that allows the declaration to be referenced without the “
struct”, “union” or “enum” qualifier.
Note that the tool can tell when a header is one it produces, so you don’t have to exclude them from the input files.
A C++ Example
For things like C++ classes — or anything, really — you can enclose a block of code inside a special preprocessor directive to make the tool process it. Here’s a very simple example I used to test things out:
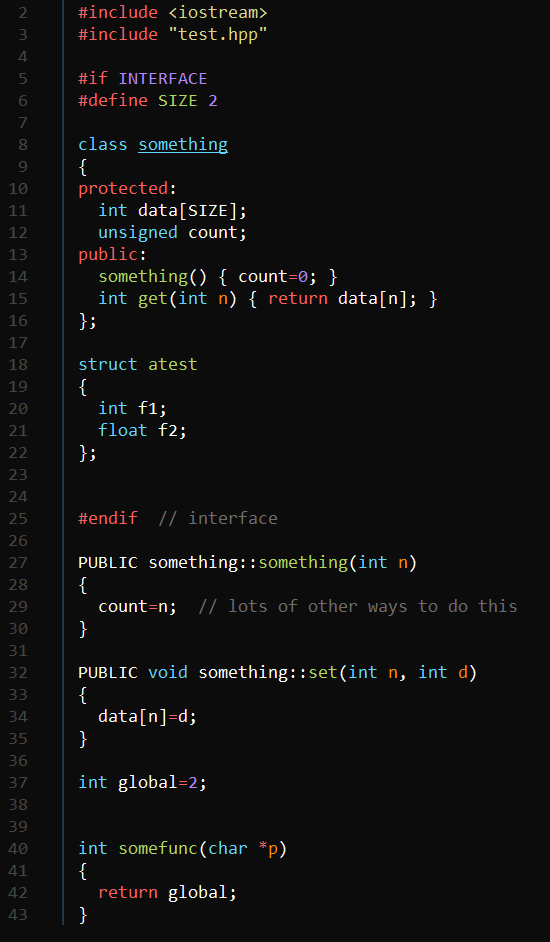 A few things to notice. First, the include for test.hpp will grab the generated header file specific to this file. The
A few things to notice. First, the include for test.hpp will grab the generated header file specific to this file. The INTERFACE directive wraps the code that should be in the header. At compile time, INTERFACE will equal zero, so this code won’t compile twice.
The member functions declared outside of the INTERFACE section have PUBLIC in front of them (and could, of course, have PRIVATE or PROTECTED, as well). This will cause the tool to pick them up. Finally, notice that there is a global variable and a global function at the bottom of the file.
Notice that when using PUBLIC or the other keywords that you omit the functions from the declaration. The only reason the example has some functions there is because they are inline. If you put all the functions outside the interface section of the file, the generated header will correctly assemble the class declaration. In this case, it will add these functions to the ones that are already there.
The Generated Header
The header seems pretty normal. You might be surprised that the header isn’t wrapped with the usual preprocessor statements that prevent the file from being included more than once. After all, since only one file will include the header, that code is unnecessary.
Here’s the file:
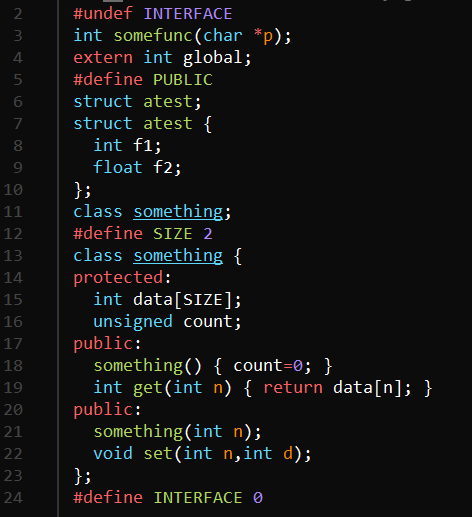 Notice that
Notice that INTERFACE gets set to zero at the end, which means in the source file, the interface portion won’t get compiled again. For C source, the tool also generates typedefs for things like structures. For C++ this is unnecessary, of course. You can see the byproduct of having some declarations in the interface section and some in the implementation section: there is a redundant public tag. This is harmless and wouldn’t appear if I had put all the code outside the interface section.
There’s More
There’s more that this versatile tool can do, but you can read the documentation. There’s a flag that dumps information about your code you can use for documentation purposes. You can build hierarchies of interfaces. It also can help you mix C++ and C code. The tool is smart enough to handle conditional compilation. Note, though, that the C++ support doesn’t handle things like templates and namespaces. You have the source, though, so you could fix that if you like. There are some other limitations you should read about before you adopt this for a big project.
Will you try a tool like this or are you happy with manually handling headers? C++ can even target web pages. Or, use it for shell scripts, if you dare.














The header is part of your documentation. It’s a good place to put module descriptions, list the class-local variables, list the public function calls, and put any usage notes. Also a copyright notice of some sort. Don’t make other users slog through your code trying to figure out how it works, cultivate a habit of communication using the header file as the medium.
Auto generating the header file is doing things the wrong way around. You should *start* with the header file, comment it and nicely lay out the structure, and have that file generate the .cpp file by duplicating the definitions of the class functions. Then then fill in the .cpp code. Often this is just copy/pasting the function definitions into the .cpp file, and adjusting that tabs.
Instead of auto generating the header file, make the header the focus of your effort: assume the header is the primary source, and change the code to accurately implement the header. (Not the other way around.)
Then you can use the header to auto-create the documentation.
