 Before a chip design is turned from a hardware design language (HDL) like VHDL or Verilog into physical hardware, testing and validating the design is an essential step. Yet simulating a HDL design is rather slow due to the simulator using either only a single CPU thread, or limited multi-threading due to the requirements of fine-grained concurrency. This is due to the strict timing requirements of simulating hardware and the various clock domains that ultimately determine whether a design passes or fails. In a recent attempt to speed up RTL (transistor) level simulations like these, Mahyar Emami and colleagues propose a custom processor architecture – called Manticore – that can be used to run a HDL design after nothing more than compiling the HDL source and some processing.
Before a chip design is turned from a hardware design language (HDL) like VHDL or Verilog into physical hardware, testing and validating the design is an essential step. Yet simulating a HDL design is rather slow due to the simulator using either only a single CPU thread, or limited multi-threading due to the requirements of fine-grained concurrency. This is due to the strict timing requirements of simulating hardware and the various clock domains that ultimately determine whether a design passes or fails. In a recent attempt to speed up RTL (transistor) level simulations like these, Mahyar Emami and colleagues propose a custom processor architecture – called Manticore – that can be used to run a HDL design after nothing more than compiling the HDL source and some processing.
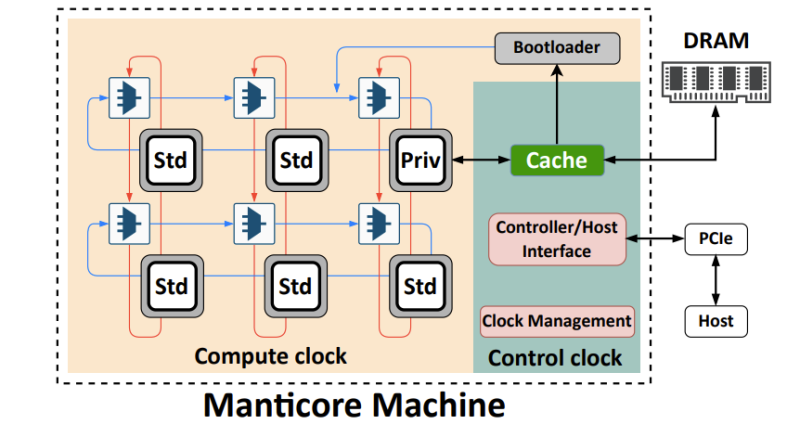
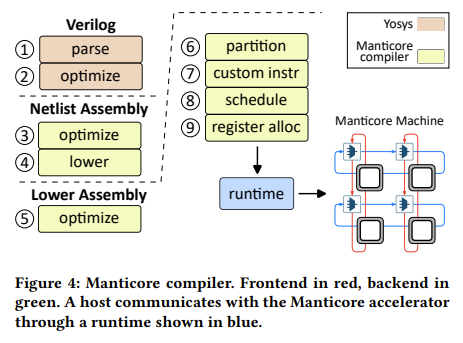
 In the preprint paper they detail their implementation, covering the static bulk-synchronous parallel (BSP) execution model that underlies the architecture and associated tooling. Rather than having the simulator (hardware or software) determine the synchronization and communication needs of different elements of the design-under-test, the compiler instead seeks to determine these moments ahead of time. This simplifies the requirements of the Manticore execution units, which are optimized to execute just this simulation task.
In the preprint paper they detail their implementation, covering the static bulk-synchronous parallel (BSP) execution model that underlies the architecture and associated tooling. Rather than having the simulator (hardware or software) determine the synchronization and communication needs of different elements of the design-under-test, the compiler instead seeks to determine these moments ahead of time. This simplifies the requirements of the Manticore execution units, which are optimized to execute just this simulation task.
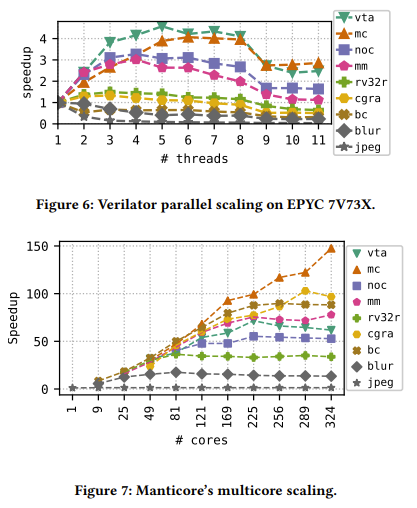
Although an ASIC version of Manticore would obviously be significantly faster than the FPGA version the researchers used in this implementation, the 475 MHz, 225-core implementation on a Xilinx UltraScale+ FPGA (Alveo U200 card) compared favorably against the Verilator simulator which was run on three x86 systems ranging from an Intel Core i7-9700K to an AMD EPYC 7V73X. Best of all was the highly impressive scaling the Manticore FPGA implementation demonstrated.
At this point Manticore is primarily a proof-of-concept, which like every PoC comes with a number of trade-offs. The primary limitation being that only a single clock domain is supported, HDL support for SystemVerilog is limited, the Scala-based tooling is very unoptimized, and waveform debugging is a TODO item. What it does demonstrate, however, is that RTL-level simulators can be made to be significantly faster, assuming BSP lives up to its purported benefits when faced with more complicated designs.














RTL = Register Transfer Level (not “transistor”)
RTL = Resistor–Transistor Logic (RTL) (sometimes also transistor–resistor logic (TRL)) is a class of digital circuits built using resistors as the input network and bipolar junction transistors (BJTs) as switching devices. RTL is the earliest class of transistorized digital logic circuit; it was succeeded by diode–transistor logic (DTL) and transistor–transistor logic (TTL)…[1]
1. RTL – Resistor–Transistor Logic
https://en.wikipedia.org/wiki/Resistor%E2%80%93transistor_logic
2. RTL NAND gate live simulation.
https://www.falstad.com/circuit/e-rtlnand.html
This is not the RTL discussed here (see comment above about Register Transfer Level).
In this context RTL = Register Tranafer Level, a way to represent both sync and async circuits with DFFs being the main elements in between comb paths, triggered by either clocks or logic signals from comb paths.
A fully sync circuit with all DFFs triggered by a single clock are the easiest to simulate, and Verilator is mostly useful for this kind.
It is impressive that anyone can get so many threads going, working on the same test. Given that speed up may not be near the number of threads used (depends highly on what is being simulated), you may still think it is best to start many simulations in parallel instead of large one using many CPU threads. This way, there are fewer threads to synchronize.
Verilog simulation is inherently parallel, it is very easy to run it on many threads, the main problem being communication between threads.
I can imagine many of these threads would have to synchronize every single clock cycle. That would have too much overhead on a CPU and would require dedicated hardware.
If you’ve got enough cores, you could calculate the outcome if certain future scenarios happen and then drop them if they don’t. Perhaps leveraging GPU processing for flow control, with groups of numbers for each state. The simulation could be very fast. A bit like trying to play a game of chess and thinking several moves ahead, instead of just calculating the game at each stage.
Hardware emulators that essentially do this exist, but they cost many thousands (or millions) of dollars.
What is the difference from FGPA machine like synopsys ZeBu?
Yes they are faster that simulation, but practically they also have their limits: requires custom models, do not handle at all low power cases (although most RTL simulator don’t also).