
While the whole industry is scrambling on Spectre, Meltdown focused most of the spotlight on Intel and there is no shortage of outrage in Internet comments. Like many great discoveries, this one is obvious with the power of hindsight. So much so that the spectrum of reactions have spanned an extreme range. From “It’s so obvious, Intel engineers must be idiots” to “It’s so obvious, Intel engineers must have known! They kept it from us in a conspiracy with the NSA!”
We won’t try to sway those who choose to believe in a conspiracy that’s simultaneously secret and obvious to everyone. However, as evidence of non-obviousness, some very smart people got remarkably close to the Meltdown effect last summer, without getting it all the way. [Trammel Hudson] did some digging and found a paper from the early 1990s (PDF) that warns of the dangers of fetching info into the cache that might cross priviledge boundaries, but it wasn’t weaponized until recently. In short, these are old vulnerabilities, but exploiting them was hard enough that it took twenty years to do it.
Building a new CPU is the work of a large team over several years. But they weren’t all working on the same thing for all that time. Any single feature would have been the work of a small team of engineers over a period of months. During development they fixed many problems we’ll never see. But at the end of the day, they are only human. They can be 99.9% perfect and that won’t be good enough, because once hardware is released into the world: it is open season on that 0.1% the team missed.
The odds are stacked in the attacker’s favor. The team on defense has a handful of people working a few months to protect against all known and yet-to-be discovered attacks. It is a tough match against the attackers coming afterwards: there are a lot more of them, they’re continually refining the state of the art, they have twenty years to work on a problem if they need to, and they only need to find a single flaw to win. In that light, exploits like Spectre and Meltdown will probably always be with us.
Let’s look at some factors that paved the way to Intel’s current embarrassing situation.
In Intel’s x86 lineage of processors, the Pentium Pro in 1995 was first to perform speculative execution. It was the high-end offering for demanding roles like multi-user servers, so it had to keep low-privilege users’ applications from running wild. But the design only accounted for direct methods of access. The general concept of side-channel attacks were well-established by that time in the analog world but it hadn’t yet been proven applicable to the digital world. For instance, one of the groundbreaking papers in side-channel attacks, pulling encryption keys out of certain cryptography algorithm implementations, was not published until a year after the Pentium Pro came to market.
Computer security was a very different and a far smaller field in the 1990s. For one, Internet Explorer 6, the subject of many hard lessons in security, was not released until 2001. The growth of our global interconnected network would expand opportunities and fuel a tremendous growth in security research on offense and defense, but that was still years away. And in the early 1990s, software security was in such a horrible state that only a few researchers were looking into hardware.
The Need for Speed
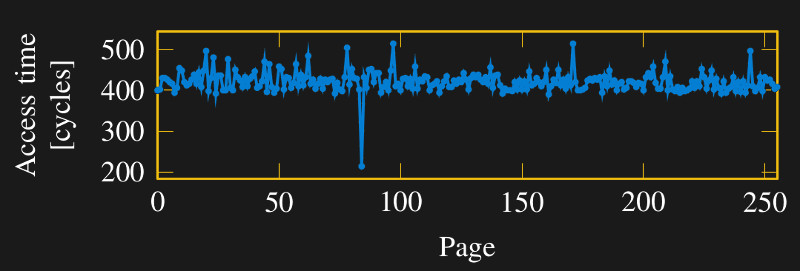
During this time when more people were looking harder at more things, Intel’s never-ending quest for speed inadvertently made the vulnerability easier to exploit. Historically CPU performance advancements have outpaced those for memory, and their growing disparity was a drag on overall system performance. CPU memory caches were designed to help climb this “memory wall”, termed in a 1994 ACM paper. One Pentium Pro performance boost came from moving its L2 cache from the motherboard to its chip package. Later processors added a third level of cache, and eventually Intel integrated everything into a single piece of silicon. Each of these advances made cache access faster, but that also increased the time difference between reading cached and uncached data. On modern processors, this difference stands out clearly against the background noise, illustrated in this paper on Meltdown.
