
As I’m sure many of you know, x86 architecture has been around for quite some time. It has its roots in Intel’s early 8086 processor, the first in the family. Indeed, even the original 8086 inherits a small amount of architectural structure from Intel’s 8-bit predecessors, dating all the way back to the 8008. But the 8086 evolved into the 186, 286, 386, 486, and then they got names: Pentium would have been the 586.
Along the way, new instructions were added, but the core of the x86 instruction set was retained. And a lot of effort was spent making the same instructions faster and faster. This has become so extreme that, even though the 8086 and modern Xeon processors can both run a common subset of code, the two CPUs architecturally look about as far apart as they possibly could.
So here we are today, with even the highest-end x86 CPUs still supporting the archaic 8086 real mode, where the CPU can address memory directly, without any redirection. Having this level of backwards compatibility can cause problems, especially with respect to multitasking and memory protection, but it was a feature of previous chips, so it’s a feature of current x86 designs. And there’s more!
I think it’s time to put a lot of the legacy of the 8086 to rest, and let the modern processors run free.
Some Key Terms
To understand my next arguments, you need to understand the very basics of a few concepts. Modern x86 is, to use the proper terminology, a CISC, superscalar, out-of-order Von Neumann architecture with speculative execution. What does that all mean?
Von Neumann architectures are CPUs where both program and data exist in the same address space. This is the basic ability to run programs from the same memory in which regular data is stored; there is no logical distinction between program and data memory.
Superscalar CPU cores are capable of running more than one instruction per clock cycle. This means that an x86 CPU running at 3 GHz is actually running more than 3 billion instructions per second on average. This goes hand-in-hand with the out-of-order nature of modern x86; the CPU can simply run instructions in a different order than they are presented if doing so would be faster.
Finally, there’s the speculative keyword causing all this trouble. Speculative execution is to run instructions in a branching path, despite it not being clear whether said instructions should be run in the first place. Think of it as running the code in an if statement before knowing whether the condition for said if statement is true and reverting the state of the world if the condition turns out to be false. This is inherently risky territory because of side-channel attacks.
But What is x86 Really?
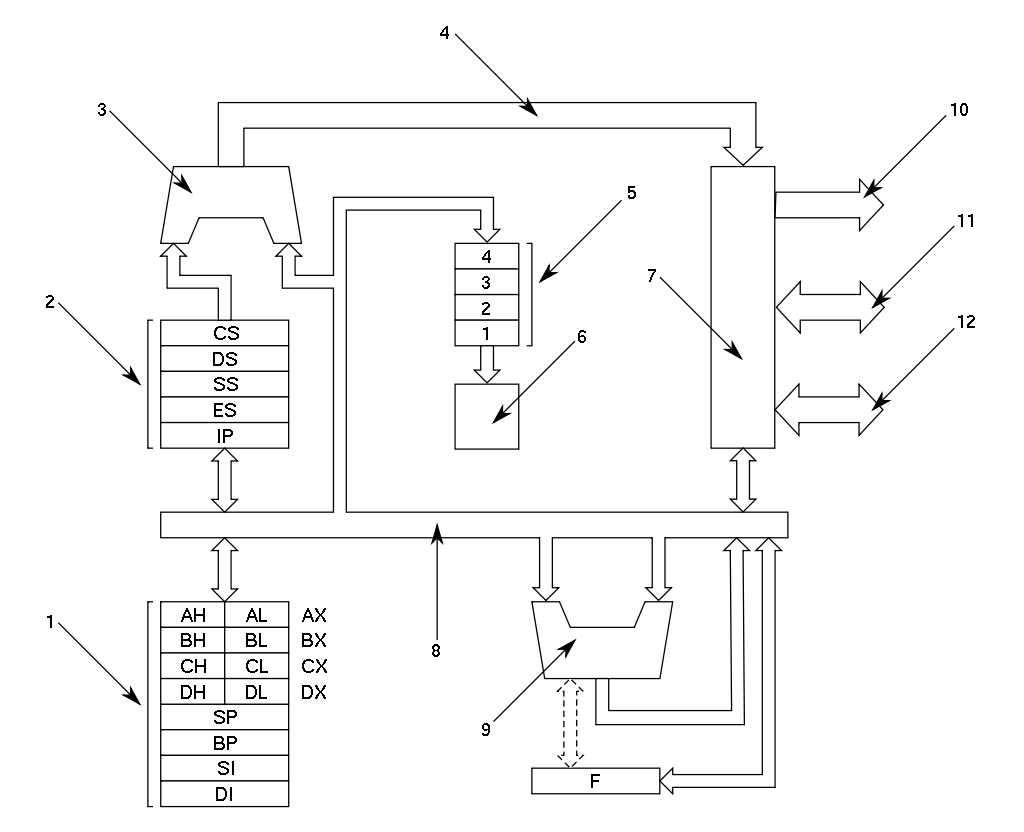
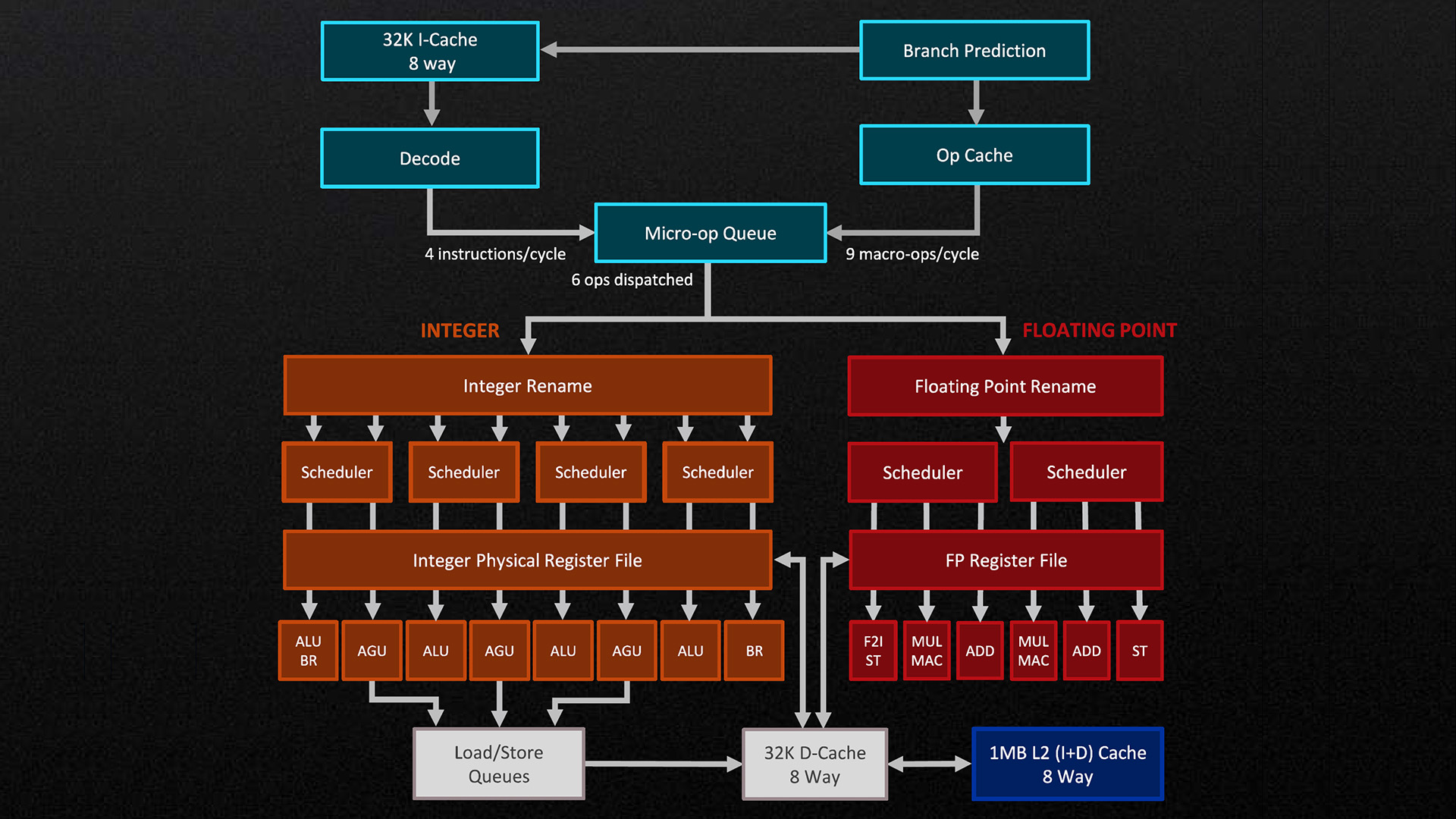
Here, you can see block diagrams of the microarchitectures of two seemingly completely unrelated CPUs. Don’t let the looks deceive you; the Zen 4 CPU still supports “real mode”; it can still run 8086 programs.
The 8086 is a much simpler CPU. It takes multiple clock cycles to run instructionsa: anywhere from 2 to over 80. One cycle is required per byte of instruction and one or more cycles for the calculations. There is also no concept of superscalar or out-of-order here; everything takes a predertermined amount of time and happens strictly in-order.
