Researchers have been playing around with various oddball forms of robot locomotion; surely, we’ve seen it all, haven’t we? Not so! Lucky for us, [researchers at Stanford] are now showing us a new way for robots to literally extrude themselves from point A to point B.
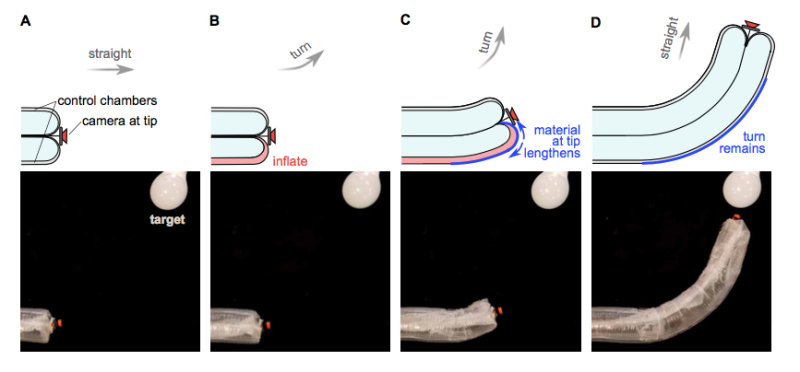
This robot’s particular motion for mechanism involves unwinding itself inside out. From a stationary base, a reel caches meters of the robot’s uninflated polyethylene body, which it deploys by pressurizing. Researchers can make full 3D turns by varying the amount of inflated air in outer control chambers. What’s more, they can place end effectors or even payloads at the tip of the growing end with their position held in place by a cable.
As we can imagine, any robot that can squeeze its way up to 72 meters long can have dozens of applications, and the folks at Stanford have explored a host of nooks and crannies of this space. Along the way, they deploy complex antenna shapes into the air, deliver small payloads, extinguish fires, and squeeze through all sorts of uninviting places such as flytraps and even a bed of nails. We’ve placed a video below the break, but have a look at Ars Technica’s full video suite to get a sense of the sheer variety of applications that they imparted upon their new creation.
Biomimetics tends to get us to cry “gecko feet” or “snake robots” without thinking too hard. But these forms of locomotion that come to mind all seem to derive from the animal kingdom. One key element of this soft robot is that its stationary base and vine-like locomotion both have its roots in the plant kingdom. It’s a testament to just how unexplored this realm may be, and that researchers and robots will continue to develop new ways of artificially “getting around” for years to come.
Thanks for the tip, [Jacob!]














I confess, I thought this was already being done. For example: http://www.dynamicdraintechnologies.com/fold-and-form-pipe-liner-vs-inversion-sewer-lining/
But I guess the newness is the ability to direct the erm… worm in free space?
Yeah, the fact that it’s actively controlled instead of merely expanding to fill a rigid volume is pretty big. That’s like comparing a BB-8 ‘droid to a soccer ball. Otherwise you could say it’s been done since those water snake toys were a thing:
https://www.google.com/search?q=water+snake+toy&source=lnms&tbm=isch&sa=X&ved=0ahUKEwjI46S719PWAhUh_IMKHeVyDGQQ_AUICygC&biw=1440&bih=799
Same principle, less control.
I’ve seen enough hentai to know where this is going
She seemed really excited about discussing how it can reach tight places — maybe a little too excited.
I am sure the faculty sees endless practical applications, and is proud of their work.
Cool idea however now I want to see them retract the thing.
Deflate it and reel it in, in reverse?
Pull the internal cable back as you remove air from the tube?
Yep, that’s what I thought also until I realised the forces involved in doing this would require equal force to the “draw string” puling it back as there was air pressure in the thing. as you release the air volume you would need to be able to retract it in to itself and maintain the pressure for the rest of the inflated area, even more if the thing has been used to move/lift an object.
However saying that, I have had to run really long cables lengths in roof cavities where there is not enough space to crawl. Have in the past even resorted to using small RC cars to pull a lure through first then used that to pull the cable bundle. Something like this would be awesome and even better you could traverse corners. Being an inexpensive plastic it could even be designed as a use once thing.
First plant-inspired bot that looks to work well.
cool concept.
But to call it a robot… if washing machines would not exist and would be invented in this current time and age then I’m sure it would be called a washing robot. Everything is called a robot these days, stop doing that! This thing is no more a robot then a standard RC-card (just like the robots in robot wars…) ahh… never mind.
Though the concept is cool and very promising. One aspect is that its main part (the “balloon”) can be cheaply made and therefore be disposable while keeping the expensive parts close to the operator (and therefore safe to be used over and over again).
Ummmm …..
http://blog.modernmechanix.com/mags/ModernMechanix/8-1935/motorless_washer.jpg
haha… did not see that one coming!
I knew that Chevy stood for the cheapest that GM put out, but this washer wins. Makes a automatic seem robotic. Now what to do with sopping wet laundry, no wringer? Got bucket!
http://www.qwantz.com/comics/comic2-1317.png
Don’t be so down on his breadmaker Utahraptor, do you expect him to knead dough with those arms???
Can someone point out the control action at a specific time in the video? I only see the unrolling action, not any additional directional control. Thanks.
1:13-1:25
2:15
2:25
Yes, it’s unrolling, but unrolling in a specific new direction.
Worm for sure, but they use hydro pressure not air to tunnel. Might work here too.
I think they got the idea from this toy:
https://www.google.dk/search?biw=1600&bih=790&tbm=isch&sa=1&q=water+filled+tube++toy&oq=water+filled+tube++toy&gs_l=psy-ab.3..0i19k1j0i8i30i19k1.22729.29460.0.29679.18.16.0.0.0.0.540.2752.0j2j2j3j1j1.9.0.dummy_maps_web_fallback…0…1.1.64.psy-ab..11.7.1927…0j0i7i30k1j0i7i30i19k1j0i8i7i30k1j0i8i7i30i19k1.0.Sk7eF_bQx50
I’ve seen enough hentai etc. etc.
I think it needs to be pulling a cable. It can not work without a cable? The cable’s tension maintains each bend?
I love this kind of thing. It’s so satisfying to see excellent engineering take the form of nature accidentally. What a marvel.
I’d love to see something like this using incompressible hydraulics in a kevlar sleeve or something like that. I imagine it could do a lot of heavy lifting. Or would that even work? Does it depend on compressibility of the working fluid?
Compressibility has little to do with it – 100psi air will lift the same amount as 100psi oil. You just have to pump more volume of air to get it up to 100psi. You can see in some spots in the video that they are using it to lift containers, etc. so that definitely seems to be a feature.
how to turn somebody can tell me?