
Artificial Intelligence is playing an ever increasing role in the lives of civilized nations, though most citizens probably don’t realize it. It’s now commonplace to speak with a computer when calling a business. Facebook is becoming scary accurate at recognizing faces in uploaded photos. Physical interaction with smart phones is becoming a thing of the past… with Apple’s Siri and Google Speech, it’s slowly but surely becoming easier to simply talk to your phone and tell it what to do than typing or touching an icon. Try this if you haven’t before — if you have an Android phone, say “OK Google”, followed by “Lumos”. It’s magic!
Advertisements for products we’re interested in pop up on our social media accounts as if something is reading our minds. Truth is, something is reading our minds… though it’s hard to pin down exactly what that something is. An advertisement might pop up for something that we want, even though we never realized we wanted it until we see it. This is not coincidental, but stems from an AI algorithm.
At the heart of many of these AI applications lies a process known as Deep Learning. There has been a lot of talk about Deep Learning lately, not only here on Hackaday, but all over the interwebs. And like most things related to AI, it can be a bit complicated and difficult to understand without a strong background in computer science.
If you’re familiar with my quantum theory articles, you’ll know that I like to take complicated subjects, strip away the complication the best I can and explain it in a way that anyone can understand. It is the goal of this article to apply a similar approach to this idea of Deep Learning. If neural networks make you cross-eyed and machine learning gives you nightmares, read on. You’ll see that “Deep Learning” sounds like a daunting subject, but is really just a $20 term used to describe something whose underpinnings are relatively simple.
Machine Learning
When we program a machine to perform a task, we write the instructions and the machine performs them. For example, LED on… LED off… there is no need for the machine to know the expected outcome after it has completed the instructions. There is no reason for the machine to know if the LED is on or off. It just does what you told it to do. With machine learning, this process is flipped. We tell the machine the outcome we want, and the machine ‘learns’ the instructions to get there. There are several ways to do this, but let us focus on an easy example:

If I were to ask you to make a little robot that can guide itself to a target, a simple way to do this would be to put the robot and target on an XY Cartesian plane, and then program the robot to go so many units on the X axis, and then so many units on the Y axis. This straightforward method has the robot simply carrying out instructions, without actually knowing where the target is. It works only when you know the coordinates for the starting point and target. If either changes, this approach would not work.
Machine Learning allows us to deal with changing coordinates. We tell our robot to find the target, and let it figure out, or learn, its own instructions to get there. One way to do this is have the robot find the distance to the target, and then move in a random direction. Recalculate the distance, move back to where it started and record the distance measurement. Repeating this process will give us several distance measurements after moving from a fixed coordinate. After X amount of measurements are taken, the robot will move in the direction where the distance to the target is shortest, and repeat the sequence. This will eventually allow it to reach the target. In short, the robot is simply using trial-and-error to ‘learn’ how to get to the target. See, this stuff isn’t so hard after all!
This “learning by trial-and-error” idea can be represented abstractly in something that we’ve all heard of — a neural network.
Neural Networks For Dummies
Neural networks get their name from the mass of neurons in your noggin. While the overall network is absurdly complex, the operation of a single neuron is simple. It’s a cell with several inputs and a single output, with chemical-electrical signals providing the IO. The state of the output is determined by the number of active inputs and the strength of those inputs. If there are enough active inputs, a threshold will be crossed and the output will become active. Each output of a neuron acts as the input to another neuron, creating the network.
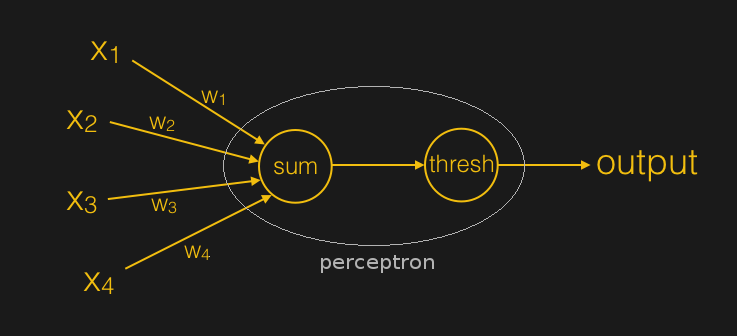
Recreating a neuron (and therefore a neural network) in silicon should also be simple. You have several inputs into a summation thingy. Add the inputs up, and if they exceed a specific threshold, output a one. Else output a zero. Bingo! While this lets us sorta mimic a neuron, it’s unfortunately not very useful. In order to make our little silicon neuron worth storing in FLASH memory, we need to make the inputs and outputs less binary… we need to give them strengths, or the more commonly known title: weights.
