
Have you heard it said that everything in Linux is a file? That is largely true, and that’s why the ability to manipulate files is crucial to mastering Linux Fu.
One thing that makes a Linux filesystem so versatile is the ability for a file to be many places at once. It boils down to keeping the file in one place but using it in another. This is handy to keep disk access snappy, to modify a running system, or merely to keep things organized in a way that suits your needs.
There are several key features that lend to this versatility: links, bind mounts, and user space file systems immediately come to mind. Let’s take a look at how these work and how you’ll often see them used.
Links
 There are two kinds of links: hard and soft (or symbolic). Hard links only work on a single file system (that is, a single disk drive) and essentially makes an alias for an existing file:
There are two kinds of links: hard and soft (or symbolic). Hard links only work on a single file system (that is, a single disk drive) and essentially makes an alias for an existing file:
ln /home/hackaday/foo /tmp/bar
If you issue this command, the file in /home/hackaday/foo (the original file) and the file /tmp/bar will be identical. Not copies. If you change one, the other will change too. That makes sense because there is only one copy of the data. You simply have two identical directory entries. Note the order of the arguments is just like a copy command. the File foo is the original file and the new link you’re creating is called bar.
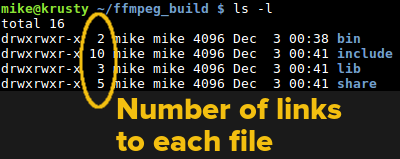 These are not super useful because they do require the files to be on the same file system. They can also be hard to maintain since it is not always obvious what’s going on internally. Using the -l option (that’s a lower case ‘L’) on an ls command shows the number of links to a particular file. Usually, this is one, although directories will have more because each .. reference from a subdirectory will count as a link as well as the actual entry (.) and the entry in the parent directory. If you want to find all the hard links that are the same, you’ll need to search the file system (use find and check out the -samefile option).
These are not super useful because they do require the files to be on the same file system. They can also be hard to maintain since it is not always obvious what’s going on internally. Using the -l option (that’s a lower case ‘L’) on an ls command shows the number of links to a particular file. Usually, this is one, although directories will have more because each .. reference from a subdirectory will count as a link as well as the actual entry (.) and the entry in the parent directory. If you want to find all the hard links that are the same, you’ll need to search the file system (use find and check out the -samefile option).
Symbolic links are much more useful since they can span file systems. Essentially, a symbolic link or symlink is just a file that contains the name of another file. The file system knows that when you work with that file, you really mean the referenced file. The command to create is the same, with a single option added:
ln -s /home/hackaday/foo /tmp/bar
A complete directory list shows symbolic links very clearly. There are a few things you have to watch for. First, you can create circular links even though the tools try to detect that and prevent it. In other words, fileA might refer to fileB which refers to fileC that refers back to fileA. Linux will eventually stop after a certain number of indirections to prevent this from taking out the computer.
Another issue is that the target file might not exist. This could happen, for example, when you delete the original file. Finding all the symlinks requires a search of the file system, just like hard links, so it is not easy to find these broken links.
What is it good for? Imagine you have a working directory for a PCB router. There is a temporary directory in that working directory called scratch. You notice that disk I/O to the scratch directory is eating up most of the execution time of the program. You could use a symlink to easily point the scratch directory to a RAM disk or a solid state disk drive to improve performance.

Bind Mounts
Many Linux file systems support the idea of bind mounting. This lets you mount a directory somewhere else on the file system. This is similar to doing a symlink to a directory, but the specifics are a little different. For one thing, the mount is transient whereas a symlink is as permanent as the file system it resides in. For another, a mount point can replace an existing directory without destroying it (including becoming a new root directory with the chroot command).
In fact, chroot is probably the most frequent use of bind mounts. You want to prepare a new root directory for a system — possibly a remote system — and you are still booted on the old root. An easy way to fake things is to bind mount “special” file systems like /dev and /proc into the new root and then chroot to run things like grub.
