Getting into the weeds of operating systems is daunting work. Especially when the operating system involved is a fully featured modern PC operating system with millions of lines of code all working together to integrate hardware and software seamlessly. One such operating system “weed” is figuring out how to handle simultaneous tasks when the processor can only really handle one thing at time. For that, you’ll be looking at the difference between spinlocks and mutexes.
Both of these are methods of making sure that the processor completes a task sufficiently before moving on to the next task. Modern computers are so fast (even ignoring multiple cores) that it seems as if they are doing many things at once. In order to maintain this illusion, tasks need ways of locking the processor to that specific task for a certain amount of time. Of course the queue for performing the next task can get complicated as there are often many tasks waiting to use processor time. Spinlocks are a simple way of holding the processor and mutexes are a slightly more complicated way, but which one is the most efficient use of system resources isn’t that straightforward.
If you’ve ever been interested in operating system details, this one goes deep into the intricacies of features most of us have never even considered the existence of. It’s definitely worth a read, though, and is very well written by someone who is clearly an expert. If you want an operating system challenge, you can build your own operating system as well.














Spinlocks should only be used if you know exactly what you are doing and you are optimizing for speed. In general, it’s much better to use mutexes and there are very few cases where you should use spinlocks.
Yeah, don’t do tests or trust the data; go with blanket fundamentalist assertions. Science forbids there’d be nuances!
So you go for premature optimization.
No, using just spinlocks or just mutexes is premature optimisation. Checking what works best is the way.
“Yeah, don’t do tests or trust the data;”
By all means people should run tests but then should also run realistic tests. The tests that generated the table very unrealistic.
Did you read what the post said? He didn’t say “you should test to see which is faster to decide what to use.” He said “if you know exactly what you are doing and you are optimizing for speed.” Obviously spinlocks are faster, because threads don’t need to sleep or wakeup, so you don’t have any queue management overhead.
But the reason why it’s true that “in general, it’s much better to use mutexes” is because spinlocks can be *dangerous*. You can get priority inversion, livelock, or deadlock situations. Again, as the original comment said, if you know what you’re doing and you really need speed, spinlocks can work. But because spinlocks are so dangerous, the right solution is to just use mutexes, in general, and if you find that the mutexes are a performance problem, *then* start thinking about spinlocks.
You don’t choose mutexes because of performance, you choose them for safety.
You can get all of those problems from mutexes, or build a spinlock system which solves them. It’s just down to the implementation. The main feature of mutexes is that they allow a thread to sleep while it is waiting for a resource, whereas spinlocks obviously do not.
Not “speed”, but *latency*. If you care about latency, you must use spin locks, period. No other options.
And in any hard- or soft-realtime case you must care about latencies.
” If you want an operating system challenge, you can build your own operating system as well.”
Isn’t that one of the class assignments in computer science? Sort of the “hello world” of CS.
Third year of CS, in a good program. Don’t assume they know anything in the first year and cram their heads with basic concepts. Teach them OO and hardware (like how floating point numbers are stored) in year two. Then bash their heads with writing a full OS in year three.
We started with PintOS, in a bootable state in Bochs. Then added a non-fixed file system, ELF32 compatibility, mutexes, threads, and a shell.
Sounds like a good curriculum. What’s in year four?
Don’t know, health kicked me out. It was pretty much open season, though. Design AI, code a database (not write SQL, write the code the puts SQL queries into memory and on disk), code a ray-tracer. I was partnering with the art department and writing AI for boids that ‘lived’ in a large install piece they were building, while arguing that statistics should count as my third year math requirement instead of the required partial diff-equations.
