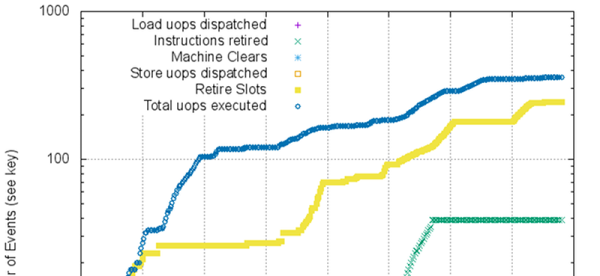
NVMe solid state disk drives have become inexpensive unless you want the very largest sizes. But how do you get the most out of one? There are two basic strategies: you can use the drive as a fast drive for things you use a lot, or you can use it to cache a slower drive.
Each method has advantages and disadvantages. If you have an existing system, moving high-traffic directories over to SSD requires a bind mount or, at least, a symbolic link. If your main filesystem uses RAID, for example, then those files are no longer protected.
Caching sounds good, in theory, but there are at least two issues. You generally have to choose whether your cache “writes through”, which means that writes will be slow because you have to write to the cache and the underlying disk each time, or whether you will “write back”, allowing the cache to flush to disk occasionally. The problem is, if the system crashes or the cache fails between writes, you will lose data.
Compromise
For some time, I’ve adopted a hybrid approach. I have an LVM cache for most of my SSD that hides the terrible performance of my root drive’s RAID array. However, I have some selected high-traffic, low-importance files in specific SSD directories that I either bind-mount or symlink into the main directory tree. In addition, I have as much as I can in tmpfs, a RAM drive, so things like /tmp don’t hit the disks at all.
There are plenty of ways to get SSD caching on Linux, and I won’t explain any particular one. I’ve used several, but I’ve wound up on the LVM caching because it requires the least odd stuff and seems to work well enough.
This arrangement worked just fine and gives you the best of both worlds. Things like /var/log and /var/spool are super fast and don’t bog down the main disk. Yet the main disk is secure and much faster thanks to the cache setup. That’s been going on for a number of years until recently.