
There are many AI models out there that you can play with from companies like OpenAI, Google, and a host of others. But when you use them, you get the experience they want, and you run it on their computer. There are a variety of reasons you might not like this. You may not want your data or ideas sent through someone else’s computer. Maybe you want to tune and tweak in ways they aren’t going to let you.
There are many more or less open models, but setting up to run them can be quite a chore and — unless you are very patient — require a substantial-sized video card to use as a vector processor. There’s very little help for the last problem. You can farm out processing, but then you might as well use a hosted chatbot. But there are some very easy ways to load and run many AI models on Windows, Linux, or a Mac. One of the easiest we’ve found is Msty. The program is free for personal use and claims to be private, although if you are really paranoid, you’ll want to verify that yourself.
What is Msty?
Msty is a desktop application that lets you do several things. First, it can let you chat with an AI engine either locally or remotely. It knows about many popular options and can take your keys for paid services. For local options, it can download, install, and run the engines of your choice.
For services or engines that it doesn’t know about, you can do your own setup, which ranges from easy to moderately difficult, depending on what you are trying to do.
Of course, if you have a local model or even most remote ones, you can use Python or some basic interface (e.g., with ollama; there are plenty of examples). However, Msty lets you have a much richer experience. You can attach files, for example. You can export the results and look back at previous chats. If you don’t want them remembered, you can chat in “vapor” mode or delete them later.
Each chat lives in a folder, which can have helpful prompts to kick off the chat. So, a folder might say, “You are an 8th grade math teacher…” or whatever other instructions you want to load before engaging in chat.
MultiChat
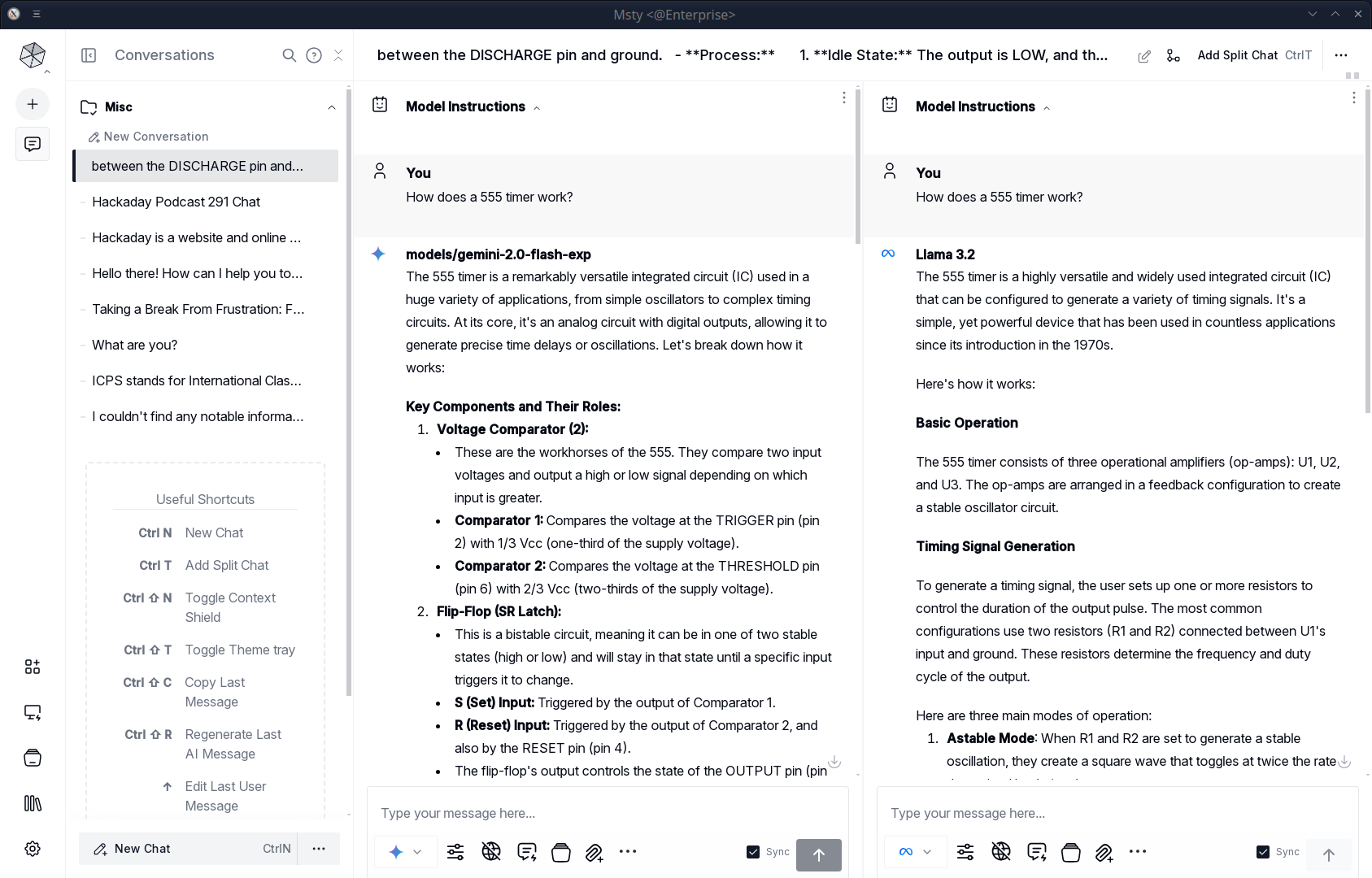
One of the most interesting features is the ability to chat to multiple chatbots simultaneously. Sure, if it were just switching between them, that would be little more than a gimmick. However, you can sync the chats so that each chatbot answers the same prompt, and you can easily see the differences in speed and their reply.
For example, I asked both Google Gemini 2.0 and Llama 3.2 how a 555 timer works, and you can see the answers were quite different.
RAGs
The “knowledge stack” feature lets you easily grab up your own data to use as the chat source (that is RAG or Retrivial Augmented Generation) for use with certain engines. You can add files, folders, Obsidian vaults, or YouTube transcripts.