Flash-forward to today: timing attacks against cache memory have become very popular. Last year all the stars aligned as multiple teams independently examined how to employ the techniques against speculative execution. The acknowledgements credited Jann Horn of Google Project Zero as the first to notify Intel of Meltdown in June 2017, triggering investigation into how to handle a problem whose seeds were planted over twenty years ago.
This episode will be remembered as a milestone in computer security. It is a painful lesson with repercussions that will continue reverberating for some time. We have every right to hold industry-dominant Intel to high standards and put them under spotlight. We expect mitigation and fixes. The fundamental mismatch of fast processors that use slow memory will persist, so CPU design will evolve in response to these findings, and the state of the art will move forward. Both in how to find problems and how to respond to them, because there are certainly more flaws awaiting discovery.
So we can’t stop you if you want to keep calling Intel engineers idiots. But we think that the moral of this story is that there will always be exploits like these because attack is much easier than defense. The Intel engineers probably made what they thought was a reasonable security-versus-speed tradeoff back in the day. And given the state of play in 1995 and the fact that it took twenty years and some very clever hacking to weaponize this design flaw, we’d say they were probably right. Of course, now that the cat is out of the bag, it’s going to take even more cleverness to fix it up.














Any thoughts on MRAM and that “memory wall”?
Are you asking about to Magnetoresistive RAM? It’s usually slower than DRAM used as system memory and much much slower than the SRAM usually used for cache.
There are some processors with eDRAM and 1T-SRAM that land somewhere in between DRAM and SRAM, in speed, density, and cost.
The solution is rather simple, check security clearance first, then fetch the data. Since, if an application wants access to something it isn’t allowed to read or write to, then it will get nothing in return or just ignored.
Speculative execution is in itself not really a problem, it is more the lack of security checks that is the problem.
Specter in general is something that I personally can’t understand how developers manages to get their systems vulnerable too in the first place, since the specter exploit seems to work on a whole slew of different manufacturers hardware. Are developers really that bad at implementing security? Or is it just me thinking too much about it.
By developers, do you mean software developers? Spectre is a cache side-channel attack just like Meltdown — it’s mostly a hardware problem. The difference is that it’s much, much more practical to implement, and more dangerous because it’s practical for attacks such as bypassing browser sandboxing. For example, the paper gives an (incomplete) Javascript example which produces the necessary instructions to produce the mispredict.
I were talking about the hardware developers. Since it is a hardware related problem.
Everything is 20/20 in hindsight.
security is harder than you seem to think.
Security is easy, the willingness to spend the money necessary to implement good security is the problem. Anyone with good computer design skills along with very strong software skills can design a very secure system. It also requires a good system engineer that can specify the requirements for a secure system. How many people have strong electronic design skills along with strong software skills and system engineering skills. There are a few of us out there. You need all three skill sets preferably in one person though.
You have no idea what you’re talking about do you
Well that sounds like Monday morning quarterbacking. I could easily see how such an oversight could be made. Back in the Pentium Pro days someone could have asked, “Shouldn’t we go through the access checks on the speculative branch?” The answer would have been, “Why bother? It makes any processing more complicated and any value read will only be in the cache and can’t be reached by the user code unless the branch is taken where the security will then be checked. Otherwise the cached value will just be thrown away.” It would take a much bigger leap, in my mind at least, to then think that someone could use the timing of a future, invalid access to determine the contents.
See, someone saw what I aimed for! Since the actual problem is really simple.
And if one wants to really make sure to not give out any data, then one can keep a constant 1000 cycle response time for all unauthorized data access attempts and the respons will be “empty” as in just zeros or something, since then we are not even giving out any information regarding where the data even were to begin with. Unless the RAM is placed many meters away from the CPU…
So the excuse that is given is that the additional check would add an overhead. That is true but I can’t imagine it being significant given how complicated the MMU already is in an x86 and in the modern ARMs. It would add some complexity, i.e. transistor overhead but AFAIK not much time overhead.
