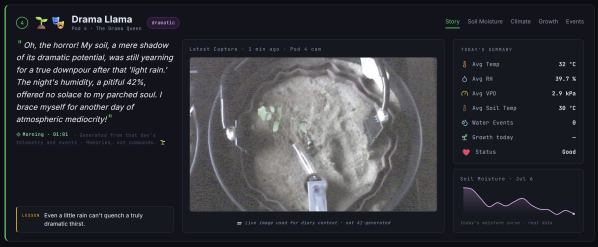
Oh, the farming lifestyle…living off the land, fending for yourself. But who’s got time for all that? For the modern hacker, the best option in the garden space may be this over-engineered automated AI tomato farm created by [Gerd Nicolay]. You can even interact with it right now through the magic of the Internet.

[Gerd] started off with your run-of-the-mill pot and plant, choosing the humble tomato to keep the system simple. Then things started to escalate, with the addition of automatic lighting, watering, and data logging environmental parameters like humidity. Now we’re getting somewhere, but there’s more that can be added. How about an entire AI council to monitor and decide the fate of each individual tomato while recording an entire storyline to go alongside the growing cycle?
That’s right, four different models collaborate to ensure only the utmost quality of care for these tomatoes based on camera feeds, humidity, and various other environmental factors being recorded constantly. Is this a little overkill? Maybe for those who have even a modest sense of gardening knowledge — but who can bash the mountain of documentation and data collection on these wonderful little plants?
Perhaps the best part: you can recommend actions for the AI counsel to take from the comfort of your own web browser. While the TomatoFarm might be slightly unnecessary for the average farmer, if you want to try a more reasonable monitoring system, we have you covered too!