For Linux, you normally create a bind mount using the mount command:
mount -o bind /dev /home/hackaday/bootimage/dev
This command replicates /dev into the bootimage directory.
BSD offers a nullfs that can accomplish the same thing. There’s also a user file system called bindfs that does a similar task.
In addition to building fake root file systems, you can also use a bind mount to reveal directories that are hidden behind a regular mount. For example, suppose you wanted to create a RAM drive for your /tmp directory:
mount -t tmpfs -o size=512M tmpfs /tmp
Anything that had been in /tmp is now hidden. However, consider this command:
mount -o bind /tmp /oldtmp
Now /oldtmp will have the contents of /tmp before the RAM drive mount.
If you want a refresher on mounting in general, check out the video below. It talks about regular mounts and loop mounts (used to mount a file — like an ISO file — instead of a device).
https://www.youtube.com/watch?v=A8ITr5ZpzvA
User Space File Systems
Historically, adding a file system meant writing kernel code (usually a kernel module). However, using Filesystem in User Space — known as FUSE — anyone can write code that looks like a file system. In fact, if you want to build a sandbox without directly using bind mounts, check out sandboxfs.
There are lots of user file systems to handle a variety of tasks. Some do special things with files like mounting an archive as a directory. Others expose other kinds of data as files (for example, blog posts on a remote web site). There are file systems that can tag real files, convert file types on the fly, or even delete old files when space runs out. I find sshfs particularly useful since it can mount a remote directory with no special software on the remote side.
Writing your own FUSE module is fairly simple. There are several good tutorials out there. If you use C++, you can get away with a pretty simple implementation. If you are interested in seeing how it would work using Python, check out the video below.
Wrap Up
In traditional Unix-based systems, everything was a file. For better or worse, that philosophy isn’t as pervasive as it used to be. Still, files and file-like things continue to be a big part of Linux and knowing how to manipulate links, mount directories, and use FUSE file systems can be a big help in administering and setting up any Linux-based system from a PC to a Raspberry Pi.














>”One thing that makes a Linux filesystem so versatile is the ability for a file to be many places at once.”
That’s one of the things that makes a Linux filesystem less versatile, because it becomes ambigous where anything really is. Programs can’t find their own files without hardcoded paths, your file browser doesn’t really know how much space there is available or how much space your files take, and if you do run out of space then all hell breaks loose.
A simple question of, “Oh, I ran out of space on HD1, I’ll install this new software on my new HD2” becomes a hair-pulling exercise of magnificent proportions with a high probability of bricking your entire OS.
What do you mean you don’t know where the file really is?
If it’s hard linked, then you use find and –samefile as stated, if it’s a symlink, then it shows you where it’s linked to, and you can delete it.
> Programs can’t find their own files without hardcoded paths, your file browser doesn’t really know how much space there is available or how much space your files take, and if you do run out of space then all hell breaks loose.
What? – If a program is running, it has a $CWD value it can use, or it can use whatever path it believes it’s own files to be on, or it can use a built in such as `which` to find out where a file is. No program natively ‘knows’ where it’s files are, no matter the O/S.
If your file system doesn’t support `df -h` – please use a proper file system.
> A simple question of, “Oh, I ran out of space on HD1, I’ll install this new software on my new HD2” becomes a hair-pulling exercise of magnificent proportions with a high probability of bricking your entire OS.
Really just trolling now, you could use mount -o bind /usr/bin/myNewProgram /dev/hdd2/myNewProgram if you wanted to make everything appear ‘neat’ and you’d install directly onto hdd2, but you didn’t want answers did you luke? ;)
>If a program is running, it has a $CWD value it can use
Which is not necessarily the path where the program actually lives, so if you want the software to find its configuration files you have to put them in known places. Hence why the filesystem hierarchy exists. As far as I know, there is no standard and reliable way for a program to find itself in Linux, like there exists in many other OS.