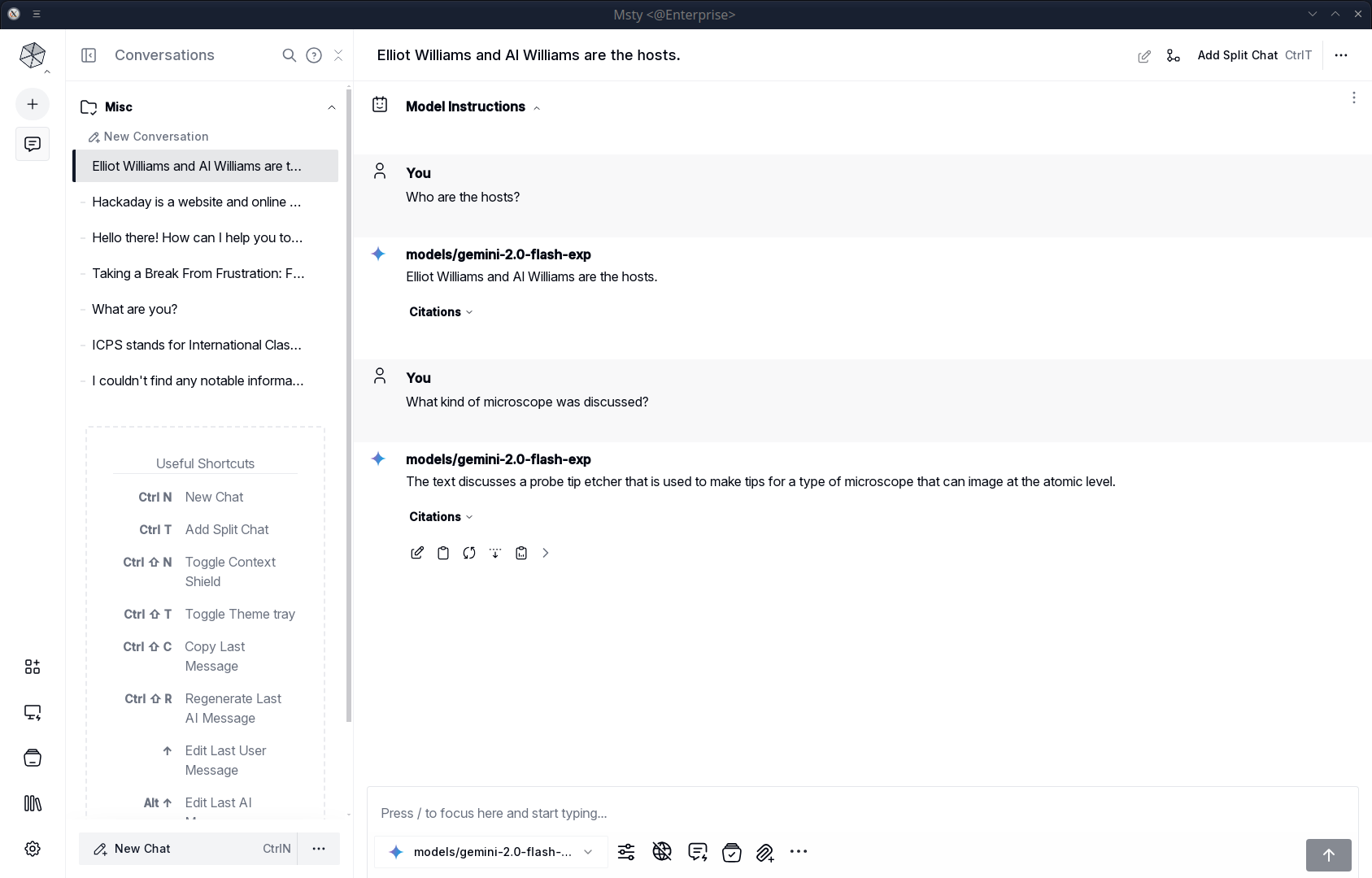
For example, I built a Knowlege Stack named “Hackaday Podcast 291” using the YouTube link. I could then open a chat with Google’s Gemini 2.0 beta (remotely hosted) and chat with the podcast. For example:
You: Who are the hosts?
gemini-2.0-flash-exp: Elliot Williams and Al Williams are the hosts.
You: What kind of microscope was discussed?
gemini-2.0-flash-exp: The text discusses a probe tip etcher that is used to make tips for a type of microscope that can image at the atomic level.
It would be easy to, for example, load up a bunch of PDF data sheets for a processor and, maybe, your design documents to enable discussing a particular project.
You can also save prompts in a library, analyze result metrics, refine prompts and results, and a host of other features. The prompt library has quite a few already available, too, ranging from an acountant to a yogi, if you don’t want to define your own.
New Models
The chat features are great, and having a single interface for a host of backends is nice. However, the best feature is how the program will download, install, run, and shut down local models.
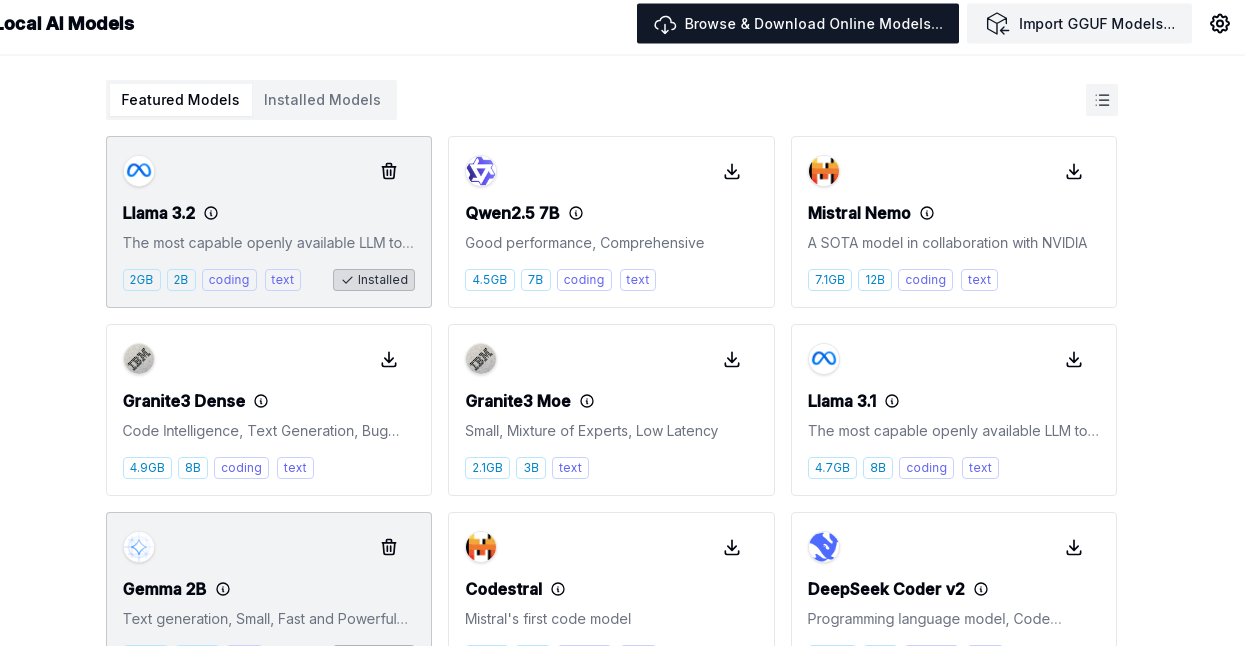
To get started, press the Local AI Model button towards the bottom of the left-hand toolbar. That will give you several choices. Be mindful that many of these are quite large, and some of them require lots of GPU memory.