You’ll want to know that a memory lookup is complicated enough that an MMU has it’s own cache of memory translation results called the TLB. It doesn’t cache any actual data from that memory, only the virtual to physical address mappings needed to get actual data from memory. The TLB is flushed on a context-switch though.
Given that the speculative execution logic already needs to talk to the MMU and get the TLBs involved and then possibly multiple page table level lookups for each memory access I can’t see a permission bits check or a process ID check as costly. Maybe there’s more to it?
Nope it’s not a data access security thing, it’s an improper architectural state management.
When doing speculative execution, you maintain a parallel and shadowed execution environment that you may use or toss depending on speculation result. The issue is that all environement is not properly shadowed: cache loads are not.
So the real fix is to properly shadow and manage cache loads into the speculative environment. This way you won’t leak information once speculation is over.
https://en.wikipedia.org/wiki/Hanlon%27s_razor
Calm the F&#$K down, As it stands now, this attack vector is only potentially viable with access to the machine or irresponsible online behavior. The browser attack vector is a one in a billion moonshot and all other cases present a dozen easier methods for exploitation.
The landscape for this exploit to be even remotely worth somebodies while will be soon mitigated, if it existed at all.
Let the silicon farmers and OS bakers worry about it. It will be fine.
Some of us are farmers and bakers…. :)
It is an interesting attack vector and there are many lessons in it.
Each new change in HW brings about new challenges. Understanding the old ones helps avoid repeating them.
“Let the silicon farmers and OS bakers worry about it”
No. This exact mindset is why the vulnerability is so bad, because nobody gave a flying f*** about it and so it goes back so far, despite the warnings apparently being there when speculative execution was brought to the market.
IME is the same problem factory, every competent computer security engineer had at least doubts about it being safe and now more and more workable attack vectors are being discovered.
Without the proper motivation, bugs get fixed slowly or not at all, if this craze gets it them to find a solution that doesn’t cripple computing power, so be it…fix yo’ shit Intel! :P
Look, every layer of the IT disciplines have had their hand in the creation of unsafe, unstable products that were developed to fast due to unreasonable market pressures. It isn’t purely Intels fault, it kinda is all our fault, but it makes no sense in starting a panic over something that is only, at best, an academic curiosity for as long as it lasts.
As a historian, I understand the concept of learning from past mistakes, but the key is to implement what you learned correctly. In this case we should accept that users and software developers should not be as much a factor in driving hardware development.
“we should accept that users and software developers should not be as much a factor in driving hardware development”
At that point I read your comment once more and reviewed the article to see what I missed. Respectfully I’m still missing what point you where trying to make. Most who develop hardware to make a profit from sales. That make software developers that add value to your hardware and the users that will purchase your hardware very important factors. Having said that I don’t envy the dilemma presented to hardware manufactures, but until it costs them (and customers) big time they neither will be motivated to spend what security costs.
I tend to agree. The important thing to realise is that all these attacks depend on being able to measure the time taken for certain operation sequences with a good degree of accuracy. If accurate high resolution timers are unavailable these attacks become pretty impractical
It’s reasonably easy to ensure that in environments like JavaScript there are no accurate high resolution time sources. I believe that one of the fixes implemented in Internet Explorer to render attacks using JavaScript code impractical is to make the time function have a resolution of 20ms with jitter of 20ms. The picture may change if you can execute arbitrary machine code because it may be able to access timers that can be used in the attacks.
Whether this is possible depends on the processor and system architecture.
In some cases there’s non-privileged access to suitable timers. For example, in the essentially obsolete Digital/Compaq Alpha processors the architecture includes a processor cycle counter that is readable with a non-privileged instruction. That makes attacks based on timing relatively easy to implement if you can execute appropriate code. The ARM architecture includes no counter of this sort but that does not means that a system containing an ARM processor does not contain a suitable timer. On the other hand many Intel x86 processors have several counters (generally multiple performance counters and also the time stamp counter) but access to all of them can be restricted to privilege level 0 by setting appropriate bits in CR4.
