
I was buying a new laptop the other day and had to make a choice between 4GB of memory and 8. I can remember how big a deal it was when a TRS-80 went from 4K (that’s .000004 GB, if you are counting) to 48K. Today just about all RAM (at least in PCs) is dynamic–it relies on tiny capacitors to hold a charge. The downside to that is that the RAM is unavailable sometimes while the capacitors get refreshed. The upside is you can inexpensively pack lots of bits into a small area. All of the common memory you plug into a PC motherboard–DDR, DDR2, SDRAM, RDRAM, and so on–are types of dynamic memory.
The other kind of common RAM you see is static. This is more or less an array of flip flops. They don’t require refreshing, but a static RAM cell is much larger than an equivalent bit of dynamic memory, so static memory is much less dense than dynamic. Static RAM lives in your PC, too, as cache memory where speed is important.
For now, at least, these two types of RAM technology dominate the market for fast random access read/write memory. Sure, there are a few new technologies that could gain wider usage. There’s also things like flash memory that are useful, but can’t displace regular RAM because of speed, durability, or complex write cycles. However, computers didn’t always use static and dynamic RAM. In fact, they are relatively newcomers to the scene. What did early computers use for fast read/write storage?
Drums
Surprisingly, drum memory–a similar technology to a modern hard drive–first appeared in 1932 for use with punched card machines. Although later computers used the technique as secondary storage (like a modern hard drive), some early machines used it as their main storage.
Like a hard drive, a drum memory was a rotating surface of ferromagnetic material. Where a hard drive uses a platter, the drum uses a metal cylinder. A typical drum had a number of heads (one for each track) and simply waited until the desired bit was under the head to perform a read or write operation. A few drums had heads that would move over a few tracks, a precursor to a modern disk drive that typically has one head per surface.
The original IBM 650 had an 8.5 kB drum memory. The Atanasoff-Berry computer used a device similar to a drum memory, but it didn’t use ferromagnetic material. Instead, like a modern dynamic RAM, it used capacitors.
Drum storage remained useful as mass storage for a number of years. If you ever use BSD Unix, you may notice that /dev/drum is the default swap device, an echo to the time when your paging store on a PDP-11 might well have been a drum. You can see an example of a drum storage unit at the Computer History Museum in the video below.
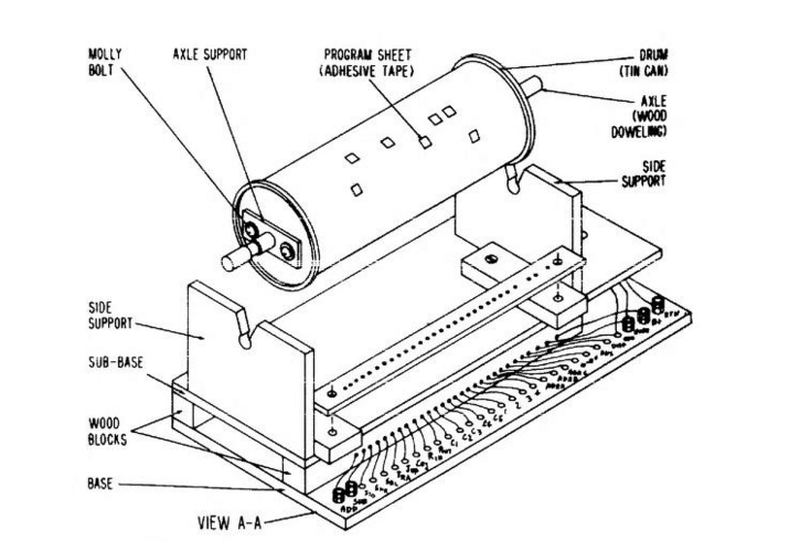 Another design clearly influenced by drum memory was the homemade computer from the book “Build Your Own Working Digital Computer” in 1968. The main program storage was an oatmeal container covered in foil and paper with instructions punched out in the paper (see right).
Another design clearly influenced by drum memory was the homemade computer from the book “Build Your Own Working Digital Computer” in 1968. The main program storage was an oatmeal container covered in foil and paper with instructions punched out in the paper (see right).
The Williams Tube
One of the first electronic mechanisms for storing information was a Williams (or Williams-Kilburn) tube. Dating back to 1946. The device was essentially a cathode ray tube (CRT) with a metal plate covering the screen. Although many Williams tube memories used off-the-shelf CRTs with phosphor on the screen, it wasn’t necessary and some tubes omitted it.
