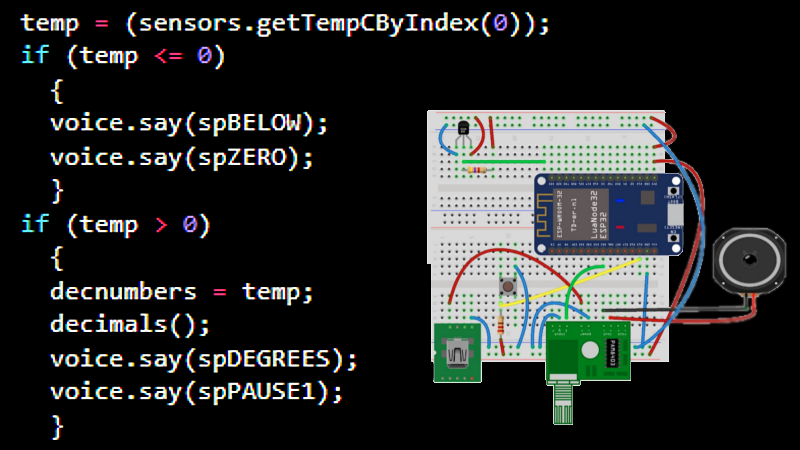
80s-era electronic speech certainly has a certain retro appeal to it, but it can sometimes be a useful data output method since it can be implemented on very little hardware. [luc] demonstrates this with a talking thermometer project that requires no display and no special hardware to communicate temperatures to a user.
Back in the day, there were chips like the Votrax SC-01A that could play phonemes (distinct sounds that make up a language) on demand. These would be mixed and matched to create identifiable words, in that distinctly synthesized Speak & Spell manner that is so charming-slash-uncanny.

Nowadays, even hobbyist microcontrollers have more than enough processing power and memory to do a similar job entirely in software, which is exactly what [luc]’s talking thermometer project does. All this is done with the Talkie library, originally written for the Arduino and updated for the ESP32 and other microcontrollers. With it, one only needs headphones or a simple audio amplifier and speaker to output canned voice data from a project.
[luc] uses it to demonstrate how to communicate to a user in a hands-free manner without needing a display, and we also saw this output method in an electric unicycle which had a talking speedometer (judged to better allow the user to keep their eyes on the road, as well as minimizing the parts count.)
Would you like to listen to an authentic, somewhat-understandable 80s-era text-to-speech synthesizer? You’re in luck, because we can show you an authentic vintage MicroVox unit in action. Give it a listen, and compare it to a demo of the Talkie library in the video below.














I like it :)
Years ago I played with one of those phoneme chips driven by a 6511AQ running FORTH.
This looks like a good thing as I have a friend with low sight.
Changes for ESP-32: Original code was spending too much time in an interrupt handler which the ESP32 hates. And use of the DAC instead of PWM because—why not.
” too much time in an interrupt handler which the ESP32 hates ” they all do.
Interesting. I put together a ESP32 with an audio playback device and pre-programmed it with audio segments for numerical readout. Not a difficult task as it’s just playback and driving the files dynamically. I didn’t know about the talkie library. Might play with that next. Like the retro feel.
“Back in the day, there were chips like the Votrax SC-01A that could play phonemes (distinct sounds that make up a language) on demand. These would be mixed and matched to create identifiable words, in that distinctly synthesized Speak & Spell manner that is so charming-slash-uncanny.”
Just…..Wow. No, no, no.
Speak and Spell sounds were not synthesized it played back very, very lossily compressed audio. All the sounds were audio recordings made by Mitch Carr, a radio announcer that TI hired to record the samples. The distinct electronic sound of the speak and spell was compression artifacts.
Using a Votrax to string Phonemes together was a completely different sound. And not that “distinct synthesized speak & spell manner”.
Why is it so hard for HAD to find people who know the most basic things about what they are writing about. Do you really think it’s better to make things up in your head about topics you know nothing about rather than spend 30 seconds with Google?
And to be clear, Speak and Spell played back complete words and phrases. Nothing was done with speak and spell by stringing together Phonemes.
Spend a few seconds more, and you’ll find that the Speak and Spell used the TI TMC0280 (also known as the TMS5100) to synthesize the spoken words. The TMC0280 used phonemes stored in ROM to synthesize the words. The English words were recorded in Dallas then processed into phonemes. Other languages were recorded in Nice, France then sent to Dallas to be converted to the needed phoneme data and sent back for corrections and further work.
The Speak and Spell did not merely use prerecorded sounds. It used a synthesizer that worked from phonemes generated from recordings.