By contrast, Zen 4 is a monster: Not only does it have four ALUs, it has three AGUs as well. Some of you may have heard of the Arithmetic and Logic Unit before, but Address Generation Unit is less well known. All of this means that Zen 4 can, under perfect conditions, perform four ALU operations and three load/store operations per clock cycle. This makes Zen 4 a factor of two to ten faster than the 8086 at the same clock speed. If you factor in clock speed too, it becomes closer to roughly five to seven orders of magnitude. Despite that, the Zen 4 CPUs still supports the original 8086 instructions.
Where the Problem Lies
The 8086 instruction set is not the only instruction set that modern x86 supports. There are dozens of instruction sets from the well-known floating-point, SSE, AVX and other vector extensions to the obscure PAE (for 32-bit x86 to have wider addresses) and vGIF (for interrupts in virtualization). According to [Stefan Heule], there may be as many as 3600 instructions. That’s more than twenty times as many instructions as RISC-V has, even if you count all of the most common RISC-V extensions.
These instructions come at a cost. Take, for example one of x86’s oddball instructions: mpsadbw. This instruction is six to seven bytes long and compares how different a four-byte sequence is in multiple positions of an eleven-byte sequence. Doing so takes at least 19 additions but the CPU runs it in just two clock cycles. The first problem is the length. The combination of the six-to-seven byte instruction length and no alignment requirements makes fetching the instructions a lot more expensive to do. This instruction also comes in a variant that accesses memory, which complicates decoding of the instruction. Finally, this instruction is still supported by modern CPUs, despite how rare it is to see it being used. All that uses up valuable space in cutting-edge x86 CPUs.
In RISC architectures like MIPS, ARM, or RISC-V, the implementation of instructions is all hardware; there are dedicated logic gates for running certain instructions. The 8086 also started this way, which would be an expensive joke if that was still the case. That’s where microcode comes in. You see, modern x86 CPUs aren’t what they seem; they’re actually RISC CPUs posing as CISC CPUs, implementing the x86 instructions by translating them using a mix of hardware and microcode. This does give x86 the ability to update its microcode, but only to change the way existing instructions work, which has mitigated things like Spectre and Meltdown.
Fortunately, It Can Get Worse
Let’s get back to those pesky keywords: speculative and out-of-order. Modern x86 runs instructions out-of-order to, for example, do some math while waiting for a memory access. Let’s assume for a moment that’s all there is to it. When faced with a divide that uses the value of rax followed by a multiply that overwrites rax, the multiply must logically be run after the divide, even though the result of the multiply does not depend on that of the divide. That’s where register renaming comes in. With register renaming, both can run simultaneously because the rax that the divide sees is a different physical register than the rax that the multiply writes to.
This acceleration leaves us with two problems: determining which instructions depend on which others, and scheduling them optimally to run the code as fast as possible. These problems depend on the particular instructions being run and their solution logic gets more complicated the more instructions exist. The x86 instruction encoding format is so complex an entire wiki page is needed to serve as a TL;DR. Meanwhile, RISC-V needs only two tables (1) (2) to describe the encoding of all standard instructions. Needless to say, this puts x86 at a disadvantage in terms of decoding logic complexity.
Change is Coming
Over time, other instruction sets like ARM have been eating at x86’s market share. ARM is completely dominant in smartphones and single-board computers, it is growing in the server market, and it has even become the primary CPU architecture in Apple’s devices since 2020. RISC-V is also progressively getting more popular, becoming the most widely adopted royalty-free instruction set to date. RISC-V is currently mostly used in microcontrollers but is slowly growing towards higher-power platforms like single-board computers and even desktop computers. RISC-V, being as free as it is, is also becoming the architecture of choice for today’s computer science classes, and this will only make it more popular over time. Why? Because of its simplicity.
Conclusion
The x86 architecture has been around for a long time: a 46-year long time. In this time, it’s grown from the simple days of early microprocessors to the incredibly complex monolith of computing we have today.
This evolution has taken it’s toll, though, by restricting one of the biggest CPU platforms to the roots of a relatively ancient instruction set, which doesn’t even benefit from small code size like it did 46 years ago. The complexities of superscalar, speculative, and out-of-order execution are heavy burdens on an instruction set that is already very complex by definition and the RISC-shaped grim reapers named ARM and RISC-V are slowly catching up.
Don’t get me wrong: I don’t hate x86 and I’m not saying it has to die today. But one thing is clear: The days of x86 are numbered.














I wonder how GST467 or a similar upcoming memory might change things.
https://www.livescience.com/technology/electronics/universal-memory-breakthrough-replaces-ram-flash-next-generation-of-computers-major-speed-boost
Why not a RISC core with ability to handle lots of microcode — partitioned to switch between different ISAs. X86 microcode here, Arm there.
By the time any other arch (i.e. aarch64 or whatever risc-v configuration becomes the defacto standard) is posed to replace x86_64 across the board that arch will look just as messy and crazy as x86_64 does right now and someone that can barely code in a ISA agnostic language like python will be writing an article on the internet about how it has to die and how some wasted transistors are directly causing kitten death.