 Creating a dot at a certain X and Y position on the CRT would cause the associated area to develop a slightly positive charge, due to secondary emission. This also caused the surrounding area to become slightly negatively charged. Placing a dot next to a spot erases that positive charge. If there was no positive charge to start with, the attempt to erase would cause another area of charge.
Creating a dot at a certain X and Y position on the CRT would cause the associated area to develop a slightly positive charge, due to secondary emission. This also caused the surrounding area to become slightly negatively charged. Placing a dot next to a spot erases that positive charge. If there was no positive charge to start with, the attempt to erase would cause another area of charge.
By monitoring the plate while writing these probing dots, you can determine if there was previously a charge on the screen at that position or not. Although you normally think of a CRT as sweeping left to right and up and down, there’s no reason that has to be true, so the Williams tube could perform random access.
There are two problems, of course. One is, like dynamic memory, the charge on the CRT eventually fades away, so the CRT needs a refresh periodically. The other is that reading the Williams tube destroys the information in that bit, so every read has to have a corresponding write to put the data back.
A typical tube could hold between 1K and 2K bits. It is interesting that the Manchester SSEM computer was actually built just to test the reliability of the Williams tube. One interesting feature for debugging is you could connect a normal CRT in parallel with the storage tube and visually see the memory in real time.
Although the Williams tube found use in several commercial computers, it tended to age and required frequent hand tuning to get everything working. Can you imagine if every time you booted your computer you had to manually calibrate your memory? Google produced an excellent video about the SSEM and the Williams tube that you can find below.
RCA worked hard on producing a more practical version of the Williams tube known as the Selectron tube. The goal was to make something faster and more reliable than a Williams tube. In 1946, RCA planned to make 200 units of a tube that could store 4096 bits. Production was more difficult than anticipated, however, and the only customer for the tube went with a Williams tube, instead, to avoid further delays. Later, RCA did produce a 256-bit version (for $500 each–so 5 tubes would have bought a new 1954 Corvette). They were only used in the RAND Corporation’s JOHNNIAC (although, in all fairness, the machine used over 1,000 of the tubes–the cost of 200 new Corvettes).
Mercury Delay Lines
 Another common form of memory in old computers was the mercury delay line. I almost didn’t include it here because it really isn’t random access. However, many old computer systems used it (including some that also used a Williams tube) and it was used in the UNIVAC I.
Another common form of memory in old computers was the mercury delay line. I almost didn’t include it here because it really isn’t random access. However, many old computer systems used it (including some that also used a Williams tube) and it was used in the UNIVAC I.
The 1953 patent for this memory actually doesn’t limit the delay medium to mercury. The key was to have some kind of element that would delay a signal by some amount of time. This could be done through other means as well (including a proposal to use rotating glass disks).
Mercury was expensive, heavy, and toxic. However, it is a good acoustic match for quartz piezoelectric crystals, especially when kept heated. That’s important because that’s how the delay line works. Essentially, bits are represented by pulses at one end of a long tube of mercury and received at the other end. The amount of time it takes to arrive depends on the speed of sound in mercury and the length of the tube.
Obviously, reading data at the end of the tube removes it, so it is necessary to route bits back to the other side of the tube so that the whole process can repeat. If you didn’t want to write any new data, you can imagine all the bits as travelling in the mercury, the first bit at the output, followed by each subsequent bit, all travelling at the same speed (about 1,450 meters per second, depending on temperature). Depending on the length of the bit pulse and the length of the column, you could store 500 or 1000 bits in a practical tube.
To read the data, a quartz crystal on the output side converted the pulses to electrical energy. To write data, the computer could insert a new bit into the stream instead of recirculating an old one. EDSAC used 32 delay lines to hold 512 35-bit words (actually, the mercury tubes held more data, but some were used for housekeeping like tracking the start of the data; a later project doubled the computer’s memory). UNIVAC I held 120 bits per line and used many mercury columns to get 1000 words of storage. You can see the UNIVAC’s memory in the video below.
Dekatron
 The dekatron is popular today among the Nixie tube clock builders that want to move on to something different. As the name implies, the tube has 10 cathodes and a gas (usually neon, although sometimes hydrogen) inside. Charge can be moved from cathode to cathode by sending pulses to the device. The tube can act as a decimal counter but it can also store decimal digits.