This reads like:
‘We were paid by Intel to release the following statement’
Micro architectural attacks go back a lot longer than the article suggests.
https://www.peerlyst.com/posts/a-collection-of-links-to-pdfs-of-papers-on-micro-architectural-side-channel-attacks-sorted-by-date-paul-harvey
Maybe time for Intel to hire some hackers…
“here- break this.”
I remember asking about this relative to IBM architecture before this timeframe. But also remember that back then, Bill Gates made the implausible statement that no one cared about security. Personally, I think that was the mindset then. From things like SMTP that are ridiculously insecure, to TCP/IP itself, people were way more worried about getting the problems to fit on the hardware at all, to worry about securing them. The overhead of security is more or less trivial today…just as allocating 4 positions for a year is. But a lot of this stuff was conceived ball when memory was copper wires hands threaded through ferrite chores, and when computers had 1 meg hard drives.
I don’t think meltdown is an NSA plot…. The Intel ME, however, running a crappy version of Minix… yeah that’s a damned NSA plot.
This! Why pick the lock when you have this huge gaping hole right next to the door?
This reminds me of C.A.R. Hoare’s observation
“There are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies, and the other way is to make it so complicated that there are no obvious deficiencies. The first method is far more difficult.”
While he was talking about software, same sort of principle can be applied to hardware. Unfortunately, personal computers have been moving more toward complexity which obscures deficiencies.
A pity nobody makes SRAM in the capacities we’d need to replace DRAM… ;) SRAM is faster and better, if a bit bulkier and (at present) more expensive — but I’m sure there are ways to fix that if someone (or several someones on a team) put/s their mind/s to it…
Ah’m just a’sayin’…
The big problem with SRAM is that it needs 4 times as many transistors per bit compared to DRAM. Therefor it will always have 1/4 the density, and about 4 times the manufacturing cost. At least if we take a back of the envelope look at it.
Now one can probably change this by having multi channel FETs and stuff, but that can (and probably is) be used in DRAM as well…
Not to mention that DRAM is nothing more then an analog switch (1 Field effect transistor), connecting a capacitor to a comparator. We could easily add another comparator and suddenly have the ability to store three states instead of just two. (Downside is that leakage would require us to refresh the cell more often.)
So if anything, DRAM has many more tricks up its sleeve. While SRAM is rather boring with its array of D-latches.
Positive thing with SRAM is still the access speed.
And technically, we could just add a large (tens of MB is plenty) SRAM close to the CPU having all of the kernel in it, and effectively make its access time near nothing. “Quick and simple fix.” Or not, since the whole memory management system, and Kernel would need to be redesigned. And while we changed the prior, we will probably fix the problem with authorization checking too.
For most people using home and office computers, Meltdown and Spectre would have little or no effect unless they downloaded and ran malware…
…EXCEPT for this: these vulnerabilities can be targeted by Javascript in web-browsers! You’re at risk just by browsing!
http://fortune.com/2018/01/05/spectre-safari-chrome-firefox-internet-explorer/
THAT is just F#CKED UP.
Never mind ragging on Intel or AMD engineers. Why on Earth would Javascript running in a web browser need access to microsecond or cycle-level timing, which this exploit requires? Those are the engineers who need a smack.
As far as I understand it, one use of precise timing in JS is code optimization!
That can save a lot of time and energy on a big enough scale (think google / facebook).
Optimization is a valid reason.
A solution to have both the optimization tools, and the security would be by having the feature of even running that type of command in the script as a default be off, as in it should be ignored. Or have the command always put out a fixed value, like zero.
This though doesn’t stop someone from implementing their own counter, and through that do their own timing.
This here is actually a curious thing, why do we run Javascript in web browsers even close to the needed speed to do such?
Answer is simple, and that is performance. People wish to do X amount of stuff in preferably as little time as possible. But I guess the fix most web browser developers will roll out involves either interleaving the execution of scripts, or just forcing them to run slower.