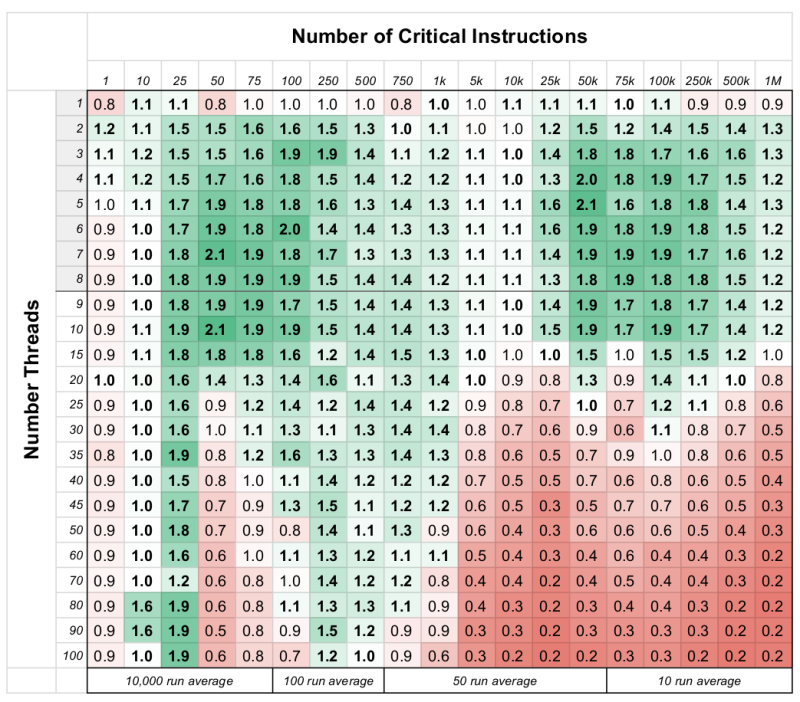
Or you could read the article and learn (with numbers) when it’s 2x better to use a spinlock and when it’s better to use a mutex.
It’s up to you to decide.
Interesting article and results, thanks!
One thought though: with a (very) simplistic workload model like this, will the test results really reflect the impact of e.g. cache effects which would be different with a real-world work load?
I went through the article and the paper hoping to understand spin locks verses mutexes. How were the timings obtained and how was it determined if a spin lock or mutex was used?
A little pointless “measurement”. On a single type hyperthreading cpu with synthetic workload, this measurement is only valid on this specific type of environment (cpu, OS etc) and workload, and no where else.
There is large difference between hyperthreading cpus and real multicore cpus. Totally not the same, hyperthreading cpus share all kind of resources (cache, execution units etc).
Also the way of OS handling the mutexes are not even the same on the same type of OS with same hardware, but with different versions or features compiled in the kernel.
And BTW there are several way to get around locking.
Most new modern approaches try to avoid locking with smarter solutions, or other way.
Ex. TSX (Transactional Synchronization Extensions)
https://en.wikipedia.org/wiki/Transactional_Synchronization_Extensions
Or with software, using dispatcher, which coordinates the working threads, fill there working queues etc.
Also spinlocks are only valid in multicore cpu environment.
I believe they disabled TSX.
https://www.anandtech.com/show/8376/intel-disables-tsx-instructions-erratum-found-in-haswell-haswelleep-broadwelly
It was disabled in Intel’s “Haswell” and “Broadwell” microarchitecture but it’s properly implemented in “Skylake” and later microarchitectures.
Article has insufficient depth and breadth. For most people doing stuff without the complexities of an OS , spin locks are not indicated – embedded stuff typically uses mutexes and semaphores to control thread synchronization. Most of us plebeians should be using a minimal round-robin scheduler, or just simple interrupts, on our arduino.
And am certain that wiki and stackoverflow discuss these subjects in nauseating detail, and are probably more useful.
Spinlocks are meant to be used in interrupt handlers because interrupt execution can’t sleep. That means that when an IRQ is triggered and the handler is executed, if the handler needs to sleep because it has to wait for something else (e.g. hard drive waiting for the controller response), then the only way to wait is spinlocks. It’s like a while loop waiting for an event. Then it unlocks and clears the interrupt flags. While waiting it consumes CPU cycles.
Almost on any other case you can just sleep. Sleep is giving the control immediately back to the scheduler so no time waiting is spend.