The dekatron is popular today among the Nixie tube clock builders that want to move on to something different. As the name implies, the tube has 10 cathodes and a gas (usually neon, although sometimes hydrogen) inside. Charge can be moved from cathode to cathode by sending pulses to the device. The tube can act as a decimal counter but it can also store decimal digits.
There were actually two kinds of dekatrons. A counter dekatron has only one connection to all cathodes. This made it like a divider and the number of cathodes (which didn’t have to be 10) determined the division rate. Counter/Selector tubes had separate cathode pins so you could use them as memory or programmable dividers.
Like a Williams tube, the dekatron was memory you could literally see. The Harwell computer, a relay computer from the 1950’s, uses dekatrons as storage. The National Museum of Computing in the UK restored this machine and uses the visual nature of its memory to demonstrate computer concepts to visitors. You can see the machine in action in the video below.
Core Memory
 The most successful early memory was undoubtedly core memory. Each bit of memory consisted of a little ferrite donut with wires threaded through it. By controlling the current through the wires, the donut (or core) could have a clockwise magnetic field or a counterclockwise field. A sense wire allowed the memory controller to determine what direction a specific core contained. However, reading the field also changed it. You can learn more about exactly how it works in the 1961 US Army training film below.
The most successful early memory was undoubtedly core memory. Each bit of memory consisted of a little ferrite donut with wires threaded through it. By controlling the current through the wires, the donut (or core) could have a clockwise magnetic field or a counterclockwise field. A sense wire allowed the memory controller to determine what direction a specific core contained. However, reading the field also changed it. You can learn more about exactly how it works in the 1961 US Army training film below.
https://www.youtube.com/watch?v=X0WnddW5gZI
One nice feature of core memory was that it was nonvolatile. When you turned the power back on, the state of the memory was just how you left it. It is also very tolerant to radiation which is why the Space Shuttle computers used core memory until the 1990s.
Core memory came at a high price. Initially, costs were about $1 per bit. Eventually, the industry drove the price down to about $0.01 per bit. To put that in perspective, I did a quick search on Newegg. Without looking for the lowest price, I randomly picked a pair of 8GB DDR3 1600 MHz memory sticks that were available for just under $69. That works out to about $0.54 per gigiabit. Even at $0.01 per bit, a gigabit of core memory would cost ten million dollars (not counting the massive room to put it all in).
One of the main reasons for the high cost of core memory was the manual manufacturing procedure. Despite several efforts to automate production, most of the work in assembling core memory was done by hand. You assume people got pretty good at it, but it is a difficult task. Don’t believe it? Check out [Magnus Karlsson] video of making his own core memory board, below.
A variation of core memory was the plated wire memory. This was similar in operation, except it replaced the magnetic toroids with plated wire that held the magnetic state information. Another variation, twistor, used magnetic tape wrapped around the wire instead of plating. So-called thin-film memory (used in the UNIVAC 1107) used tiny dots of magnetic material on a glass substrate and also worked like core. The advantage to all these was that automated production was feasible. However, inexpensive semiconductor memory made core, plated wire, and twistor obsolete.
You can see how twistor memory was made below in this AT&T video that is almost like a 1976 edition of “How Its Made.”
Bubble
During the development of twistor memory, researchers at Bell Labs noted that they could move the magnetic field on a piece of tape around. Investigating this effect led to the discovery of magnetic bubble. Placing these on a garnet substrate allowed the creation of non-volatile memory that was almost a microscopic version of a delay line, using magnetic bubbles instead of sound waves in mercury.
When bubble memory became available, it was clearly going to take over the computer industry. Non-volatile memory that was fast and dense could serve as main memory and mass storage. Many big players went all in, including Texas Instruments and Intel.
As you could guess, it didn’t last. Hard drives and semiconductor memory got cheaper and denser and faster. Bubble memory wound up as a choice for companies that wanted high-reliability mass storage or worked in environments where disk storage wasn’t practical.
In 1979, though, Bell Labs declared the start of “The Bubble Generation” as you can see in the video below.
What’s Next?
I’m sure at one time, core memory seemed to be the ultimate in memory technology. Then something else came and totally displaced it. It is hard to imagine what is going to displace dynamic RAM, but I don’t doubt something will.
One of the things that we are already starting to see is F-RAM which is almost like core memory on a chip. Will it (or other upstarts like phase-change RAM) displace current technology? Or will they all go the way of the bubble memory chip? If history has taught me anything, it is that only time will tell.
Credits
Williams-tube by Sk2k52 Licensed under GFDL via Wikimedia Commons.