As an aside, if you can sustain the discipline to do this your code will become exemplary, which will help you succeed in any endeavour that uses code – such as your job. It’s a bit of work to do this, though. You have to look at code as an act of writing or communication instead of computer instruction. Not many coders have the discipline to do this.
I also really like headers as documentation.
In the libraries that I’ve most enjoyed using, the headers can give you the bird’s eye view of the project without having to slog into the implementation. Often a list of well-named functions and data structures, plus maybe some good notes, is all you need to get going.
Thinking through the scope of what goes inside each header can also be a useful discipline, which this tool sidesteps.
Of course, if your editor does code-folding, you can turn the .c file into a .h equivalent, as far as providing that roadmap functionality goes. Maybe that’s why the .h file has been reduced to a bit of boilerplate.
But for myself, I think of the .h files as where the architecture and design goes, and the .c files as where the necessary grunt work is carried out.
You miss the point. If you create the header file first you still need to manually sync the changes between your source file and your header file. And the compiler doesn’t check many things (parameter names, unneeded includes, etc). Header files contain a lot of boiler plate.
One does not really need header files with C. Seems to me that you miss the point about code maintainabilty and program modularity.
I find it very odd for someone to diss header files.
double ctf(double c);
I think you meant to s/ctf/ctof/
Minor typo, but may cause some head scratching.
i agree that the process of creating separate declarations is a little tedium of almost no value. however, i disagree with the idea that the cost of providing declarations really matters. sometimes a project has been so poorly architected that you waste time wondering which .h file to insert the declarations into, but actually generating the declarations is not time-consuming. it doesn’t impose a cognitive load. and most importantly, it isn’t error-prone because the declarations are all cross-checked by modern compilers (that’s their whole point, after all). and it isn’t entirely useless, because it is good to have a little formal thinking about how much should be exposed to other compilation units or modules.
so i’m lukewarm on the idea of automatically-generated headers. the headers i generate are so simple they really could be automatically-generated, but i just don’t think there’s much to gain there. amdahl’s law and all that. you focus on the problems that are hard, not the ones that don’t matter. i find C headers slightly less obnoxious than the flood of import statements at the head of every java source, and even those don’t bother me enough to make it onto a list of why one language is better than another.
but i *hate* this tool’s idea of making valueless headers. there should not be a new declaration of everything every place it’s used from. a good tool should automate the process you want to do, rather than perform another inferior process opposed to the good sense of the language’s design. the requirement to rebuild *all* of the header files each and every time gives you a little build overhead (which matters! half-seconds matter in repeated build-test cycles), but also guarantees that as your development environment changes, you’re going to be fighting with this damn tool. you won’t just leave header files in git and re-generate them one at a time as needed, so when this tool breaks for any reason, you’ll be SOL. fixing this tool will become your primary action item.
The tool is from 1993, its not a part of the update fetish we have nowadays. Therefore you dont have to deal with ‘when this tool breaks for any reason’. It does what it does.
I believe that the second version of the function is not what you intended. I probably should be:
double ctof(double c1, int double c2)
{
return (9.0*(c1+c2))/2.0+32.0;
}
Note that I divided by 2.0 instead of f.
I don’t know how I did that. Both versions divide by f but should divide by 5 (fixed now). As Bill Murry once said, I really shouldn’t have drunk so much cough syrup. ;-)
Oops, I was wrong. Actually, the second version should divide by 10. 5 for the temperature conversion times 2 for the average (assuming that the second is trying to convert an “average” temperature).
No it was just a made-up example so I intended to just sum the readings to get the total temperature not average them. But it was still wrong lol
what’s “int double c2” exactly? Shouldn’t it be either one or the other? :)
Header is the abstraction of the module, makes it black box, hides the details.
I wish that were the case. In C++ you need to expose all the members of your class including private members in the header file. So much for privacy…
And if you want to use constexpr methods you need to put the implementation in the header file too. So much for black box…
Headerfiles are boilerplate: duplication of function prototypes, include guards and extern “C” declarations. It is good practice to include all the needed header files in the header file too, that too is added and maintained manually and unneeded includes are often not removed… Often the doxygen-style comments for functions are exact copies from the source files (or worse, they differ). And often many files share the same license text template (often in ugly Christmas-lights style ****-comments ). Often source files have their filename in a comment at the top (why would you need that?).
Generated header files are a welcome feature, but I prefer not to use language extensions.
> The problem is when you change the function in A.c:
> (…)
> If you don’t change the header to match, you’ll have problems.
That’s why implementation file should include its corresponding header file so that the compiler complains if you change anything.
Oh, and you should use -Wmissing-prototypes so that the compiler complains if you don’t add the header file.
Ooh, and in C you should use “void” in parameterless functions so that compiler complains if you add parameters to implementation and forget the declaration or if you add parameters to function call.
Oooh, and you should use -Wstrict-prototypes so that the compiler complains if you don’t.
Ooooh, now I see why some people like languages such as Java and C#…
Exactly. C/CPP files should include their own header files first and you should enable those warnings you said. But that is not enough: the compiler doesn’t check the names of the parameters, which could lead the user to pass the incorrect arguments.
Right, I forgot that own header file should be included _first_ so that it’s easy to notice missing includes in the header and avoid indirect inclusion.
Why not switch to Rust and forget all that faffing with headers ?
Along the way, Rust adresses plenty more of C/C++ problems.
Unfortunately it actually doesn’t, and that’s why people still use and prefer C and C++.
I’d love to, but my target platforms are invariably a few hundred bytes of RAM with 2k of ROM.
C++ should have ditched header files long ago. Perhaps, only keeping them as an option.
LZZ is the same idea, but for C++. You write .lzz files (or whatever extension you want), the LZZ tool splits it into one .cpp and one .h file as part of compilation.