For the last hundred or so years, collectively as humanity, we’ve been dreaming, thinking, writing, singing, and producing movies about a machine that could think, reason, and be intelligent in a similar way to us. The stories beginning with “Erewhon” published in 1872 by Sam Butler, Edgar Allan Poe’s “Maelzel’s Chess Player,” and the 1927 film “Metropolis” showed the idea that a machine could think and reason like a person. Not in magic or fantastical way. They drew from the automata of ancient Greece and Egypt and combined notions of philosophers such as Aristotle, Ramon Llull, Hobbes, and thousands of others.
Their notions of the human mind led them to believe that all rational thought could be expressed as algebra or logic. Later the arrival of circuits, computers, and Moore’s law led to continual speculation that human-level intelligence was just around the corner. Some have heralded it as the savior of humanity, where others portray a calamity as a second intelligent entity rises to crush the first (humans).
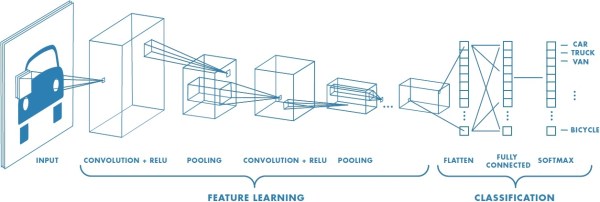
The flame of computerized artificial intelligence has brightly burned a few times before, such as in the 1950s, 1980s, and 2010s. Unfortunately, both prior AI booms have been followed by an “AI winter” that falls out of fashion for failing to deliver on expectations. This winter is often blamed on a lack of computer power, inadequate understanding of the brain, or hype and over-speculation. In the midst of our current AI summer, most AI researchers focus on using the steadily increasing computer power available to increase the depth of their neural nets. Despite their name, neural nets are inspired by the neurons in the brain and share only surface-level similarities.
Some researchers believe that human-level general intelligence can be achieved by simply adding more and more layers to these simplified convolutional systems fed by an ever-increasing trove of data. This point is backed up by the incredible things these networks can produce, and it gets a little better every year. However, despite what wonders deep neural nets produce, they still specialize and excel at just one thing. A superhuman Atari playing AI cannot make music or think about weather patterns without a human adding those capabilities. Furthermore, the quality of the input data dramatically impacts the quality of the net, and the ability to make an inference is limited, producing disappointing results in some domains. Some think that recurrent neural nets will never gain the sort of general intelligence and flexibility that our brains offer.
However, some researchers are trying to creating something more brainlike by, you guessed it, more closely emulates a brain. Given that we are in a golden age of computer architecture, now seems the time to create new hardware. This type of hardware is known as Neuromorphic hardware.
Continue reading “Neuromorphic Computing: What Is It And Where Are We At?” →