Meanwhile everyone that isn’t a CPU vendor, compiler backend author or enjoyer of ranting into the void still won’t care.
Nicely written but mixing ISA with microarchitecture shows lack of understanding. Sorry.
Only way to achieve today’s performance is superscalar architecture and it is also used by ARM and RISC-V cores.
Also, only way forward are tricks to improve performance, like speculative execution. Everyone does that.
And cause of bugs and oversights in design we have vulnerabilities. Some found in Intel are also in AMD, ARM.
Latest Apple M series – GoFatch.
Comparing vulnerabilities we see how most of them are patchable in x86 but not in Apple ARM. Does it mean Apple M must die?
Yes, x86 has ridiculous instructions, but for a reason – someone uses them. In ARM, RISC-V it will take a lot of instructions to emulate them.
Anyway, x86 code is some 20% smaller than RISC.
Apple also has lots of instructions cause they are needed by various coprocessors, SIMD, NPU, etc
Show me what could replace x86?
Only performance comparable is Apple M.
Until it was abandoned by Apple and real work on improving the microarchitecture was halted, Power PC was more efficient, cycle for cycle. Also, because the MMU had always been part of the architecture, the difference between access violations (attempting to write to memory you don’t have write permission to) and illegal addresses (addresses that are not mapped to physical addresses in your page table) are different so speculative execution side channel attacks don’t have the same results. Overall a cleaner memory model.
Why did Apple switch to Intel?
Because like it or not, the combination of price and performance was better than PowerPC even though Big Blue and Apple were behind it
There is no conspiracy to keep “better” architectures down. The only conspiracy is that a consumer will choose the cheapest thing that does the job even if there are some inconveniences, and the kind of people who think they need better are outliers and have little or no say in the market
Also to point out, those “extra” features, are just uOPS, and not specialized die as the author made it out to be. Very, very little is lost or taken up on the die, but a lot of backwards compatibility is added, ie value. The author just has no clue what a modern CPU die is or how the internal structure actually works.
There are many alternative to x86 existing so the only reason “x86 needs to die” is to force another architecture to win. In a level playing field, go ahead and make an OS and set of applications that works better. That is how you win although my point is why do you have to “win”. Why not coexist? There can be all kind of architectures and software and no one cares what architecture and software you use as long as it does the work at hand well.
It’s kinda funny you picked the Zen 4 to compare it with, since AMD optimized the hell out of some original x86 instructions in Zen 3. “8/16/32/64 bit signed integer division/modulo latency improved from 17/22/30/46 cycles to 10/12/14/20.”… doubled the performance, actually, and they’ve probably been improving them for a while since the broadwell-e was something like 90+ cycles for an SDIV.
It’s also kinda funny that you think something called an address *generation* unit stores things. Amazingly, it doesn’t; it generates addresses. It isn’t as important for the purpose of math anymore but a long time ago it was also used to reduce what would have been an add of two registers and a left shift instruction (and possibly another add of an immediate) to a single instruction that executes faster.
MPSADBW… I need Anton Chigur for a “You don’t know what you’re talking about, do you?”
MPSADBW — Compute Multiple Packed Sums of Absolute Difference
VEX.256.66.0F3A.WIG 42 /r ib VMPSADBW ymm1, ymm2, ymm3/m256, imm8
(Yes, there’s an AVX2 version of the instruction you’ve deemed useless because of your insane interpretation of it)
Sums absolute 8-bit integer difference of adjacent groups of 4 byte integers in xmm2 and ymm3/m128 and writes the results in ymm1. Starting offsets within ymm2 and xmm3/m128 are determined by imm8.
Why would anyone want to add a bunch of absolute differences together really fast, it’s almost like there must be some purpose for it, but I guess I’ll never know so it must just be garb… oh wait I can type things into google if I’m not immediately sure of what they’d be useful for instead of dismissing them, here’s the first paragraph of the wikipedia page:
“In digital image processing, the sum of absolute differences (SAD) is a measure of the similarity between image blocks. It is calculated by taking the absolute difference between each pixel in the original block and the corresponding pixel in the block being used for comparison. These differences are summed to create a simple metric of block similarity, the L1 norm of the difference image or Manhattan distance between two image blocks. ”
“Yeah but surely nobody is usi…”
E:\code\x265>findstr /s mpsadbw *.asm
source\common\x86\mc-a2.asm: mpsadbw m0, m4, 0
…
The functions in this file are used for part of the calculation of motion compensation data for HEVC; of course, motion compensation has been part of video compression since they started considering more than one frame at a time. I only searched the x265 codebase because I had it on disk and it’s something like 70% assembly language so I didn’t have to try to find an intrinsic call.