Mercury Delay Line CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=64409
Dekatron Image by Dieter Waechter – http://www.tube-tester.com/sites/nixie/datdekat/Z303C/z303c.htm, Attribution, https://commons.wikimedia.org/w/index.php?curid=22846430
Ferrite core memory by Orion 8 – Combined from Magnetic core memory card.jpg and Magnetic core.jpg.. Licensed under CC BY 2.5 via Wikimedia Commons.














{kind=link}
{kind=link}
“I’m sure at one time, core memory seemed to be the ultimate in memory technology. Then something else came and totally displaced it. It is hard to imagine what is going to displace dynamic RAM, but I don’t doubt something will.”
I wouldn’t say “dynamic RAM” displaced core. Transistor-based RAM displaced core. Obviously everyone is most familiar with DRAM via memory sticks shoved into their computer, but dynamic RAM alone *never* could have displaced it. For that, you needed static RAM.
Well, I didn’t mean that to say that DRAM displaced core. What I mean is that it is hard to imagine DRAM being displaced today. But in 1986 it was hard to imagine core would be displaced. If you note, I didn’t say what the something else was (and you are right, it was semiconductor memory).
Have to think about if DRAM alone could have never displaced core. I bet it would have, although it would have altered the design of local cache systems.
Intel was making RAM chips intended to replace core, in the early ’70s. By 1986, core was an antique.
The basic technology is still in use, however, in Ferro-Magnetic RAM (FRAM).
No, FRAM is Ferro-ELECTRIC RAM, using a property analagous to dielectric absorbtion to provide the non-vol storage.
You should also mention a variation on delay line memory that uses few loops of wire and electromechanical transducers on the ends to convert electric signals into mechanical distortions of the wire. These memories were used in various calculators because are simple to make and quite reliable. The most popular way of distorting the wire was twisting it by using transducers made of metal tape that was magnetostrictive. Nickel was used for that. Those delay lines are also used as guitar effects too.
Well I did mention that some didn’t use mercury. There were also piezo delay lines. A lot of the audio versions of this got displaced by the bucket brigade CCD devices, I think. Or, at least, they could have.
Yes, they replaced classic delay with BBD devices, which later were replaced with DSP processors. There also used to be tape delays that used multiple heads to read and write a tape loop. Still some people make or use such devices instead of DP processors for their (supposed – I don’t really know) superior quality and unique sound…
First personal computer (The olivetti’s Programma 101 from Italy) used delay line made of wire, something much smaller and cheaper than core.
Yeah, HaD had an article on that a few months back.
A great description is shown there : https://www.youtube.com/watch?v=N9cUbYII5RY
Great article, thank you.
This article reminds me of Mel, a Real Programmer.
The story about him appeared on Usenet in 1983 and it details his uncanny ability to optimized programs stored on a drum memory. You can read the complete story here: http://www.catb.org/jargon/html/story-of-mel.html
I love that story.
Thanks for the great history article! It’s fun to create new things, but we should never forget where we’ve come from.
One minor correction, however – drum memory wasn’t random access by any means, at least not in one of the current senses (same time to access any data). According to my dad – who started programming in the mid 1950s – when you used a machine with drum-based main storage, you needed to optimize your code so that just as one instruction was completing the next came under a read head to be fetched. There are even programs to do that, though of course they were VERY system-specific.
And if you want to see what servicing an early disk drive was like, even into the mid-1960s, this is worth a read:
http://bitsavers.informatik.uni-stuttgart.de/pdf/bryant/60127000B_Bryant4000_ServiceHbk_Oct66.pdf
… hydraulics and a special tool to buff the 39-inch platters.
It was random in the sense that you could read anything without a rewind (like tape). In fact, disk drivers used to have a big deal of sector skew so the controller had enough time to process and then get the “next” sector without having to have a complete spin around again. So to me, drum is still random access just like a hard drive is.
Bubble memory was used for a fairly long time. Brother used it in their tapping centers in the early 90’s for removable program storage.
I think there was a TI programmable calculator which used bubble memory for “mass storage”. I don’t recall if it was standard or an add-on, however.
I don’t remember the calculator, but I do remember their terminal that had bubble.
early cnc bubble just held a pile of instructions then can it to a 8″ floppy. Take it to lathe insert disk run . funac is Japanese for fun.
I had the TI Silent 700 portable terminal with bubble memory. It had a thermal printer like a fax machine of 1988 and 300 bps acoustic coupler. With Tymnet charging $6/hr for a connection writing code into the bubble and uploading saved a few $.
