Should you wish to try high-quality voice recognition without buying something, good luck. Sure, you can borrow the speech recognition on your phone or coerce some virtual assistants on a Raspberry Pi to handle the processing for you, but those aren’t good for major work that you don’t want to be tied to some closed-source solution. OpenAI has introduced Whisper, which they claim is an open source neural net that “approaches human level robustness and accuracy on English speech recognition.” It appears to work on at least some other languages, too.
If you try the demonstrations, you’ll see that talking fast or with a lovely accent doesn’t seem to affect the results. The post mentions it was trained on 680,000 hours of supervised data. If you were to talk that much to an AI, it would take you 77 years without sleep!
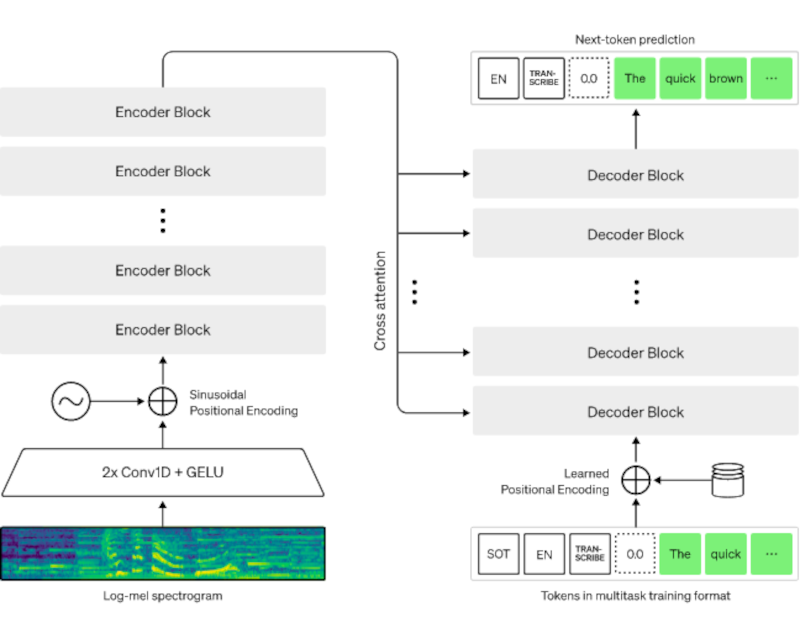
Internally, speech is split into 30-second bites that feed a spectrogram. Encoders process the spectrogram and decoders digest the results using some prediction and other heuristics. About a third of the data was from non-English speaking sources and then translated. You can read the paper about how the generalized training does underperform some specifically-trained models on standard benchmarks, but they belive that Whisper does better at random speech beyond particular benchmarks.
The size of the model at the “tiny” variation is still 39 megabytes and the “large” variant is over a gig and half. So this probably isn’t going to run on your Arduino any time soon. If you do want to code, though, it is all on GitHub.
There are other solutions, but not this robust. If you want to go the assistant-based route, here’s some inspiration.














Perfect… now to couple this to a text-to-speech engine, a SIP client and a copy of the old PARRY program… and I’ve got something to torment the NBN scammers with.
It has to be able to understand then first
I dunno if it’s a real disadvantage… it understands them to be calling about duck cleaning and it goes on a rant about only having geese…
Exactly… I think understanding the caller (who is talking crap in this case about “errors” they’re receiving) matters very little.
It’ll be a matter of seeing if I can rack up a high-score keeping the thieving bastards on the line. The more time they spend talking to a ‘bot, the less time they spend scamming more vulnerable targets.
Not to mention if they are initiating a phone call it should actively cost them money!
Seems like a great wheeze to me, as long as you don’t actually need your phone while they are wasting their time and your chatbot’s valuable CPU cycles…
Holy cow! I actually managed to get this working, and it’s actually pretty decent at making subtitle files, even translated ones! :D
Not going to run on an Arduino lol.. I don’t think translating human speech ever will, not nearly enough muscle.
You say that but some Arduinos can literally use MicroSD. Which is 1 TB currently and will soon be 2 TB.
“So this probably isn’t going to run on your Arduino any time soon.”
It already could if we are talking about only a gig and a half.
Of GPU memory.
I agree, nobody needs to run speech recognition on a 16mhs 8bit processor with 2k ram!
But what about those running Arduino SoC dual core 32bit 240Mhz with 512kb ram and 512Mb storage?
I would be the dare devil and say possibly. If it is only read access to that data and has some quick search tree n log n it could be possible. You can get at least some 8MB read speed on esp32 Tf card. It would be a very custom job though so I do not think anyone is actually going to bother…
How long will it take to appear in Debian and Rpi distros?
MIT license, which is nice, but I’m suspicious about hidden loopholes. This is **openai**, remember? As soon as MS decides there’s enough developer uptake, they’ll probably find a way to close it back up again. I’d very carefully scrutinize any tech that came out of there.
That sounds like volunteerism to me!
Mental Outlaw had a nice demonstration of this on his YouTube channel
I thought this was about really whispering. I remember a Korean cell phone one of my colleagues had about 20 years ago had a “whisper” mode. You could whisper into the phone and the other party on the call could hear you like usual. I never knew if it utilizes special signal processing or just cranked up the gain really high. Alas I only ever saw that feature on one phone and never again.
I tried this on a 2 Core 3Ghz CPU only machine. Took a long time to transcribe. Pretty decent results, I used the wav files that came with Codec2. Whisper made just one error (red vs rare in Chicken is a rare dish) with the Tiny English Model. Impressive! Tried it with my own voice with a lot of noise (I was near a construction site with loud machines in the background), downsampled to 8khz – results were not impressive, but after a pass of rnnoise it worked out fine! So if your input is low fi and has noise, passing it thru rrnoise or audio/supersampling / bandwidth extension tools will help a lot in accuracy. My overall review is that this is NSA quality voice transcription. Recommend to use the larger models and with GPU. This doesn’t seem to work at all if voice has already been passed thru a speech codec such as codec2 as much of info is lost. Inference is probably looking for subtle hints that disappear when passed thru filters and codecs. The result was a totally different transcription. My next experiment is to train / evaluate a model for audio super resolution / bandwidth extension with https://github.com/galgreshler/Catch-A-Waveform and https://github.com/kuleshov/audio-super-res . I’ll use Low fi https://github.com/drowe67/codec2 output and High Res Originals, in the end’ll see if whisper can transcribe the results. But for that I need a weeks access to a GPU server which I don’t have access to now – so for later.