>”and you’d install directly onto hdd2″
As far as I understood, the process you’re describing would assume that I manually download the software package and its dependencies, find out what the software is expecting to put where, roll them out manually onto the other drive – because remember it’s not just the binaries I want to go there: I’m running out of space on the HD so if the software needs something else I’m just as hosed there. Then, having created this parallel hierarchy I painstakingly bind everything back to the filesystem on the old drive, checking that I do not needlessly duplicate eg. shared libraries or create other conflicts because I’m now working as my own package manager, and then after all the work is done… well, it works, at least until I try to use the actual package management system which is blissfully oblivious of the fact that I’ve jerry-rigged the filesystem.
I’d rather not. That’s a terrible way to do things.
>>If a program is running, it has a $CWD value it can use
>Which is not necessarily the path where the program actually lives, so if you want the software to find its configuration files you have to put them in known places. Hence why the filesystem hierarchy exists. As far as I know, there is no standard and reliable way for a program to find itself in Linux, like there exists in many other OS.
You are correct that $CWD may not be the location where the program resides. You can, however, determine this easily by using: dirname $( realpath $0 ) – This will convert the running program name into a canonical path and extract the directory from the name. I use this trick a lot in my bash scripts to find configuration files placed alongside the script.
If you’re looking to do something similar in a programming language, both realpath and dirname are functions in GNU stdlib, so any language that has bindings will have support.
Without you telling me “mount -o bind /usr/bin/myNewProgram /dev/hdd2/myNewProgram” I would call this the definition of “hair-pulling exercise of magnificent proportions with a high probability of bricking your entire OS”.
Many people use Linux in order to use developer and CAD/CAM tools. Searching for and reading various man pages and tutorials (which always have comments from people who say it didn’t work for them) in order to cross your fingers and pretend you know as much as a sys-admin is far from ideal.
>”If your file system doesn’t support `df -h` – please use a proper file system.”
Doesn’t solve the problem. If I’m asking “Can I put these files here? Does this location have enough space for it?”, the issue is that I don’t necessarily know where “this location” actually is. Likewise, when your file browser is showing how much space is taken up by your files, some of the files can be coming from somewhere else entirely, and so the “folder” isn’t entirely on the same device, and therefore the question “how much space am I taking up here” isn’t easily answered just by listing the sum of the files.
It’s like packing up for a beach holiday and thinking, “Hmm… my suitcase is almost full, but there’s room in my pockets, so half of the beach ball can go in my suitcase and the other half in my pocket. Problem solved!”
$ df /some/location
and
$ du -x /some/location
do exactly what you seem to want, without requiring you to know what filesystems live where. (It should go without saying, but you may need additional options to get exactly the information you want, formatted as you want it.)
Personally, I seldom use a file manager, and only for specific sorts of tasks that don’t normally involve concerns about used and available space, so I can’t offer you advice about where/how file managers expose equivalent functionality, but either your file manager sucks for lacking that functionality, or you’re imagining problems where they really don’t exist. If the former, understand the issue is with your specific file manager, and not with the possibility of bind mounts.
If you are likely to run into that scenario (I never have, programs themselves on Linux take less space than their Windows counterparts because of sharing shared libraries), just use a filesystem that allows you to add a hard drive to *that filesystem*.
“””Hard links only work on a single file system (that is, a single disk drive)”””
A single filesystem can be a part of a drive (partition) or span multiple drives or even (networked) systems.
Better delete the “(that is, a single disk drive)” part “on a single filesystem” really is enough and needs no further explanation.
Just wanted to add, links (both hard & symbolic) are file system’s property not Linux’s. Linux can NOT create a link on FS which does not support it (eg FAT or NTFS) Though we can create a symlink pointing to files on FAT / NTFS etc.
NTFS supports links, symbolic, hard, as well as junctions (similar to bind). Usage is a bit obscure though.
While you are correct Linux itself can’t do anything like that, it is possible to have filesystems that provide that support on NTFS where it exists and even on other things. For example, Cygwin emulates most of this on any Windows filesystem. Granted, how it does it is ugly, but….