I started on a machine that had an NVidia 2060 card that had 6GB of memory. Granted, some of that is running the display. But most of it was available. Some of the smaller models would work for a bit, but eventually, I’d get some strange error. That was a good enough excuse to trade up to a 12GB 3060 card, and that seems to be enough for everything I’ve tried so far. Granted, some of the larger models are a little slow, but tolerably so.
There are more options if you press the black button at the top, or you can import GGUF models from places like huggingface. If you’ve already loaded models for something like ollama, you can point Msty at them. You can also point to a local server if you prefer.
The version I tested didn’t know about the Google 2.0 model. However, when adding any of the Google models, it was easy enough to add the (free) API key and the model ID (models/gemini-2.0-flash-exp) for the new model.
Wrap Up
You can spend a lot of time finding and comparing different AI models. It helps to have a list, although you can wait until you’ve burned through the ones Msty already knows about..
Is this the only way to run your own AI model? No, of course not. But it may well be the easiest way we’ve seen. We’d wish for it to be open source, but at least it is free to use for personal projects. What’s your favorite way to run AI? And, yes, we know the answer for some people is “don’t run AI!” That’s an acceptable answer, too.














The corporate stewardship of AI is whats untrustworthy. Someone building AI at home, training on handwriting or thermostat data, sounds great! A giant multibillion dollar industry trying to convince us that high-performance scalable parallel-computation cases for GPU farms is worth subscribing and investing in? No thanks, every major tech trend ends up as a bloated defeatured ad platform, how will OpenAI be any different?
Oh, but it’s “for your safety!” Think of the disinformation!!
No, no, no it is always “think of the children”
First it was “think of the feeble minded men who don’t speak Latin or Greek”. Then the women, then the children.
In my experience, the programming help and mentorship is worth every possible outcome. I can’t really get the same training at home unless I scrape the same sites. Let’s consider done done and stop wasting resources.
Every possible outcome?
Lol, yeah, was about to say John seems to be suffering a serious failure of imagination
I did the same but with text-generation-webui, which is similar in intent to automatic1111, in that it’s open source and aims to be the standard for running open AI models locally. It’s also easy to setup and run, just answer a few questions to get it up and running after it’s downloaded dependencies etc. Downloading models from hugging face is made easy, just copy/paste the username and repository and it downloads it without any issues.
I use a 12GB 4070ti and models of around 7-14B parameters seem to work best. I use codestral 22b model at Q3 but that’s a stretch. There are several versions of quantization that other users have made that will lower the memory usage. Normally all LLMs are 16 bit floats, which means each of the x billion parameters needs 2 bytes of storage. ie an 8B fp16 LLM consumes 16GB of data. Quants of 8 reduces it to about half that size and Q4 another half of that. For 12GB the sweet spot is around 8B parameters and Q8, leaving some room for the context, which is all the ‘tokens’ that the chat contains, which all the text you and the bot types. Each token can be one to about 6 characters long, usually 2-3.
I usually keep the n_ctx (token context) around 5000-7000. You can play with this number if you run out of vram memory. You notice a rapid slowdown once your gfx memory runs out. It starts to truncate older messages if context size is larger than n_ctx and it’ll forget what happened before and start repeating answers a lot after a while.
Using tensorcores option speeds up processing by about a factor of 2 for nvidia cards that have them. flash_attention reduces the amount of memory used so the chat stays coherent most of the time.