And I’ll just quit reading your article at that point. I’ve been an assembly language programmer for over 30 years. The original pentium had the U and V pipelines that could each execute different instructions and most machines with those were still running Windows 95 which was a glorified DOS GUI. I proceeded on to learn Fujitsu FR, both instruction sets for ARMv5te, then Thumb-2, then PowerPC’s Cell variant. I worked on LLVM compiler backends for years. Every processor has its own little idiotic lapses from sensibility, x86 possibly more than most because of how long it’s been around and how constrained the registers were on the originals. ARM had the monumentally stupid bxj instruction that was designed to branch directly into Java bytecode and switch to a hardware interpreter for it, which is dumber than literally anything Intel has ever done including designing the Itanium which was proven to be an NP hard computing problem in terms of writing a compiler that could generate optimal code thanks to the manual load / store / branch hinting that required prescient knowledge of inputs among other things. Go read a damn basic book on assembly or CPU architecture design or both, then when you realize how much you don’t know, go read the entire intel architecture manual and see if you absorb anything. I sound harsh but I’m going easy on you, the first time I asked an assembly question on the newsgroups when I hadn’t learned very much I got chewed out by no less than 3 college professors, and they weren’t telling me to learn more, more like what I should shove where.
Brilliant
Not for or against either arch, I am using aarch64 linux but there have been 2 sidechannel attacks against M*, which no one here seems to recognize…
https://readwrite.com/side-channel-attack-vulnerability-found-in-apples-m1-chip/
How many top supercomputers are not x86?
Instructions don’t exist just because of frequency of use. Most compilers produce a very small subset of the instruction set. Domain specific instructions let the processor plow through massive workloads.
Comparing the 8086 to modern processors is funny. How many cores are we up to on a single socket? Pushing 5Ghz, several instructions per clock, hyper-threaded, … please – sit down.
Most modern applications are compiled to x64, and the microcode translation of x86 is tiny, on die.
I kinda feel like a better article would have been “why do journalists think that x86 is anything but a tiny bit of legacy support, when modern Intel and AMD processors have been x64 for nearly 20 years?”
The original IBM PC didn’t use an 8086, it used an 8088. The 8088 was easier to use with existing available memory and other chips at the time.
I remember these arguments when PowerPC was poised to overtake X86, on the belief that the patchwork that is the x86 instruction set encoding. Didn’t really happen 20 years ago, and itis less likely to happen now. The chip area for dealing with 16-bit real mode is miniscule compared to all the other features inthe chip. Removing it will save a lot of validation effort, and there is already work on chipa that boot in 64-bit and remove they 16 and 32 modes. Another option that would be trivial today is to only include 16-bit real mode on the first core, and remove it on the rest. DOS apps rarely support multicore, and UEFI doesn’t need it at all.
Touché.
You need to read this
https://chipsandcheese.com/2024/03/27/why-x86-doesnt-need-to-die/
As far as I know, in most of the OSes today, execution of x86 real mode code is achieved through emulation, regardless of the CPU running it
If we consider the necessity to continue to be able to run archaic real mode specific code natively, this is achievable through micro coding on top of a “random” cpu architecture and it had been since the 90’s with the AMD K5 built on top of a 29000 Risc CPU core
Most of the risc competitor got extensions similar to the X86 one (Vectorial units, FPU, etc ….)
At several points of the history three had been as much differences between x86 implementations by different manufacturer as you have between a X86 and a CPU inheriting from a Berkeley Risc design
– Pentium VS K5/K6
– In the 2000: AMD used to use a quite specialized and complex design while to achieve the same, intel relied on big area of more “generic” logic cells, easing the overclocking
– Core iX Vs ZENx architecture
Many of the comments are Right: common Risc CPU (even if very few of them are still truly what risc meant initially) are in most of the cases thought around scalability an dlow production costs, more suitable for running not so complex tasks, but in a massively parallel way, while the “common/base desktop”x86 design was thought at first to be stand alone, having to run complex calculus on a single core effciently .
But Although being x86 of their own right, many variation emerged
– Mobile CPU with some “fused” instructions designed more in a “Risc Way” to be suitable for mobile devices. Those CPU were rather good in low end desktop and multimedia tasks (with the appropriate multimedia module embedded) but rather mediocre in complex mathematics
– Classic Desktop cores, good at computation and multimedia
– Highly scalable high-end multi core processors….