“it is possible to have filesystems — that provide that support — on NTFS where it exists — and even on other things.”
What? I inserted the “–” to make it ‘sound’ a little trumpish because I have no idea what you’re trying to say.
What does cygwin emulate on what Windows filesystems?
NTFS has native support fur junctions, mount points and soft+hardlinks and cygwin does not emulate anything there – it just uses them (see here: https://cygwin.com/cygwin-ug-net/highlights.html – search for hardlink).
Even on FAT filesystems
Well that’s true, I should have said “typically a single disk drive” although perhaps a single volume would have been more accurate. But still…
“Have you heard it said that everything in Linux is a file? That is largely true, and that’s why the ability to manipulate files is crucial to mastering Linux Fu.”
A view where the container is as important as the task that created it. A view where human-oriented hierarchy and naming are essential skills in getting one’s work done. Where performance starts with a “./” and wanders into the aether from there.
Sometimes, even often, a statement that “linux can’t xxx” is actually a statement of its author’s lack of knowledge, or to be as kind as possible, a statement that hasn’t been true since the deep past. Or even then. My programs, for example, have zero issues finding their files without hardcoded paths (hint…it’s passed in…as an argument) and most linux, all that I’ve used, don’t even have the concept of putting things on particular drive as such (utilities of course, excepted). It’s all paths! You can mount anything anywhere, as many drives as you like (which I often do, even in raspies).
Even perl, that hoary old thing, supports all this without hardcoding anywhere in sight.
I advise just ignoring the troll, clearly has never thought to check for $PWD…
Getting the current working directory is not necessarily the same as where the program is actually located. If someone runs the program from a command prompt, then the program is being run from the command prompt’s current working directory even though the program file lives elsewhere.
As far as I know, there is no standard way for a piece of software in Linux to know where it exists in the filesystem, so it could do things like find its own configuration files, which is why the filesystem hierarchy standard exists in the first place.
Nor should there, IMO. That’s one of the powerful parts of Linux. In the general case, you specify a config file on the command line which has all the paths located inside it, or the defaults and have them commented out (and you can easily find out which config file it’s using with ps). Otherwise the config files are almost always in /etc.
>”My programs, for example, have zero issues finding their files without hardcoded paths (hint…it’s passed in…as an argument)”
That statement was in reference to the fact that a piece of user software in Linux does not “know” where it is, so it has to exist in the hierarchy in a pre-determined place or break down. You can’t just take the files, put them anywhere and expect the program to actually work, which means you can’t easily have eg. two versions of the same software on the system. The fact that each and every piece of software has to be “assimilated” into the filesystem like it was the Borg is a great disadvantage.
>”don’t even have the concept of putting things on particular drive ”
And that’s the great disadvantage. For example, I’m running low on memory on my phone, which has 8 GB of storage, and a 32 GB SD card. If I was running an old Nokia with Symbian, I could literally just move the program to the SD card and run it from there, because Symbian had the drive-folder paradigm and software packages were compact rather than shot around the system tree like so much shrapnel from a grenade.
>”You can mount anything anywhere, as many drives as you like”
So if I’m running low on space on my drive, can I somehow mount more space into it, in general so I could install a new program using the package manager? How do I tell the system, “okay, all these paths can now also access this new device so if there’s no more space on the old you can write there”?
“That statement was in reference to the fact that a piece of user software in Linux does not “know” where it is”
Most software doesn’t care where it is. It’s quite easy to discover where it is running from.
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type “help”, “copyright”, “credits” or “license” for more information.
>>> import os
>>> os.system(“ls -l /proc/self/exe”)
lrwxrwxrwx 1 simon simon 0 Mar 16 19:33 /proc/self/exe -> /bin/ls
0
>>> os.readlink(“/proc/self/exe”)
‘/usr/bin/python2.7’
N.B. I started python with the ‘python’ command which is a symbolic link to /usr/bin/python2.7.
