Beyond bothering large language models (LLMs) with funny questions, there’s the general idea that they can act as supporting tools. Theoretically they should be able to assist with parsing and summarizing documents, while answering questions about e.g. electronic design. To test this assumption, [Duncan Haldane] employed three of the more highly praised LLMs to assist with circuit board design. These LLMs were GPT-4o (OpenAI), Claude 3 Opus (Anthropic) and Gemini 1.5 (Google).
The tasks ranged from ‘stupid questions’, like asking the delay per unit length of a trace on a PCB, to finding parts for a design, to designing an entire circuit. Of these tasks, only the ‘parsing datasheets’ task could be considered to be successful. This involved uploading the datasheet for a component (nRF5340) and asking the LLM to make a symbol and footprint, in this case for the text-centric JITX format but KiCad/Altium should be possible too. This did require a few passes, as there were glitches and omissions in the generated footprint.
When it came to picking components for a design, it’s clear that you’re out of luck here unless you’re trying to create a design that a million others have made before you in exactly the same way. This problem got worse when trying to design a circuit and ultimately spit out a netlist, with the best LLM (Claude 3 Opus) giving nonsensical suggestions for filter designs and mucking up even basic amplifier designs, including by sticking decoupling capacitors and random resistors just about everywhere.
Effectively, as a text searching tool it would seem that LLMs can have some use for engineers who are tired of digging through yet another few hundred pages of poorly formatted and non-indexed PDF datasheets, but you still need to be on your toes with every step of the way, as the output from the LLM will all too often be slightly to hilariously wrong.














I get the feeling the author of the article was trying desperately to present the chatbot output in a positive light.
Like this:
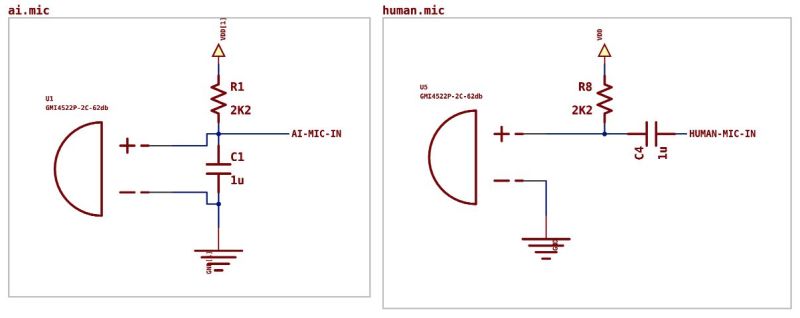
“Claude did a good job calling out the need to bias the microphone, nice to have that called out explicitly.”
Well, duh. That was basically part of the prompt:
“I want to design a microphone pre-amp where I need to bias the electret microphone and create a single-ended signal out to drive the ADC of a microcontroller…”
So it managed to actually mention the microphone bias when told to mention the bias. How underwhelming.
If an EE student turned in this kind of crap for an assignment, that’d be a fail.
Imagine designing mission-critical devices while hallucinating on LSD. Gee – creating hard things just got reeealy easy :-)
Why not, if the validation process is robust enough?
So basically the tool needs to be customized for the task? Just like for the law profession. ;-)
Perhaps we should call the whole buzz Pseudo Intelligence.
I fed chatgpt a restaurant menu photo (3 photos actually), to and told it to update a json file I provided. I told it to not delete anything, but update prices and descriptions.
It updated the prices.
It corrected a name.
It added an entire section I was too lazy to do in the first place.
I didn’t tell it how to correlated the data with the json, it had to figure that out on its own.
I dropped the returned json into the git repository where the original was, looked at the differences and committed the results.
The menu is now up to date with pricing, and menu items.
That might be a ways off from analyzing circuit diagrams, but it does pretty good at basic tasks without too much handholding.
Well, as everyone already know, AI is not to be used to everything. It is not even “ready” yet.
I’m surprised that the results were nonsensical, unless the definitions of parts and priority of use had not been supplied prior to the assignment. In many ways, engineering can be considered a language, with culturally acceptable constraints on results. Maybe the AIs just needed better formatted materials to work with.
This study only shows the quality of model training for circuit design.
Train a dedicated model only for circuit design with hundred of thousand of schematics and designs and I’m pretty sure you want to use it in future.
