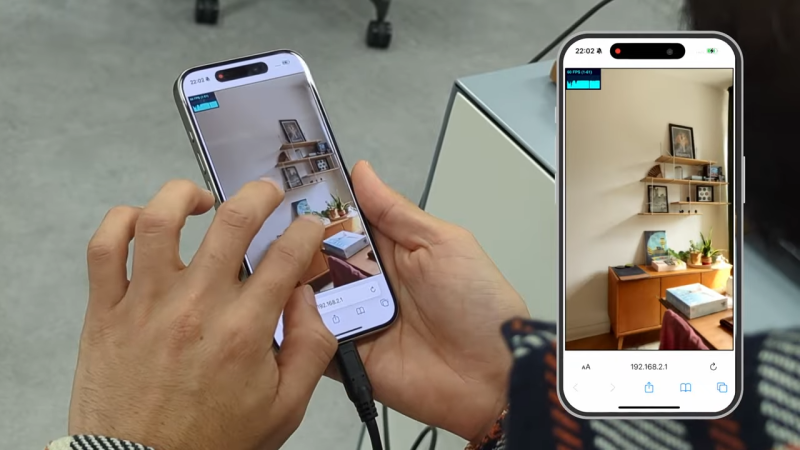
Neural Radiance Fields (NeRF) is a method of reconstructing complex 3D scenes from sparse 2D inputs, and the field has been growing by leaps and bounds. Viewing a reconstructed scene is still nontrivial, but there’s a new innovation on the block: SMERF is a browser-based method of enabling full 3D navigation of even large scenes, efficient enough to render in real time on phones and laptops.
Don’t miss the gallery of demos which will run on anything from powerful desktops to smartphones. Notable is the distinct lack of blurry, cloudy, or distorted areas which tend to appear in under-observed areas of a NeRF scene (such as indoor corners and ceilings). The technical paper explains SMERF’s approach in more detail.
NeRFs as a concept first hit the scene in 2020 and the rate of advancement has been simply astounding, especially compared to demos from just last year. Watch the short video summarizing SMERF below, and marvel at how it compares to other methods, some of which are themselves only months old.














“Neural Radiance Fields (NeRF) is a method of reconstructing complex 3D scenes from sparse 2D inputs…”
New and improved compression.
Holy crap this is impressive. AND it works natively with fisheye lenses.
I snickered when the Eames lounge chair made an appearance. Real estate staging companies never change.
I feel like there’s some cool shit you could do with this tech, from bringing back that goofy FMV era of adventure game, to something like NTSB scene investigator training sims. Not to mention the obvious stuff like virtual tours of ancient ruins and famous buildings.
* Eames Lounge Chair – Wipedia
https://en.wikipedia.org/wiki/Eames_Lounge_Chair
Okay, you can’t just toss out a term like “neural radiance field” and a 10-word explanation and expect folks to know what’s going on.
After doing some digging, I can try to explain a bit more. The idea is to train a neural network to generate a volumetric representation of a scene based on a set of input images along with information about the position and camera pose for each. Aside from learning the geometry in the scene’s volume, the model also learns about the color, reflectivity, and other surface characteristics that are shown in the images. After the network has been trained, you can then use traditional volume rendering techniques to generate new images for any given camera placement. You can store the network parameters as a representation for the scene. This is the “neural radiance field”.
While this sounds pretty interesting, I’d like to see some numbers about how large such representations are and how they compare with alternate representations. I’m too lazy at the moment though to keep looking myself.
No doubt it’ll end up in phone camera apps to fake reality even more.
‘Reality is sooo yesterday.’
This is one of the most amazing things I’ve seen in a while. Can’t wait to see it in VR / WebXR / whatever.
I’m a little more impressed with gaussian splatting, which relies on similar fundamentals but is done algorithmically, without neural networks/deep learning. Here is a demo: https://gsplat.tech/ – and the hugging face blog post on the subject is worth a read.