In the late 1940’s, a man by the name of Frank Rosenblatt invented this thing called a Perceptron. The perceptron is just like our little silicon neuron that we described in the previous paragraph, with a few exceptions. The most important of which is that the inputs have weights. With the introduction of weights and a little feedback, we gain a most interesting ability… the ability to learn.
Rewind back to our little robot that learns how to get to the target. We gave the robot an outcome, and had it write its own instructions to learn how to achieve that outcome by a trial-and-error process of random movements and distance measurements in an XY coordinate system. The idea of a perceptron is an abstraction of this process. The output of the artificial neuron is our outcome. We want the neuron to give us an expected outcome for a specific set of inputs. We achieve this by having the neuron adjust the weights of the inputs until it achieves the outcome we want.
Adjusting the weights is done by a process called back propagation, which is a form of feedback. So you have a set of inputs, a set of weights and an outcome. We calculate how far the outcome is from where we want it, and then use the difference (known as error) to adjust the weights using a mathematical concept known as gradient decent. This ‘weight adjusting’ process is often called training, but is nothing more than a trial-and-error process, just like with our little robot.
Deep Learning
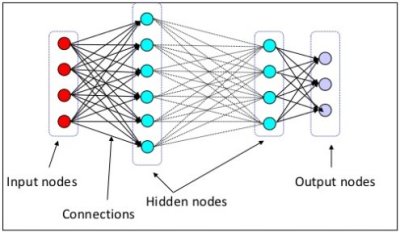
Deep Learning seems to have more definitions than IoT these days. But the simplest, most straight forward one I can find is a neural network with one or more layers between the input and output and used to solve complex problems. Basically, Deep Learning is just a complex neural network used to do stuff that’s really hard for traditional computers to do.
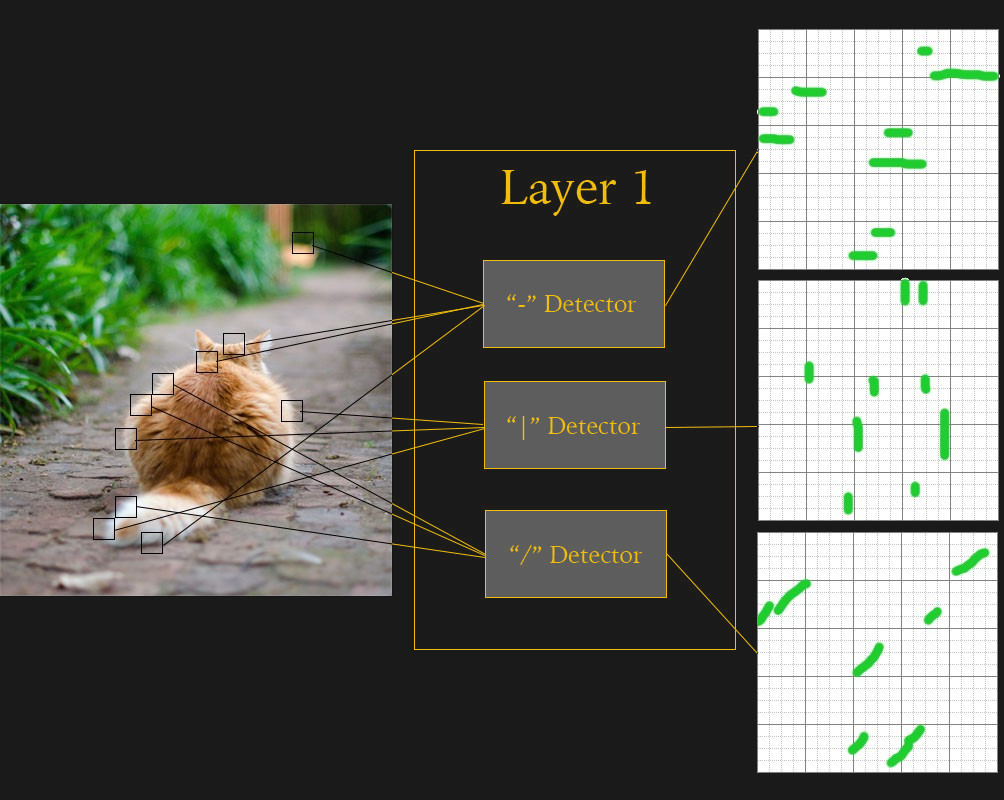
The layers in between the input and output are called hidden layers and dramatically increase the complexity of the neural net. Each layer has a specific purpose, and are arranged in a hierarchy. For instance, if we had a Deep Learning neural net trained to identify a cat in an image, the first layer might look for specific line segments and arcs. Other layers higher in the hierarchy will look at the output of the first layer and try to identify more complex shapes, like circles or triangles. Even higher layers will look for objects, like eyes or whiskers. For a more detailed explanation of hierarchical classification techniques, be sure to check out my articles on invariant representations.