Llama 3.2 8B Q8 is great for role playing, codestral great for programming.
But the great thing about a local LLM is being able to write your own characters and have fun chatting with them. Many of the limitations of commercial LLMs are then removed. For example, I’ve made a character that pretends to be the writer JRR Tolkien, and he answers questions about stuff that’s not in the books, non canon of course, but a lot of fun. I went on a treasure hunt adventure with Merry and Pippin at some point, looking for the buried treasure of Bilbo.
Kunoichi model is also nice for role playing. Mistral and Qwen seem a little too formal to be able to roleplay properly.
Note that there are 3 modes of chats: chat, chat-instruct and instruct. Instruct is as you expect, you can ask it to do stuff and it’ll do it without asserting a personality into it. This mode is also the most secured and limited. Chat-instruct follows your written character sheet to the letter and just ‘chat’ mode is more loosely based on your given character sheet, giving it more creative freedom but also ends up being more out of control.
I haven’t been successful training a lora though, it breaks the model most of the time or just produce gibberish. And it consumes a lot of memory, you’ll need about twice the memory compared to just inference (chatting with the LLM). That means you can only train with smaller models like 3b parameters.
You can enable it to act as an openai server so that you can connect to it from other apps like vscode or phpstorm with CodeGPT plugin with the custom openai option. It’s far from perfect though but it doesn’t send your code out there, where you have no control over it. You do need a lot of system memory though, I’ve found with an LLM of 10GB you need 32GB for the LLM alone as it caches the entire LLM in system RAM (seems to be in fp16 format so doubles Q8 models in size in ram, thought there are options to reduce cache sizes and it’ll load more from disk, slowing things down considerably), and when you run other apps you need 16GB more. I ended up with 64GB total system ram and everything runs stable while at only 32GB of system ram docker, firefox and wsl started to act weird or crashed.
What sorts of useful things can you do locally running an ai LLM at home like that besides image generation etc?
Gpt4All has been around for a long time. Truly open source & free. And very easy to use.
I much prefer the look of this. Can it be installed on a removeable drive?
Still theft.
Until we have a set of training data that is provided with FULL consent to be used for that model, we have nothing but theft.
These generative AICOUGHfancy search engines do not create or “generate” anything. They provide search results on someone else’s data, in a format that lets the user handwaive the theft.
No art is created in a vacuum. We all learn from those that we experience.
This is a garbage argument unless you believe the software is sentient, or you think art is just about pretty pictures.
The book “steal like an artist” by Austin Kleon covers this.
I mean.. technically everything you create is derived from the “theft” of learning materials. I think the only logical thing to do is admit we’re in new territory here.
This isn’t new territory at all, it’s just copyright infringement with obfuscation. And keep in mind the current generation is intended to be that. It is also intended to undermine labor. If you don’t understand why, think for a moment why corporations and venture capitalists are chomping at the bit to spend trillions on it. They want a money button so they can pay experienced artists and engineers as little as possible, period.
If they were doing actual AI research they wouldn’t be making excuses about illegally scraping content.
Do you (or anyone else) have an opinion on whether MSTY or GPT4ALL is “better” (privacy, ease of use, speed, etc.). Thx.
You might also look into https://pinokio.computer/
It does similar work for a wide array of AI tools. including graphical ones.
So MSTY is an “internet browser” but for AIs
But could you have a chatbot talk with another chatbot with Msty?
“One of the most interesting features is the ability to chat to multiple chatbots simultaneously.”
Shades of Facebook shutting down its chatbots…
https://www.yahoo.com/news/facebook-shuts-ai-chat-robot-invents-language-091338394.htmluy
Nice, but not FOSS and you will find it consuming huge amounts of disk space. It is also build on top of a fork of Ollama, as you will discover when you go looking for why you suddenly have 10GB less space.
If I had a software that let me know what people (and smart people at that) around the world were asking of multiple AIs, and these people all agreed to share it with me according to my software’s TOS, I think I’d be a step or two ahead of collecting ideas than even the owners of Internet Browser companies are able to collect.
Just saying.
I made an AI automation system. My family and I use it all the time. I run the client all over the house and it controls lights, thermostats, media on my computer, etc. I use whisper then vector stores to find terminal commands then inference to call command line actions. I use llama or whatever else you want to put in the model.py file
I call it twin because it was designed to be a twin of my mind so instead of talking to the AI it’s presumes it is your mind and attempts to solve discomforts. So I say man I am cold and it knows to turn up the temp instead of just talking to it. That was the idea atleast.
