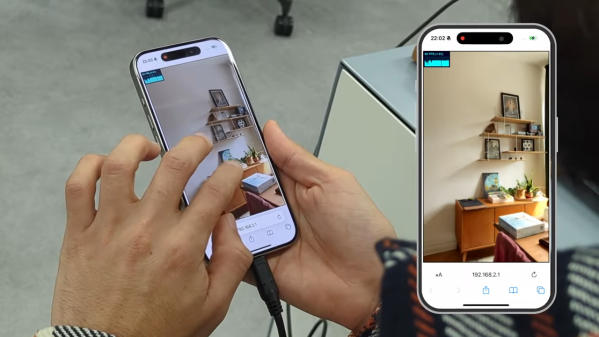
Neural Radiance Fields (NeRF) is a method of reconstructing complex 3D scenes from sparse 2D inputs, and the field has been growing by leaps and bounds. Viewing a reconstructed scene is still nontrivial, but there’s a new innovation on the block: SMERF is a browser-based method of enabling full 3D navigation of even large scenes, efficient enough to render in real time on phones and laptops.
Don’t miss the gallery of demos which will run on anything from powerful desktops to smartphones. Notable is the distinct lack of blurry, cloudy, or distorted areas which tend to appear in under-observed areas of a NeRF scene (such as indoor corners and ceilings). The technical paper explains SMERF’s approach in more detail.
NeRFs as a concept first hit the scene in 2020 and the rate of advancement has been simply astounding, especially compared to demos from just last year. Watch the short video summarizing SMERF below, and marvel at how it compares to other methods, some of which are themselves only months old.
Continue reading “Explore Neural Radiance Fields In Real-time, Even On A Phone”