Therefore it does make sense to use spinlocks only in interrupt handlers and mutexes everywhere else. If you need low latency and deterministic behaviour globally to your OS then you need a PREEMPT-RT kernel or if it’s only for one application then also Xenomai can be used
Very true, but whom, other than RPi peoples, are using an OS where the kernel would do this wonderful stuff?
Very few operating systems are reliable; and Linux cannot be considered ‘reliable’. Unless you are doing a Mars lander, your embedded system probably will be much happier with a scheduler, or just simple interrupts.
There are plenty of “safety critical” embedded systems based on Linux. I wouldn’t be surprised if someone builds a Mars lander based on Linux in the next few decades. The existing rovers all use VxWorks, which in my experience isn’t any less buggy than a stripped down Linux kernel with a realtime scheduler.
You’re confusing spinloops (loop X times in order to delay) and spinlocks (loop until a particular resource is available, usually because the resource is in use in another thread).
Oops, I reread your comment. I still don’t think what you’re describing would be described as a spinlock (since there is no lock or unlock operation being performed) but I see that you’re not talking about sleeping for given time periods.
Spinning the CPU in an interrupt context waiting for an external device doesn’t sound like very good design. Sure, there may be some contrived situations where it makes sense, but they are the exception not the rule. It’s generally better to post to a semaphore or queue and then wait for the external device from a thread or main loop. External devices are incredibly high latency compared to a CPU anyway, so there’s no performance impact, and in fact you’re likely saving CPU cycles by not spinning for a long time in an interrupt context.
This is the only way. IRQ handlers (in Linux at least) are not tasks and are not subject to scheduling.
I’m by no means a Linux kernel expert, but my understanding is that there’s a “softirq” layer in which hardware interrupt handlers signal to softirq handlers to do any blocking work. There are about a dozen of them in a typical kernel, and they can preempt the main kernel thread but are preempt-able by hardware interrupts. I’ve encountered one myself in the device driver for a SPI based CAN controller.
You’re more thinking about kernel spinlocks (in situations where the kernel is one thread), which if you’re on a single-processor (and single-hyperthread) system, they literally optimize to nothing. But there are user-space spinlocks too, where multiple threads want the same resource, but you don’t *want* to sleep for some reason.
Think of the amount of effort that it takes to sleep. For a userspace lock, this means you remove your thread from the active queue in the scheduler, and place your thread in a waiting queue on the resource. This means that your thread resources – memory, code, etc. – could all get completely evicted from cache. Then when the resource becomes available, its waitqueue gets looped over, and the threads are then set active. Again, if you’ve been waiting a “while”, now all the code/etc. will have to page back in. That could Be Bad in terms of performance.
That’s the point here you see from the testing – spinlocks are faster for short lock periods. However, the reason you don’t use spinlocks by default in userspace code is that since you’re not *explicitly* doing the right thing like mutexes do, you can get spurious and incorrect behavior in some situations. It’s not really a performance issue, it’s much more a safety/correctness issue.
Really, though, the point to note here is that spinlocks aren’t really ever *dramatically* faster. A factor of 2 in terms of overall performance to avoid issues isn’t that big a deal, and if you *really* care that much, then you need to go down the rabbit hole of understanding multiprocessing really well in general.
What programming language was used in the linked article? I couldnt find it listed anywhere. Or was it pseudocode?
The key sentence in this whole article is at the end ie
“However, when critical section instruction count increases to above five thousand instructions and thread count rises above hardware supported amount, mutexes will perform better, as threads are put to sleep to make way for other threads to effectively use the CPU. ”
well, duh. How many times would the thread count be LESS than the hardware support? Not many! And of course, if you have more processing slots than threads spinlocks work faster as there is almost no point putting a thread to sleep!
I’ve been programming multithreaded applications for decades – on mainframes to embedded devices – and the amount of times a raw spinlock was the right thing to do could be counted on the fingers of one hand…
Clearly written by an undergrad for an assignment. Terribly written paper. Does not even describe the differences between mujtexes and spinlocks. Why did you point to it?