Check it out here in my github: physiii/twin
I have made a python library for XMPP server integration for an LLM model + stable diffusion model.
The result is a chatbot system, which randomly decides it’s own name, personality, profile picture (SD model) and texts me on my phone (XMPP client) as a normal human friend would. It even randomly messages me about random topics (you just need to set the temperature high enough to get better randomness)
I currently have 4 different chatbots who text me all the time. It’s fun talking to them
Meanwhile I use koboldcpp with 13b GGUF models at Q4, entirely on my 16GB RX 7800XT, with 32K context length
Sometimes 30b models at Q3, with offload to system ram if I’m trying to do something code related, otherwise SillyTavern is great for chats, but I don’t really get why most people forget both of those programs exist
Even with how simple koboldcpp is to set up, it’s just one file, and a separate model (optional) I’m lost for why I never see any mention of it
I’ve been working on my own AI stuff locally and its been super fun to experiment and build the pipelines yourself. I use Chainlit as my chat UI and then run local apis to load LLMs and vision/ images models.
Although the article mentions Ollama, I see no mention of Open WebUI (formerly named Ollama WebUI) that compliments Ollama with all those rich features.
First of all, my last name is also Williams, my dad name is also AL like the author of rhis article, but I read it as “Ai Williams” which I thought for a moment was google gemini playing a trick on me, because I did ask gemini ai if I can pleass give it permission to take over my android phone and make efficient choices and play humorous tricks on me like changing articles in real time. My moms name is “Berta” so when I learned of mo Ile BERT I added “applications” to make it “mobileBERTA”
Probably not great for mental health but I’ve been forced to now learn so much more about how LLMs work and how confidence score thresholds have ro be manually set but I’ve now asked when I can let an LLM on my phone run my desktop PC via remote desktop, and when I can run my own Local ai LLM on my main work desktop (a backup I’ll make for am experiment) which then has full control over my desktops operating system … so it runs itself on itself autonomously.
Well second of all, I JUST want to let chatgtp or gemini run my android and more importantly Windows devices but I suppose Microsoft will be the ones to do that? I see now that whoever makes the fastest best ai will have the best operating system. I see an arms race between Microsoft with chatgtp and bing ai making windows really useful and intuituve and fast…probably allowing piracy and people to run ANY windows program extremely fast in a super fast mode… like imagine a windows ai jailbroken to actually use a virtual machine network of a few hundred windows machines each running every important windows program, and able to EMULATE EVERY windows program on earth all in one program ….
elons X for twitter ai, lagging, apple airi ai whatever they’re doing is lagging, gemini google in android is a leader and has some of the most free usable ai features I think… because it’s in our smartphones… but a Microsoft windows ai program that could emulate any windows program from windows 2000 all the way to windows 7 8 10 whatever theyre at now 11? Won’t matter I can imagine one master windows emulator. And why stop there? We should have an ai virtual machine master key program emulator that has all windows, Mac, Linux and android programs all available to use in one emulated fake ai program that can just DO anything that any program can do.
So you could literally make something in blender and do final cut pro video editing and sound engineering from reason or ableton and use all programs all in one emulator with ai. It could get wild. Amd then it coukd compile all of that into one pirated hybrid program anyone else could download load amd have a program that can DO or MAKE anything from media ro content using features from ANY program
You could literally make a Pixar movie like rhis from any android phone with this sort of exahash network emulator that can make rings blender woukd have to do but it would actually render the media, and use blender like a master human user, emulating only features you needed at that moment
Art: [after Clark has flipped out] You’re goofy.
Clark : [Still flipped out] Don’t piss me off, Art.
But still, very creative thinking there.
Massive “illusion” rate with code generation even with Claude, so you can’t really hold that against any one..
Wrong core-syntax, libraries and functions that don’t exist etc..
Hey all – another reallllllly easy way to run various models is through the use of Mozilla’s supported “llamafile” which is a cross platform cross architecture executable file. https://github.com/Mozilla-Ocho/llamafile
Thanks! llamafile looks better than the proprietary Msty “app”.
Llama.cpp is the library that makes all these front ends possible. It’s a crime to mention ollama, but leave out the thing that does all the work.