So you can find the actual location of yourself quite easily, if you want to find which symbolic link was used to launch you now that’s another question…
And what if the OS doesn’t follow the “/proc/self/exe”?
Eh? So you’re talking about OSs other than Linux now?
No. /proc/self/exe doesn’t always work, in some distros/versions/configurations you may need to run as root to read it, or in case you’re running a multithreaded process and the original thread is already closed it no longer gives you the expected result.
It’s not reliable, so using it to make portable of “movable” apps is prone to breaking.
While I don’t disagree, every system I’ve ever been on gives you some indication of where you are via argv[0] which I assume you can read from Python. Now it might be a relative path (like ./foo) but with the current working directory info you can work it out.
Though of course, I -could- use LVM if I was particularily adventurous and if the Linux distro I’m using supports having the root filesystem on a logical volume, assuming if I had the foresight to actually use it, and didn’t care about the fact that I’d create a bomb where the failure of the old drive would crap the filesystem on both drives, or the fact that I’d have no real control which drive actually holds which file.
Again, messing with your whole filesystem in order to add a bit more elbow room is far from ideal.
Maybe you shouldn’t? “Were things are” is the domain of computers. “Got to get this work done and out the door” is the domain of humans.
The point is that I shouldn’t have to.
If you’re installing things via a package manager, then it’s up to the package manager whether it wants to let you install things to alternate locations. If building from source you can invariably invoke configure with –prefix= where it will then create a hierarchy needed by the app e.g. lib, include, bin under . You may then need to fiddle with you ld.conf or LD_LIBRARY_PATH.
But if you just want to create more space, you could do worse than to create a /usr2 representing the new drive, and then everything new goes in there. Again, it’s up to the package manager if it wants to let you.
And she don’t wanna. That’s the whole issue.
It’s like the developers just assume everyone’s going to have terabytes of disk space and never run out.
When you run out of space, there’s no magic button that will make more space from thin air. You need to buy and install new hardware to add disk space — how you go about this determines how much trouble you’ll have.
You make life harder for yourself when you buy a small drive, add it alongside your old full drive, and try to carry on. It takes the least effort in the short term, but you’ll pay for it over time.
You make life a little easier if you buy a new drive much larger than your old drive, and copy your old filesystem(s) over — takes just a little more work, but now everything’s on one drive again, with plenty of room to grow. It may be a little wasteful, as there’s presumably nothing wrong with the old drive. (If you buy big drives in the first place, by the time you run out of space, $/GB will have dropped so far it won’t seem very wasteful, but still…)
Even better, though even more work, is to identify why your old drive that you thought would be big enough wasn’t — whether it’s because you installed a bunch of games, because your collection of torrented sitcoms keeps growing, or whatever. Once you’ve identified the storage hog, which we’ll call x (and which most likely didn’t come through your package manager), you can figure out how large of a disk you’re likely to need for x, and move all the existing x to the new disk. Now there’s no wasted disk; your old disk with everything but x has lots of free space, and your new disk with only x also has lots of free space — you can let the package manager keep installing things normally, and be happy.
And in the case where you really did run out of space just from regular, increasingly bloated updates through the package manager, although unlikely (you’d have been way closer to full after initial install than I’d tolerate), it’s simple: x = /usr — and again, your package manager will handle things normally.
Developers don’t assume people never run out of space, rather they assume people who do run out are going to follow one of the latter two strategies, rather than trying to randomly move a few applications to a different filesystem because Steam or their digital camera archive keeps growing.
Now that’s just silly. LVM has existed for well over a decade and in most cases is offered as an install option. If one of the underlying drives fails that’s your fault for not backing up and/or creating a RAID array.
What you’re really complaining about is the fact that you didn’t properly spec out what you needed before you did the install. If you had, then you’d know if you needed LVM or not and what the drive layout should be. And both of those are options on all the major Linux distros. If your poor planning results in you having to reinstall the OS, that’s not the fault of the operating system.