The Sharp PC-5000 used bubble memory.
The US Army MLRS used Bubble memory Electronic Unit (EU) back in the 90’s.
https://www.globalsecurity.org/military/library/policy/army/fm/6-60/Ch1.htm
Not sure what memory is used today.
Magneto restrictive delays lines were used as print buffers on Univac printers for the Univac III and others. Univac also has plated wire memory, .005″ diameter wires that lay in tunnels. Hand soldered, not many in the field got certified to do that (I did) Cabinets were oriented with consideration for magnetic north. I still have some mercury delay lines from my days fixing Univac II’s!
Static RAM is not a replacement for core as it loses its mind when power is off. Core retains its memory. Early dynamic ram (late 70’s early 80’s) was a nightmare, you needed extra ecc bits so you could correct errors on the fly.
On the core-based systems I worked on (mostly PDP-10s and PDP-11s), we rarely, rarely relied on the core memories’ persistence. Besides, there wasn’t any code to restore the machine and I/O state. Power up, reboot. I left CMU and its early Intel RAM memory fairly soon after it was installed, but I don’t think the 1 Kb memory chip failures had much impact. Then again, compared to the prototype RCA core memory we had, almost anything was better!
I have a laptop with a solid state drive. I understand that it is solid state memory configured for the computer using it to look like a conventional spinning disc drive. What if the solid state drive was made to plug in where we now plug in RAM memory sticks. If the solid state drive had a different interface where the solid state drive memory was directly interfaced on the computer’s memory bus would this be faster? Is this practical? Why do we not have this option available?
In the 90’s there were Dragon drives. An ISA card where you could stick RAM sticks in. Some emulated physical HDD’s and some ran as virtual drives for a more direct access. They had their own refresh cpu and some had battery backup. They were used in fast data logging and with a few extreme gamers.
About static rams in PCs : IBM filed a patent for an SRAM PC architecture, I don’t remember when but they have thousands of patents on very clever stuff that doesn’t make any economical sense in the hope that technology will evolve to make them richer.
Your SSD is essentially the same type of memory as is found in a common SD card.
No. It wouldn’t be faster. Access time for main DRAM is much shorter then access time for Flash (underlying SSD memory technology), and the two act very different when it comes to writing data into them. While read and write cycles are approximately the same duration with RAMs, Flash write needs a relatively long period of inactivity (orders of magnitude longer then read access time) before the data is saved.
Also, Flash memory wears out when its content changes, so even if write access time was on par of RAM write access time, it would wear out in matter of days.
As for practicality, the CPU has its defined address bus width which allows it to access certain address space. Previously, while most CPUs had 32 bit wide address bus, they couldn’t conceptualize address space greater then 4GB, and we had greater storage capacities. Nowadays CPUs with 64 byte wide address bus could easily map even 16EB (16M TB) in their address space, so perhaps it seems as reasonable idea to map mass storage as memory today, but we had this illusion before. Therefore, I’d rather that we keep the two (mostly) apart. In general, it is good thing to keep technologies as much decoupled as possible (so that one can survive change of another), but unified by an layer of abstraction.
Why don’t we have this option? Well, I can only guess, and I suppose that perhaps SSD memory sticks wouldn’t play nice with DRAMs sharing the same memory bus. OTOH I see no reason why Flash chips couldn’t be made with their external interface mimicking DRAM interface, allowing fast access to their internal RAM page buffer. But then again, that would mean that you are deliberately giving up on at least one of your precious few main memory slots on your computer’s main board, and how many users would do that?
Some HP LaserJet (the 4 series and later) use a common bus for DRAM and ROM modules. If you want PostScript or some other specialized software you must give up one of the DRAM slots, thus reducing the maximum amount of DRAM possible.
But in certain models the PostScript ROM module also included some DRAM, but not as much as the maximum size DRAM module so the only way to have maximum memory in the printer was to not add PostScript and just use the built in PCL.
HP also made at least one model of inkjet with expandable DRAM and optional PostScript. It could also have a module plugged in for LocalTalk (for Macintosh networking) and it had a coiled nichrome wire heater under the paper output so prints would dry instantly. Quite the nifty piece of hardware, too bad it was only 300 DPI. Unlike the LaserJet printers, this inkjet used ordinary 72 pin FPM SIMMs. I had mine maxed out with a PostScript module and some 30 to 72 pin SIMM stackers.