– Even very low end, legacy architecture based single core aimed at embedded market (mostly failures, since there, the Risc dominates)
– Etc …
Talking about “The” X86 is to my own opinion a nonsenses today since there are many, more or less optimized way to be a X86
And the reason why it still dominate is simply a questions of their almost monopolistic importance in the installed base
– X86 software offer is literally monstrous, even if in most of the case the code could be considered portable
– X86 Specialists are legion
But Imagine at some point a major Failure in a design or an incapacity for intel and amd to adapt to emerging technology (Neuroprocessors, “IA accelerators”) and the X86 would fade within a decade, like many had before
if you dislike x86 nothing is holding you back to get an fpga and design what you want it to be.
while choice is always great, i’m impartial to risc-v. sun opensourced their sparc in 2005, but as it turns out fabbing a complex core on a current process is expensive and has poor yields at tapeout in general.
biggest drawback of i386 & amd64 are the very limited number of licensees, but this also provides a uniform platform. most of this discussion ended when java and later other interpreted languages became dominant. almost all coders i know just want to run python or nodejs, if it’s to slow just throw more hardware at it (turns out plan9 had the correct idea, if it’s slow just wait for the hardware to catch up).
hand optimizing routines directly in assembly is still worth nerdcred, but also has become mostly irrelevant.
it’s how the ebb & flow works. way back your fpu or even mmu was a seperate chip, southbridges, northbridges, memory controllers, … they’re all gone (well, integrated in the cpu). and then came general purpose gpu usage, then npu’s, and we’re decentralizing again. and changing isa’s for those things almost every generation.
perhaps we can up the ante and address a bigger issue: clockless designs are what we really need, synchronous designs are the lazy option :-D
now gonna rest my feet on this hp visualize c240 running openbsd while searching for a cpu module for my sgi octane2. gotta be ready when this risc revolution starts :)
Be careful what you wish: first laptops using Snapdragon Elite X (ARM) are coming this summer (Surface Pro 10 and Surface Laptop 6, Galaxy Book4 Edge, Lenovo 83ED) with Windows 11 on ARM. Having similar characteristics like Apple M3 (performance and battery life), translating x86/x64 to ARM9 (M3 uses ARM8), making x86/x64 a history.
“In RISC architectures (…) instructions is all hardware; (…). The 8086 also started this way, (…) That’s where microcode comes in. You see, modern x86 CPUs aren’t what they seem; they’re actually RISC CPUs posing as CISC CPUs, implementing the x86 instructions by translating them using a mix of hardware and microcode.”
Two big mistakes here. 1) The 8086, like all CPUs of the era, has a lot of microcode, and 2) x86 CPUs aren’t “RISC posing as CISC”. They’re thoroughly CISC, but decompose the CISC instructions into parts that can be handled out of order – but that’s not the same as RISC!
I think the most important issue of all that bloat hasn’t been addressed at all: power consumption. The x68 architecture, despite its added intricate power management is no match for a streamlined ARM. And that’s one if not the most important point why x86 has to die at some point.
Well “if it ain’t broken, don’t FIX it.” Also, since this article is arguing more (IMO) eventual coding/processing bottlenecks it is, “Bird in hand worth two in bush” and/or “Better the Devil you KNOW…”
I’ve wanted modular multi processing computers where a kid could start with a toy and then saving up allowance then job then salary money keep adding processors, memory, storage modules till they had a mini supercomputer. I’ve been shouted down as an idiot proposing it.
Another thing I want and IMO the “Ai Revolution” will push it at last, a scalable multi-processor systmem. Not just special tasks but you could buy or rig Ai nodes and connect them so you could get dozens or hundreds of small computers (Adafruit/raspberri pi?) and then make a real ‘Brain” for an AGI attempt or at least next level chatbot and Ai training.
Whatever comes they had better D— sure make sure it has an “Emulation” mode. So NOBODY alive when its in place has to give up even WUMPUS or ELIZA if they have it in their experience and are used to it. We aren’t going to support flushing the system and programs from dozens of choices and companies that fly by night 80s style. They had an excuse back then, not now with all the monopolies and same makers of chips and same schools for code.
I don’t understand why out-of-order and speculative execution are getting called out as negatives? I understand their potential for side-channeling but your computer would be leaps and bounds slower without them.
Additionally — an ISA does not dictate implementation details such as whether speculative execution should be used or not, these are decisions made at the march level. Many ARM and RISC-V implementations use OOO and speculative execution.
Idealizing RISC is also quite unrealistic. While leaning too much in to CISC gets messy, many instructions added to x86 were put there for good reason (usually speed). If RISC is so great, why don’t we remove all FP instructions and just let everyone write software FP implementations? After all, god forbid the ISA is complicated!
(I’d like to make it clear here that the real ‘winner’ in RISC vs CISC is the middle-ground in-between them and that they both have their tradeoffs. I’m not saying CISC is the best)
This article’s logic feels similar to arguing that linear sort is better than binary sort because it’s less complicated. Speed matters, not everything can be simple.
RISC-V is popular for SoC because it’s free, open and fairly common. There are other cores but they either require expensive licenses, heaps of die space or are custom instruction sets that require their own BIOS, OS and software.