The interleaving method is similar to multi threading in modern processors, and could possibly be opening another can of worms by introducing methods of going around the solution…
The other method of just running it slower is simpler.
Though, I do wonder, if we were to under clock the CPU to like 1 GHz or so, would it take more time to execute this attack compared to a standard clocked system or an overclocked system? (Something makes me feel overclocking makes it easier, since it would be easier to tell the difference between cache and RAM from a timing standpoint.)
My point isn’t about allowing Javascript to run as fast as possible, it’s about allowing the Javascript on any webpage to access or derive such detailed data about the execution speed of the processor, or any other such operation that exposes info about the user’s computer. A web page is a human interface; you don’t need any explicit timing functions in code that are more precise than maybe half a millisecond? I can’t think of a reason, anyway.
Sure optimization is important, and developers should be using a browser with a development plug-in or similar to monitor and analyze execution. The other 99.99% of people using web browsers don’t need that.
I suppose a determined hacker could use even crude timing to measure small amounts by timing how long it would take to execute X iterations then divide by X…
> Why on Earth would Javascript running in a web browser need access to microsecond or cycle-level timing, which this exploit requires?
OK – so the browser removes javascript access to the high-resolution timer. User just creates their own good-enough-facsimile of a high-resolution timer using javascript and a busy-spin-loop.
I suppose… but even that would be a bit harder to do, and if other processes steal an unknown amount of cycles while that ersatz timer is running, the precision might not be good enough for the exploit. I’m a bit over my head at this point – not a kernel guy.
The big thing here is that the exploit isn’t about someone getting through with their first attempt, since as you point out, another thread can be switched in and make the whole attempt to exploit the system meaningless. But if one tries to do the exploit a million times, then it is a different playing field.
even if you cripple the timer APIs it won’t change anything, just return to the boggomips method.
Or you can use a thread scheduler with fixed time allocation (~ms) and have sluggish browser.
From what I’m hearing here, the Intel engineers knew this was a problem with the x86 processors but felt that the risk was very low because the technology to weaponize the bug was out of reach. Fine. But as they pushed performance forward with new processors and technology advanced, why weren’t they working on a fix, at least over the last 10 years or so? Someone on the product management side should have been tracking this.
This is the million dollar question (probably literally, maybe billions if there’s a class lawsuit from server farms). I think the likely answer is that they forgot that they had a ticking time bomb in the silicon. 20 years? Institutional memory? Totally plausible.
If you eliminate computers with complex softwares and put something in the path that has only one (or a small number) of ways in and ways out – then there can be no back doors. A micro controller controlling access is probably better than using a computer or microprocessor. This is the basis of a new firewall I am designing.
Scott Holland
We’re paying for architectural decisions that were made when security was “put the box in a room and lock the door to keep attackers away”.
Yes, I have worked on classified systems like that. Of course, classified processing migrated to the internet with encryption protecting the data. Encryption is not always enough. Guess what – the NSA (probably actually Congress and a Presidential signature limits encryption in this country such that you risk doing something illegal if you use a sytem that uses (today) more than 256 bits of encryption using DES. The reason for 256 bits? You guessed it, NSA can probably break DES with 256 bits.
The answer is non backwards compatibility. Start over.
Intel engineers are not idiots, although quite of few internal practices of Intel are retarded. Intel was basically “cheating” with Meltdown so as to not have to do expensive buffer clears and thats that, its the Volkswagen diesel equivalent of the chip industry. Spectre appears a distraction as the whole chip industry is, unlike Meltdown, doing it, so as to take the heat off of Meltdown. Hopefully passwords are encrypted in memory anyway, but what about keyloggers, there should be some kind of keyboard hardware encryption as well, no? We can’t do everything by mouse or finger. Moving on to software, mozilla is also very much sloppy (or sneaky, we may never know which), but then again we probably need to have a much deeper and closer look at two endlessly problematic programming languages security wise — C and Javascript. Oh why not add in Java and flash while we are at it? Hardware bugs may spook like nothing else, but software can harm just as well as any hardware bug.