That students these days love to use ChatGPT for assistance with reports and other writing tasks is hardly a secret, but in academics it’s becoming ever more prevalent as well. This raises the question of whether ChatGPT-assisted academic writings can be distinguished somehow. According to [Dmitry Kobak] and colleagues this is the case, with a strong sign of ChatGPT use being the presence of a lot of flowery excess vocabulary in the text. As detailed in their prepublication paper, the frequency of certain style words is a remarkable change in the used vocabulary of the published works examined.
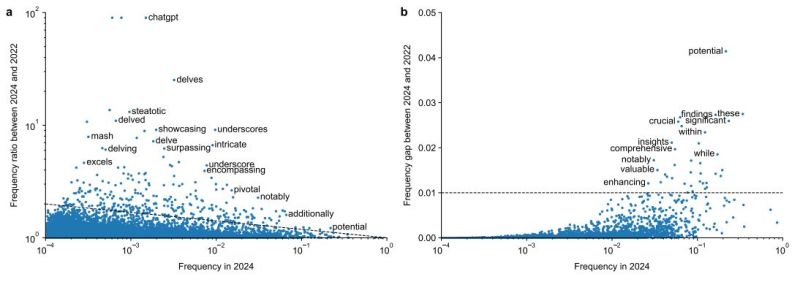
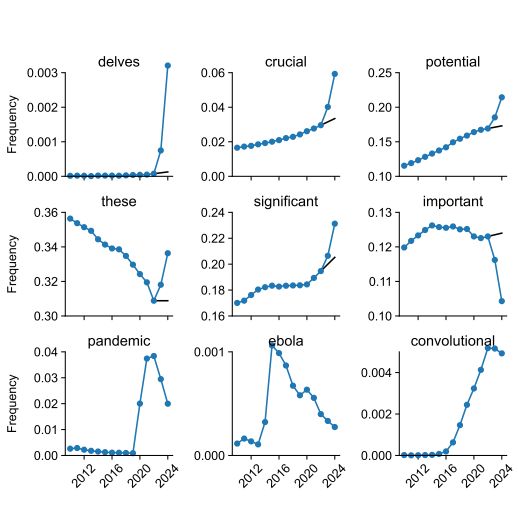
For their study they looked at over 14 million biomedical abstracts from 2010 to 2024 obtained via PubMed. These abstracts were then analyzed for word usage and frequency, which shows both natural increases in word frequency (e.g. from the SARS-CoV-2 pandemic and Ebola outbreak), as well as massive spikes in excess vocabulary that coincide with the public availability of ChatGPT and similar LLM-based tools.
In total 774 unique excess words were annotated. Here ‘excess’ means ‘outside of the norm’, following the pattern of ‘excess mortality’ where mortality during one period noticeably deviates from patterns established during previous periods. In this regard the bump in words like respiratory are logical, but the surge in style words like intricate and notably would seem to be due to LLMs having a penchant for such flowery, overly dramatized language.
The researchers have made the analysis code available for those interested in giving it a try on another corpus. The main author also addressed the question of whether ChatGPT might be influencing people to write more like an LLM. At this point it’s still an open question of whether people would be more inclined to use ChatGPT-like vocabulary or actively seek to avoid sounding like an LLM.













Interesting! I wonder if this can even distinguish different LLMs?
So far I’ve seen using Chat GPT to obtain “outlines” to ensure I dont miss anything.
Yeah, it’s pretty good for reading mountains of text very fast and giving you cliff notes. Not so great for writing things
I find it often misinterprets or makes up stuff that wasn’t in the text, or leaves important parts out, and the summaries are sometimes vague to the point of uselessness.
Sounds a lot like the majority of the news readers on any network these days.
I’ve watched one local channels staffers stumble over the same script error for two days.
A great deal of news articles around the web were already written by AI scripts prior to Chat-GPT becoming a thing.
It’s mostly about swiping articles form reputable news sites and then re-arranging them to appear like original text.
Word tells aren’t new.
Anybody who uses ‘hullabaloo’ regularly learned English by listening to Pravda’s English language propaganda.
Also anybody who types or says ‘late stage capitalism’ is an indoctrinated credulous moron repeating derp!
Late stage capitalism
Nyet
Or they went to Texas A&M University where hullabaloo is literally the start of their war hymn:
Hullabaloo, Caneck! Caneck!
Hullabaloo, Caneck! Caneck!
In these final, frenzied days of late stage capitalism, I’m happy to be reminded of the useful word “hullabaloo”, which I shall try to remember to use use to characterize the derp I hear so very often.
Well with the analysis code available people will just know how to cheat better, but consider they’re using ChatGPT to cheat in the first case, most are probably to lazy to go to tall that work.
“According to [Dmitry Kobak] and colleagues this is the case, with a strong sign of ChatGPT use being the presence of a lot of flowery excess vocabulary in the text.”
Like a love letter to the grant giver.
The real paperclip maximizer was in academia the whole time!
Im curious why you’d associate existential risk to a glorified Redditor. Of course excessive flowery language is present. Look at the foundation
Their research results show a lot of potential but it’s crucial that they delve into less technical areas of academia, e.g. fine and literary arts, before we accept their methodology. Seeing similar patterns in these, or any area which encourages the use of flowery language, will be crucial to proving whether their method is universally applicable or must be tuned to each one. Given word usage changes over time and the outsized influence of the culture, school curriculum and like the persons under which one studies, shadows or is trained has on one’s own language, I think they have a significant challenge to overcome with a broader dataset.
No, this was not written using any form of AI but rather NI or PI, i.e. natural or personal. Speaking…in the AI world we find ourselves in of late, does this mean that “common sense” will soon be known as CI?
What happens to outliers who just happen to have a large vocabulary? Do they start getting accused of using AI even when they wrote the thing themselves?
That was the thought that originally sparked my comments above. Not sure why they appear as a reply to “Me” when I didn’t do that.
Most likely. Anyone who opened many books as a kid has been accused of sounding like a dictionary/thesaurus; accusing a studious academic type of sounding like a robot seems like a no-brainer. Which is fortunate for the accusers, as that leaves them a surplus of one-half.
As an individual who has always had an excessive vocabulary and has always enjoyed using it, I feel targeted.
the thing is, we’re not so different from chatgpt. we will radically restructure our language usage in the presence of a new pattern of speaking. people have made a big deal about the fact that all future AI systems will be trained on data in part generated by AI. but natural intelligence also will be trained on data in part generated by AI.
at the margins, some people are surely avoiding chatgpt directly but nonetheless changing their vocabulary because of it.
Great, just great. I’m sure there will be punishment for those of us who indulge in ebullient persiflage.
Hi, just a question: What’s the best way to optimize for voice search?