Amazing. Every word of what you just said was wrong.
Newsflash: ALL large, fast RISC cpus – ARMs, RISC-Vs, POWER etc, are ALSO speculative out-of-order superscalar, and have been for decades now. In fact, the main argument for RISC was that it made the implementation of these monstrously complex (and fast) speculative out-of-order superscalar CPUs easier.
While x86 admittedly has a lot of vector extensions, RISC instructions also have these as they are extended to bigger, faster CPUs over time. POWER has AltiVec/VMX, VMX128, VSX, and even DFP (decimal floating point!). ARM has SIMD instructions, VFP (now mostly abandoned aside from the core floating point functionality), NEON, NEONv2.
Remember the Intel Itanium? About how it was a dog, came out late, was disappointing in performance, required exotic and complex optimizing passes, and was never even really as fast as x86? Itanium failed exactly because WASN’T a speculative out-of-order CPU, and it was designed exactly to try to circumvent this. It ended up with a lot of big sacrifices because of this, such as predication on everything, exotic memory load operation flavors (checked, advanced etc), very large code size that required enormous instruction caches etc. In the end, the Intel/HP duo ended up with a CPU just as complex as if they had done Out-Of-Order in the first place, except without the performance, and that was slower than both Intel’s Out-Of-Order x86’s and HP’s Out-Of-Order PA-RISC. If they had just done an upgrade of PA-RISC, or just did another MIPS clone, it would have come out on time, been fast, and probably replaced x86.
While the complexity of decoding x86 is legendary, the decoder is only a TINY part of modern CPUs. All the various data and instruction and L2/L3/etc… caches are way larger than the decoder, not to mention the branch predictor, memory interface units and so forth. These exist on ALL fast CPUs, including all RISCs. The fact that x86 can run real-mode opcodes matters little: these operations don’t go through the normal fast superscalar decoder and the cpu will just slowly pull them one by one from the microcode rom. The impact is very small.
This article shows a profound misunderstanding of what makes CPUs slow or fast, and while the specifics of what it says are true, its overall thesis is dead wrong.
The REAL problem with x86 is that Intel and AMD jealously guard the architecture against implementations by anybody else, using their patent pool. It’s an effective two company monopoly that’s stifling innovation, and the US administration has been completely feckless and derelict in its duty of breaking down monopolies.
risc-v has sure brought out a lot of people who don’t know anything about computer architecture.
lmao. More like people read buzzfeed news, Wikipedia, and other social media and immediately assume they’re God tier hardware engineers. Sadly, it’s probably 99.99% of people these days.
“Finally, there’s the speculative keyword causing all this trouble.”
Speculative execution exists on all modern processors since a more than a decade – nothing specific to x86/x64
The Zen 4 CPU still supports “real mode”
All PCs boot up and run BIOS code in old 8086 style real mode – but UEFI switches to protected mode within a few 1000 instructions, it is never used again
16 bit protected mode (a la Windows 3.1) and 8086/VM mode (as in NTVDM) have been removed almost a decade ago
All the other crud will be soon gone with the new x86-S
“There may be as many as 3600 instructions”
Of course if you count modifier bits rather than opcodes, you will end up with a large number
Example – you have an ADD instruction, with variants for reg to reg, reg to mem and mem to reg, with and without indirection – you end up with many “instructions” in terms of raw distinct bit patterns.
Does that mean that the processor does more work to decode them?
Definitely not – that information is essential and even if you had a load/store architecture, you would have to have some N different permutations of bytes to express all the same semantics – no bits are really wasted intentionally
Sure you could argue that the various prefix bytes that are used to indicate that the next instruction is of a different extension (for example 0x66 to indicate 64/32 or 32/16 bit instructions), but thats the price of legacy.
The true instruction count of the core x86 ISA is actually smaller than some RISC
The term RISC is superfluous and meaningless, and has been since the Pentium Pro era when the real “instruction set” of the processor is in micro-ops, not individual x86 instructions
MMX, SSE 1/2/3/4, AVX and all the rest are separate execution units, more like co-processors – there is nothing to suggest that instruction decoding is really eating transistor budget or performance.
The reason ARMs work well is because Apple and Qualcomm are good engineers – nothing inherently superior about the ARM ISA that lets it have higher IPC or lower transistor count.
If ARM were really so great we should see them take over the server space soon – it may happen, but not because X86 is crippled, but rather because you will have more people working on CPUs on large scales, rather than just Intel and AMD
This whole thing is just blown out of proportion and misleading
Comparing the author of this article to AMD/Intel:
– AMD and Intel: Over the years we have developed tools (design, verification, …) that enable us to maintain compatibility constraints across successive x86 CPU generations with a reasonable amount of effort and with very high confidence
– Author of this article: I don’t have such tools, I don’t care if such tools exist, and even if they existed x86 CPUs must be a nightmare to maintain
I don’t see this a large problem. Simply emulate x86 real mode and instructions from microcode (think it’s happening nowadays so) and voilá.