The actual output of a layer is not known exactly because it is trained via a trial-and-error process. Two identical Deep Learning neural networks trained with the same image will produce different outputs from its hidden layers. This brings up some uncomfortable issues, as MIT is finding out.
Now when you hear someone talk about machine learning, neural networks, and deep learning, you should have at least a vague idea of what it is and, more importantly, how it works. Neural Networks appear to be the next big thing, although they have been around for a long time now. Check out [Steven Dufresne’s] article on what has changed over the years, and jump into his tutorial on using TensorFlow to try your hand at machine learning.














“Neural networks get their name from the mass of neurons in your noggin. While the overall network is absurdly complex, the operation of a single neuron is simple.”
I seem to remember reading the neuron was more complicated than that.
This will be the subject of my next article!
I was about to say there are more than ONE neuron model.
Spiking neurons family do have a wide collection of individual neuron models, from the simple one-point integrate-and-fire ones to the very complex comparted ones !
In comparison to the entire network (brain), individual neurons are comparatively simple. That being said, a biological neuron is vastly more complex than a typical node (i.e., ReLU) in neural network.
This was the basis for one of my projects back in the 90’s. Instead of modeling a bunch of simple neurons I was using a PIC Microntroller for each neuron so that each could be more complex.
Correct, and recently they have been to found to orders of magnitude more complex in their behaviour than was previously thought with computation occurring within individual synapses of a single cell.
My suspicion is that a single neuron is capable of being Turing complete. Well I know that is a fact at the DNA level but that is not what I mean, I am talking about the interaction of all of it’s synapses with each other via the main cell body.
Try this if you haven’t before — if you have an Android phone, say “OK Google”, followed by “Lumos”. It’s magic!
Actually, it’s not magic, it’s creepy! As creepy as only a worst nightmare can be, because it shows how a simple search ended up running arbitrary code on your phone. Somebody else is controlling your hardware. This is no tin hat, it’s a reality check.
Sorry for the offtopic. I like the subject, also I like your in depth writings, so thank you for this kind of articles.
An application on your phone is controlling your phone. Say it isn’t so.
“it shows how a simple search ended up running arbitrary code on your phone.”
If I write an app that sends what you type in to a server, check if the result is “lumos”, and if it is, turn on the flashlight, is that a simple search running arbitrary code on your phone? It’s just code on your phone (that you can disable, by the way) that sends your voice to a server for recognition (or does it offline if you have no connection) and checks the result for a few keywords.
“Somebody else is controlling your hardware.”
That’s true whenever you run any code written by someone else on your hardware. If someone sends you an email, and the email gets displayed on your phone, is someone else controlling your hardware? Yes, they are controlling what’s displayed when you choose to view it, but they can’t do everything with your hardware (unless something goes wrong)
“Phone, turn on the flashlight”
Flashlight turns on.
“SOMEONE IS CONTROLLING MY PHONE!!!”
It’s you. You are controlling your phone. It did what you told it to.
Sorry, it looks like that phrase, “If you have an Android phone…”, was misleading. I was tricked into believing that the voice search can control the phone’s LED, but I just tried and it doesn’t. So no, if you have an Android phone and simply voice search for “Lumos”, it would not turn on the LED. Maybe if some other App is pre-installed, then it will work, but not from a clean Android and a Google voice search.
My bad, I should have test it before making the previous comment.
Dialog: Where we’re headed with Google & Privacy…
Me: “Google please stop spying on me”
Google: “We never spy on you. We help you and love you!” [Hearts-n-Kittens Emojis follow]
Me: “Google I will PAY you to stop spying on me”.
Google: “How much do you want to pay?”
Me: “Everything I own and everything I love.”
Google: “We love you too!” [more Hearts-n-Kittens Emojis follow]
Result: Spying continues, and continues, and…
You’re forgetting, all your money and possessions are mearly one’s and zeroes, like your “freedom”, they already own it.
Hmmmph! I wish my possessions were ones and zeroes. Moving day would be a lot easier.
Block all thirdparty Cookies
Only allow Java on some very very select sites
If you’re using chrome don’t bother you like your spyware malware unrestricted.
The best way to hide is to blend in, let them spy. Think radar shadow, it’s illegal not to exist.
Keep a separate, offline self.
Let’s not mention perceptrons, m-kay ? They can’t even solve an XOR relation, and they damn near killed the whole idea until McClelland, Rumelhart, and Hinton (and the PDP group) came along in the ’80s and undid the mess – for those of you concerned with being watched by giant pattern recognition systems, truth is they’re really brittle – check out ‘adversarial neural networks’ and you’ll see you can have a lot of fun driving the ad servers crazy :-)
“gradient decent”
My best impression of Google;
Did you mean “gradient descent”?