Thank you, I have been wondering about this for a long time, this was the insight I was looking for.
“OTOH I see no reason why Flash chips couldn’t be made with their external interface mimicking DRAM interface, allowing fast access to their internal RAM page buffer.”
I see a reason. DDR interfaces don’t have enough address space. DIMMs typically have something like A[14:0], BA[2:0], and CS0/CS1, giving 32 Gi addresses, or, with a 64-bit interface, 256 GiB total. While you’ve got enough address space to map the internal page buffer, you wouldn’t have enough space to map the entire drive, which means you’d have to have some other (external) mechanism for paging that space.
There are Flash DIMMs from SanDisk and Diablo Technologies. They can look like a block device with a higher bandwidth interface than an SSD or like slow memory. The current state of the art doesn’t allow them to be persistent memory. They wipe clean on system reboot.
Intel and Micron’s 3D Xpoint promises 100 or more times DRAM density at 1/10-1/00th DRAM speed making a non-volitile memory tier for in memory databases like SAP HANA very interesting.
Memristor technology promises to have the access times of RAM and non-volatility, but we have yet to see any practical devices, although some low-density, low-availability, high-price devices are now available.
As to why we don’t have flash directly mapped to main memory, there’s been attempts to do just that. Flash memory and RAM can co-exist on the same bus at the same time just fine–it’s frequently done in embedded CPUs, for instance. It’s not done in general-purpose PCs because flash memory doesn’t have the same access times as you noted. I believe the read speed of flash memory technology can rival standard RAM, but the write speed is many orders of magnitude slower. The memory bus would stall badly writing to flash.
Attaching mass storage flash memory directly to the main memory space also causes problems like the number of parallel address signals to directly address a typical 1TB or more of storage gets unwieldy. Adding more storage requires more address signals. If you resort to a serial signaling scheme to reduce the number of wires why not just use SATA, SAS or NVMe?
Even if a technology (like memoristors) become available with the access times of RAM and non-volatility, I think it’ll remain a situation in general-purpose PCs where a smaller directly-addressable main memory is connected by a higher-speed bus and much larger mass storage is indirectly accessed via a slower “external” bus (which today can be the pretty speedy PCIe bus in the case of NVMe.)
Do you mean like this?
http://www.extremetech.com/computing/193983-sandisks-dimm-based-ssd-benchmarked-and-its-a-monster-in-some-tasks
You have something similar happening – flash storage on PCIe rather than using a traditional hard drive interface like SATA. Here’s an example:
http://hothardware.com/news/seagate-debuts-10gbps-nvme-ssd
The DRAM/DIMM interface is a bit too specialized to DRAM to make sense for flash drives, but PCIe makes a ton of sense as a fast access path.
A for a related question: if you’re wondering why you can’t use your SSD directly as RAM – effectively you can, since your OS will swap to the SSD when it runs out of RAM. Because SSDs have the best performance when writing large blocks at a time, swapping to SSD makes far more sense than accessing them directly for RAM operations.
It might be worth noting that even an arcade game manufacturer, Konami, tried their hand at using bubble memory back in the mid 80’s. The idea was that you could buy a “Bubble System” base board, then buy a cartridge for whatever game on that platform you wanted to run in your arcade. This wasn’t a terrible idea, as the Capcom Play System 1 and 2 arcade systems, where the cartridges were simply PCBs with tens of mask ROMs or EPROMs in a large plastic enclosure about a foot square.
However, the reliability of bubble memory, in particular, was notoriously bad when it cames to Konami’s Bubble System hardware, and they ended up releasing at most a game or two (one of which was Gradius) before deep-sixing the hardware and porting the games over to use standard ROM boards instead. Among other issues, the bubble memory part of the cartridge had to have an embedded heater (note: heater, not heat sink!) and fan in order to keep it at just the right temperature. Not only that, the game itself took literally minutes to boot up, compared to the few seconds most arcade games take to POST. Good riddance to bad tech.
In 1988 there was a shortage of DRAM due to a fire at a factory in Asia. RAM prices soared at a time I needed extended memory for a PC project. It cost $880 for 8 megabytes ($110 per MB). A decade earlier we spent $1500 to add 12 kilobytes (board w/ 12 KB) to a DEC PDP 11/45 minicomputer.
I would like a simple writeup of the advances in and types of DRAM from the apple 2 to today.
What about Twisted Wire Delay Lines ? one video suggests https://www.youtube.com/watch?v=N9cUbYII5RY