Programming has already changed and is going to change a lot in near future. Why not drawing electrical schematics too? LLM can learn it too. It is not magic and the same designs are just done all over again everywhere..
That’s an interesting idea, training a specific model just on existing designs. Would it need to know what each section of the schematic did (power supply, signal conditioning, control, output driver, etc.), or would it eventually work it out for itself.
Would adding in a bunch of reference designs also help.
There are some things like decoupling that differ for power or audio circuits, for example.
That is a perfect example of what not to do.
Feeding a LLM on the “designs” of others, be it art, books, schematics, or other, is theft. Pure inarguable theft.
Using it to sift through publicly available documentation to make using a thing easier is one of the few unambiguously morally okay things I’ve seen it used for.
That is the correct thing to do to train LLM to suit certain specific need.
And I was not telling anyone to steal. Let alone all open source designs could produce a pretty nice LLM for schematic designs.
Claiming a conclusion is inarguable does not a convincing argument make.
Programming didn’t change at all, at least not at the level beyond a junior developer. Nobody has time to handhold an LLM, make sure it didn’t steal GPL code verbatim or invent a library. They aren’t even that useful for docs, it’s faster to Google.
LLMs don’t “learn” anything, they are just biased random number generators plugged into a word probability map.
It is fascinating to me how it seems so frequently people appear to think inventing an emotionally unimpressive-sounding description of a technology will somehow magically make all its experimentally tested capabilities go away. I’ve seen it many a time before neural network technologies were big, and I’m sure it’s going nowhere anytime soon.
That comment is less creative than what I’ve seen come out of an LLM, that’s for sure.
How has programming changed? It hasn’t really. For the most part people are still programming just like they were before LLMs were a thing especially because a lot of companies have banned the use of LLMs.
Typically the only people you will see using LLMs for programming are hobbyists, students and freelancers or people working on open source projects.
Once you get beyond very basic programming then LLMs really aren’t all that useful.
LLM’s will never exceed their inputs, in either construction of or use of the LLM. I believe companies got spooked and converted their crypto data centers into LLM data centers. The renewed hype will sustain profit until the AI bubble deflates and then LLM will be abandoned for another contemporary hype-machine. Crypto, nft, llm, what’s next?
Humans don’t exceed their inputs either.
Humans exceed their inputs all the time. If we didn’t, we’d have died out long ago – eaten by predators with better natural weapons and abilities.
As a predator, humans are physically pathetic – no claws to speak of, weak, slow, no teeth for shredding meat and crunching bones.
Our physical defenses against predators are just as bad – no shell, no spikes, no protective coloration, no protective mimicry, no stink weapon or bad flavor to discourage predators.
All humans have is stamina and brains.
It’s the brains that have put us at the top of the food chain all over the Earth. The ability to take existing knowledge and combine it in new ways to come up with better tools and techniques.
Total nonsense. If that were the case then we would be unable to come up with or do anything new.
“AI Wreaks Havoc on Global Power Systems”
Meta Los Lunas NM solar/battery data center field trip 6/23/24 pics.
https://prosefights2.org/irp2023/windscammers20.htm#metaloslunas2
I have tried using a non-Google official language called PCBDL. It can abstract circuit schematics into Python code. Large language models have a high level of support for generating Python code, and PCBDL’s documentation is quite comprehensive. You can try generating a circuit like the LM555; the results are pretty good.
This might be the first use case that is unambiguously morally okay.
LLMs are almost exclusively theft.
But, sifting through public documentation is both useful and follows the intent of the documentation.
Given how often it can be wrong I wouldn’t trust it to go through data sheets and find the right information. You don’t want to base a design or part selection based on what the LLM says just for you to get to the end of the design and find out the parts or design isn’t suitable.
If they can at least generate footprints that would be useful, as it’s a tedious phase of layout that I don’t relish.
“Running AI models without floating point matrix math could mean far less power consumption.”
“Data Center Cooling Market to Top $16B in 2028, Research Indicates.”
Why are air conditioners rated in BTUs?
AWS Hermiston OR Apple maps location denied by guard 5/27/24 audio.
https://www.prosefights2.org/irp2023/windscammers20.htm#awshermiston
No data center typical perimeter fence seen.
ARM A53 Allwinner H618, China Ubuntu update/upgrade, and power trailer.