There is one thing which bothered me in the past. It is written, that the content of a directory, after mounting a tmpfs over it, can still be viewed with i.e. this command:
mount -o bind /tmp /oldtmp
But this doesn’t work for me. When i try this on an example directory (ext4 partition) i still see the content of the ramdisk in the new directory and not the original content on the disk anymore. Maybe i’m doing something wrong, because i read it elsewhere on the internet that it should work.
loop filesystem too
Hard links “are not super useful” ?
I don’t agree: They have *specific* uses, and that’s very different.
Two real-life examples:
– at home, my NAS is backed up everyday to an external HDD, and the backup starts by creating hard links for all the files (several hundred thousands) of the day before (taking zero HDD space), and then updates all files modified that day. The net result is a full daily copy that only takes the space of the few modified files. Older backups are deleted, but as long as a file (or a file version) is referenced in at least one backup, it remains available. Only files (or file versions) that are not referenced anymore in any backup are really “deleted”.
– at work, a large linux NAS storing video files presents Samba shares to Windows users. When a user requests a video file, he gets a read-only hardlink to the file in his share, and he can watch it then delete it when he’s done with it. The hardlink takes no time to create, and uses no additional space. And when a source file is archived to tape, users who have requested it still can watch it until they delete it, and that releases the disk space.
Basically, what makes hardlinks powerful is that they are all made equal. They are just directory entries undistinguishable from the “original” one.
So, agreed, hard links are not as frequent as symbolic links, but it doesn’t mean they are not *useful*…
Ignoring the rest of the drama…
FUSE filesystems can be *very* useful. Everything is a file in Linux, and FUSE lets you hook/extend that capability pretty much however you wish and without delving into kernel level stuff.
Of course the aforementioned sshfs is awesome and I use it pretty much every day, but there is also smbfs, caching filesystems, disconnectable filesystems, etc. I have every filesystem on every box I use mountable (but not mounted unless I’m using it), Windows, Linux, etc… just by cd’ing into a directory, with zero changes required to the remote boxes, and without needing to create any new security holes.
Seeking within files and modtime tracking is implemented for the above also, so things like tailing the end of a rapidly growing 2gb remote log over a slow link, ‘just works’. Linux caching also still works properly, is configurable, and is sensitive to modtimes.
Have a terabyte of a hundred thousand zips and need to present a fake filesystem and temporarily unzip select files before passing them on to something dumb which needs random access to all the raw files? FUSE can do that.
Want to intercept every (or only one type) system call to anything below some path and confirm you have remotely logged it BEFORE allowing access? FUSE can do that.
Want to control logical access to a physical file system with, say… Active Directory groups tied to MySQL? FUSE can do that.
Want to have the same device accessible in two paths, and apply different parameters to said device depending on which path is currently being accessed? FUSE can do that.
Want to build a 200 disc DVD changer where all discs appear to be mounted at the same time, but you need to send serial commands to mount each one? FUSE can do that.
I’ve been asked to do all of the above at one point or another and FUSE let me solve the problem at hand until the lacking point of the existing architecture could catch up.
Very hackable. Easy to understand. Code for it as scripts, all the way up to C (read: as fast as you need it to be). Native caching works, or implement your own caching rules…. your choice.
If you haven’t tried it, it’s worth a look.
One fun thing about symbolic links is that you can store any string in there besides a path. Since you can create a link to a file that doesn’t exist yet, it doesn’t check the validity. One thing I use this for is for keeping metadata on offline storage. I have a bunch of hard drives that I archive data to and just put in a caddy when I need it. To make ‘find’ it easier (i.e. with ‘locate’) I create a mirror of the directory tree of the drive but with null files. I can sync the dates, however it’s also useful to know the size of the file and it’s hash, so my mirror is actually all symlinks with the filesize and hash in it, as the link target. That way I can determine if an online file is a duplicate of an offline one. The file itself is still 0 bytes; I believe the string goes in the directory entry. Probably other uses for this “tiny files” trick.