Like a lot of people, we’ve been pretty interested in TensorFlow, the Google neural network software. If you want to experiment with using it for speech recognition, you’ll want to check out [Silicon Valley Data Science’s] GitHub repository which promises you a fast setup for a speech recognition demo. It even covers which items you need to install if you are using a CUDA GPU to accelerate processing or if you aren’t.
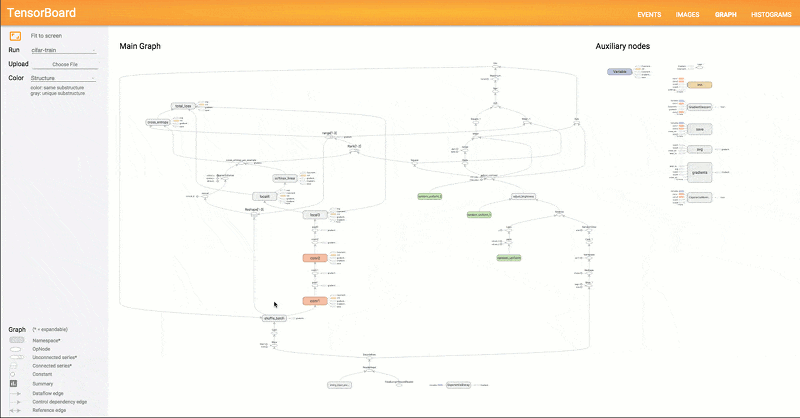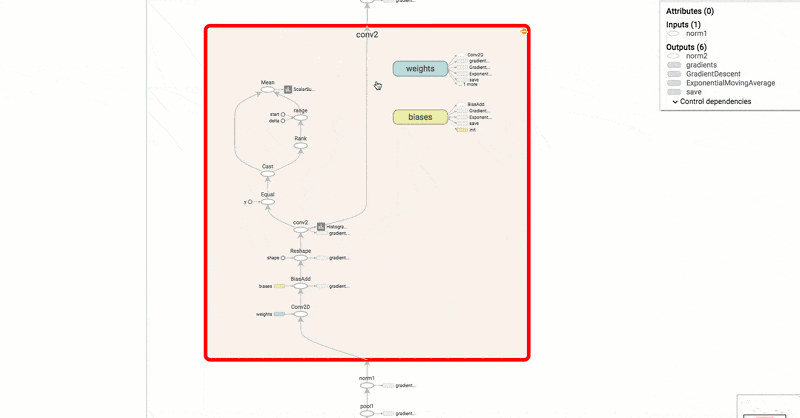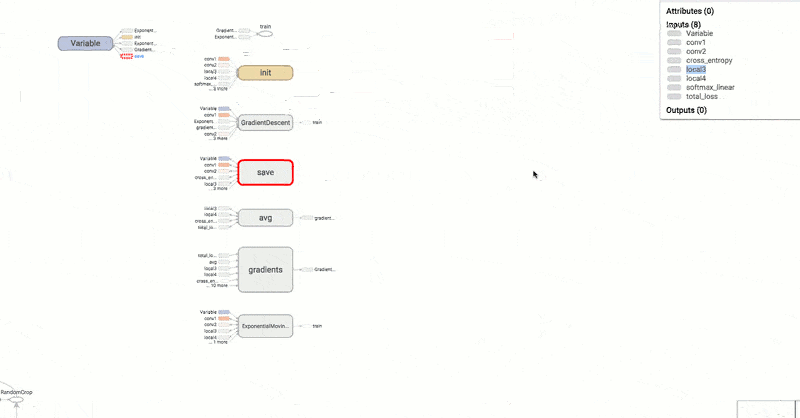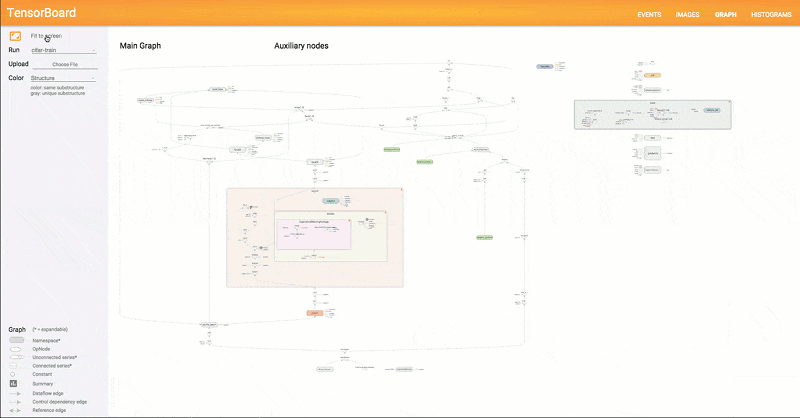
Another interesting thing is the use of TensorBoard to visualize the resulting neural network. This tool offers up a page in your browser that lets you visualize what’s really going on inside the neural network. There’s also speech data in the repository, so it is practically a one-stop shop for getting started. If you haven’t seen TensorBoard in action, you might enjoy the video from Google, below.