Modern synthesizers do something similar. They start with a large body of recordings from while individual sounds and sound sequences are clipped. These are then used to make the phonemes that are used in the synthesizer. They generally use more than simple phonemes – they will include phoneme pairs in order to make the transistions more natural.
Speak and Spell: https://en.wikipedia.org/wiki/Speak_%26_Spell_(toy)
TI speech synthesis chips: https://en.wikipedia.org/wiki/Texas_Instruments_LPC_Speech_Chips
Linear predictive coding: https://en.wikipedia.org/wiki/Linear_predictive_coding
Soc Rat is 100% correct. The Speak and Spell truly did “merely use prerecorded sounds”. It did NOT use phonemes in any way. The speech part of the ROM only contained entire words. For the S&S to gain any vocabulary, you had to buy additional cartridges which contained more complete words. We all agree that phonemes allow for arbitrary words to be generated. Many have tried to hack the S&S to say new words, but nothing short of generating new and complete LPC-encoded words/phrases has ever been successful.
Hack-a-day even covered another project on this topic:
https://hackaday.com/2012/12/03/teaching-the-speak-spell-four-and-more-letter-words/
If someone does want to use a phoneme-based speech synthesizer on the ESP32, definitely look at the ESP8266SAM Arduino library:
https://github.com/earlephilhower/ESP8266SAM
Soc Rat is 100% correct. The Speak and Spell truly did “merely use prerecorded sounds”. It did NOT use phonemes in any way. The speech part of the ROM only contained entire words. For the S&S to say anything different, you had to buy additional cartridges which contained more complete words. We all agree that phonemes allow for arbitrary words to be generated. Many have tried to hack the S&S to say new words, but nothing short of generating new and complete LPC-encoded words/phrases has ever been successful.
Hack-a-day even covered another project on this topic over ten years ago where the author endeavored to add bad words to the vocabulary. They had to record, encode, and put the new sampled words into a new ROM.
What you’re describing as the way “modern synthesizers” work was broadly true 10-20 years ago, but these days, state of the art systems tend to use deep learning based synthesis: https://en.wikipedia.org/wiki/Deep_learning_speech_synthesis
Yes, this struck me as well — Speak & Spell was LPC, not synthesized e.g. Votrax or SP0256 etc.
Thanks for the Mitch Carr tidbit.
I did make a quick-and-dirty SP0256-AL2 simulation once with a BluePill. It was simply recordings of the phonemes rather than implementing the actual digital filter. Still, it worked surprisingly well, and low resources.
To be fair they aren’t any worse than ChatGPT. Hmmmm….
While you could get a chip from Radio Shack that would speak with phonemes, Atari 8-bit computers had a program called SAM (software automatic mouth). No hardware was needed and it was fairly understandable. Reminded me of an old man with sinus congestion speaking.
Yes! My exposure to the SAM program was on the C64. Good memories. By the way, the code has now been ported to the ESP8266/ESP32 in the form of the ESP8266SAM Arduino library. It works great, complete with the software knobs you need to recreate your favorite voices like the little elf, strange alien, little old lady, and of course the stuffy old man!
Talkie looks like a pretty nifty library, although the “Danger Danger” from the example on github made me think of Lost In Space.. “Danger Will Robinson! Danger!” :D
Instant smile in my face when the thing started talking, I feel old now :)
Seems like these guys don’t remember SAM: Software Automatic Mouth
The quality of the TI/LPC TTS is not up to current standard if you were to develop a modern product (Like some Bose BT speakers, they are just lame in 2023)
With cheap storage (SD card) and online neural TTS, any MCU can play pre-recorded sentences, indistinguishable from actual human, in any languages.
What we are missing is a quality lightweight/open TTS easy to implement on embedded system (like not Android etc..) to be able to generate any text on the fly.
Anyway at the end, if you are running on an ESP32 it would be actually better to simply stream from online TTS….
I’ll just leave this here:
https://www.youtube.com/watch?v=t8wyUsaDAyI
Is the code available? Does this use a version of Talkie? Would it work with MAX98357 I2S amplifier? Thanks
I am not sure that it is wise of me to enter into a did /didn’t debate, but I did do a lot of research on the 5100 back in the day. In some senses one group is right, the 5100 used LPC 10 to generate speech. And a generalised LPC can be used as a way of reproducing recorded speech (it is what mobile phones do). However back in the day when 64k ROM were state of the art, LPC alone was not compression enough. The LPC input parameters were generated through a LUT, where the input side of the LUT was only a very small subset of all possible input values to the LPC filter. This gave significant compression advantages, but the LUT values were tuned by TI to give optimum speech performance and hence we’re defacto related to phoneme generation. I still have the tables, I think! And BTW the BBC Micro used the 5200 and a British BBC announcer as the speech source!