And yes, CISC CPU is more complex than a RISC. What a surprise ;)
There are significant problems with this writeup:
– The author does not appear to understand what an 80186 is.
– What is the problem with real mode precisely? Does the author have any understanding how to enable 5 level paging?
– Von Neumann might have been surprised by hearing such a claim. It is evident that the author does not understand the overall memory system design and operation.
– Speculative execution and side channel attacks are purely an implementation aspect. If you implement your execution environment in such a way that allows for state leakage then it is your fault. The reasons for selecting a particular way of implementation are influenced by weighting of performance gains vs runtime risks.
– 8086 and a predetermined amount of time for execution. The author should look up instruction timings for 8086. That may reveal some surprises.
– PAE, vGIF – when there is a lack of arguments, let’s drop in some abbreviations, just for the sake of looking cool. It is not evident that the author understands the difference between the programmable execution component and the environment of where that execution component resides, or the “core” and “uncore” parlance used by some vendors. Interrupt delivery is important in the real world, but that is neither complex nor a deciding factor for performance.
– 3600 instructions. There is an extra “0” here. The author does not appear to understand the difference between instructions and operand encodings. x86 is a R/M machine, and absolutely naturally it has to cover the encoding of possible permutations of operands that include both registers and memory.
– Instruction length and fetching and decoding appears to be a central overhype, yet it could not be further away from the reality. x86 instruction decoding is simple as there is regularity there that just requires pattern patching, it is easily done in parallel, and that part of the overall pipeline is not a performance blocker at all. For a software oriented mind that may look as being complex, but in hardware that parallelizes just trivially. Although I have an uneasy feeling that the author still thinks that it is not possible to parse a fetch block at once and it has to be done sequentially.
– “Microcode” and what it could and could not change is another overhype here. The state required to control various execution units is all “microcode”, regardless of the originating source – whether that is a result of instruction translation, or a direct feed from storage, and that is the absolute fundamental concept of how programmable systems have been operating for last 60+ years.
– x86 instruction encoding “complexity” appears to be present only in the mind of the author. Decoding is not complex; once again, that is a trivial task in the hardware domain.
– ARM dominance, differences between ISA and implementation appear to be an imaginary world of the author’s. ARM as a family of implementations dominates for purely economic reasons of a set of manufacturers producing components that happen to have ARM ISA (not important) and providing a price/performance ratio that is relevant to the real world (important).
– Immediates in instructions are good for the real world. Academic purists may argue for sure, but they do not build practical software systems anyway.
– The freeness of RISC-V is an imaginary one. If you want to build a fast programmable processing system, ISA and encoding details are not relevant in the context of actual implementation decisions of specific processing units. Shuffling a few bits here and there is not a deciding factor, that is trivial to do and does not have a visible impact on performance. ISAs have a more far-reaching impact into the software domain though, and software is what eventually decides on the practical applicability of the hardware.
Why x86 Doesn’t Need to Die: https://chipsandcheese.com/2024/03/27/why-x86-doesnt-need-to-die/
Worth reading the entire article, but:
“About a decade ago, a college professor asked if I knew about the RISC vs CISC debate. I did not. When I asked further, he said RISC aimed for simpler instructions in the hope that simpler hardware implementations would run faster. While my memory of this short, ancient conversation is not perfect, I do recall that he also mentioned the whole debate had already become irrelevant by then: ISA differences were swept aside by the resources a company could put behind designing a chip. This is the fundamental reason why the RISC vs CISC debate remains irrelevant today. Architecture design and implementation matter so much more than the instruction set in play.”
A lot of what has been written is misleading or wrong.
Z80 should have live for the opposite reasons
What actually needs to die are builtin instructions, security extensions, and other security “features” that are used almost exclusively for vendor lock-in and other uscruplous fascistic and capitalistic bs like we’ve seen out of Google, smartphone makers, and other OEMs over recent years.
If you don’t have the keys to the house, it’s not yours.
Likewise, if you don’t have root or baremetal access to the hardware, it’s not yours either.
X86 spent a lot of its years in desktop PC’s which could care less about efficiency. ARM on the other hand was specifically focused on mobile devices with a need for efficiency and low power vs performance balance.
I think both Intel and AMD focused way too much on performance and desktop PC market before ever considering the rapidly increasing laptop and more importantly thin and light laptop markets. Sure, they managed to lower the power draws but nothing like the ARM processors. It’s why Apple finally ditched Intel in their Mac’s. That sort of sealed the fate of the X86 as not being efficient enough vs the ARM designs.