This demo might be a good second step after you complete the very simple tutorial we covered earlier. This isn’t the first time we’ve looked at neural nets and speech, but it may be the simplest one we’ve seen.














That is very interesting, but how can I use these high level tools to generate a neural network, then bake it down to embedded hardware? I found a 2016 reference to TensorfFow having FPGA support, but that reference was a complaint about it being removed without explanation.
Unless it’s a problem simple enough that you can distill into a simple FPGA or run on a microcontroller (speech recognition is way out of this range), right now the options are either running it in the CPU on an ARM, or if you need the extra power, go with a Jetson TX1 or 2.
There’s also the popular option of sticking it on a server in the “Cloud”, but that’s no fun.
Interesting, do you know of any public data that shows the sort of network complexity for solved tasks? Is there some metric that is a bit more than rule-of-thumb? FPGAs can get rather large these days so it would be useful to know.
Usually the problems you throw at a NN are the sort of problems where you have no idea how to solve explicitly, so it tends to be very hard to estimate how large and how processing-intensive they are until you have already designed and tested the solution.
The first problem with trying to fit a usual NN solution on a FPGA is that the solutions you come up with something like TensorFlow are based on doing an enormous number of floating-point multiplications and additions, which doesn’t translate very well to the usual FPGA design. And for an example of the number of parameters on those solutions, the top solutions to the 1000-category ImageNet classification usually have between 10M~50M parameters.
Now, if you have some problem to solve and really would like to use an FPGA for it, I’d recommend trying to evolve a native solution on the FPGA, like this:
http://hackaday.com/2012/07/09/on-not-designing-circuits-with-evolutionary-algorithms/
I think that is the best way forward, you can even evolve AVR code using emulators.
There are floating point libraries that go onto an FPGA, some of them even open source. Some easy Google-fu and you can find them.
Really, you only need one single floating point unit, and keep it as busy as possible. I can imagine architectures to make this happen. Of course running a NN is clearly a much easier problem than training one.
Since you can also put pretty much any arbitrary CPU design onto an FPGA (given certain size limitation), it is obviously wrong to that that an FPGA could not run it.
yah it’s not a truly smart device if it has to use processing power located on the cloud.
that makes it thin, right?
/tinfoilhat *ON* The NSA said Google couldn’t opensource their cool FPGA based AI, using special letterhead only people with a Q clearance can read, so the feature got pulled. /tinfoilhat *OFF*
You can build the easybake features yourself, and opensource them so us plebs can use them? (Please?) :-) Otherwise, get your knees dirty with Google and the DoD ^_^
If you’re comfortable reading research papers there’s a lot out there about optimizing neural networks for limited hardware, using FPGAS, or designing custom hardware. Most of the papers have codecided on github if you search.
Check out:
Deep Compression: https://arxiv.org/abs/1510.00149
SqueezeNet: https://arxiv.org/abs/1602.07360
ZynqNet (masters thesis with code that implements SqueezeNet on a Zynq SOC): https://github.com/dgschwend/zynqnet
Oh thanks, very nice, exactly what I was thinking about.
https://github.com/dgschwend/zynqnet/raw/master/toplevel_project_overview.jpg
Can anyone point me towards a beginner level tutorial on machine reading? As in – feed it text, lots of text, and get some sort of useful output like a million virtual fanfiction writers.
https://pdos.csail.mit.edu/archive/scigen/
Look up “Markov Chain”. The technique is as old as the hills, but works very well to generate bogus text (and autotype suggestions).
You may want to look at Recursive Neural Networks (RNN). The most famous implementation I know is the one from Andrej Karpathy: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471#.s51nhev3x
Not a predictive text example, but a very good ans simple introduction.
Google | All You Say Belong To US!