If you’ve programmed much in Linux or Unix, you’ve probably run into the fork system call. A call to fork causes your existing process — everything about it — to suddenly split into two complete copies. But they run on the same CPU. [Tristan Hume] had an idea. He wanted to have a call, telefork, that would create the copy on a different machine in a Linux cluster. He couldn’t let the idea go, so he finally wrote the code to do it himself.
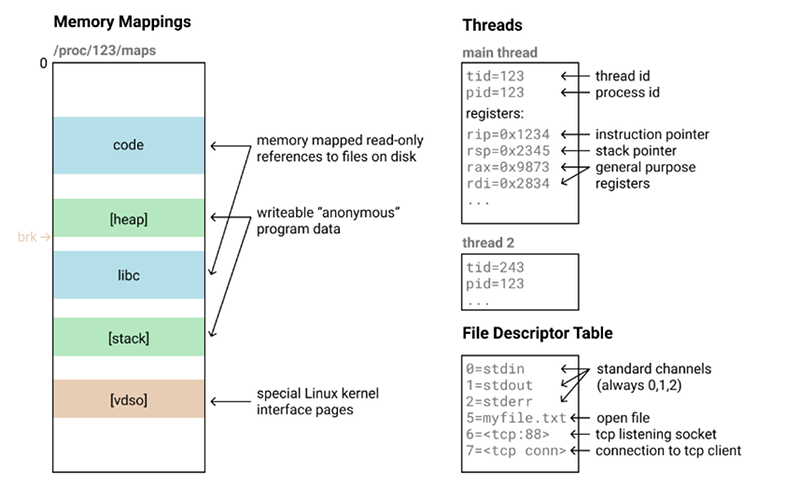
If you think about it, parts of the problem are easy while others are very difficult. For example, creating a copy of the process’s code and data isn’t that hard. Since the target is a cluster, the machines are mostly the same — it’s not as though you are trying to move a Linux process to a Windows machine.
However, a real fork does give the new process some things that are tricky like open TCP connections. [Tristan] sidesteps these for now, but has ideas of how to make things better in the future. He built on examples from other Open Source projects that do similar things, including Distributed Multithread Checkpointing (DMTCP). The task requires a pretty good understanding of how the operating system lays out a process.
In addition to making the telefork a bit more robust, [Tristan] has some “crazier” ideas such as sending data to multiple machines at once, or using virtual memory paging to only copy memory as needed. He even wants to allow a process to think that it has many threads, but that some of them are running on different CPUs. That means a program could “think” it had hundreds or thousands of cores. It seems as though there would be a lot of devil in the details, but it could work in theory.
This could be just the thing for your Raspberry Pi cluster. Probably not as useful for your ESP32 cluster, though.














Dang. I miss NeXT’s Distributed Objects.
Fork does not make separate copies, both programs use the same memory until one of them writes to a segment, at which point a copy is made of that segment
In modern systems, yes. Classically, no.
Copy-on-write was a standard feature on VAX VMS from the 1970s, BSD has always had copy-on-write.
The “classical” work on Unix, “Advanced Programing in the Unix Environment” which predates linux, has an extensive discussion on virtual memory paging and copy-on-write.
I think Al refers to the original Unix in the PDP-11. AFAIK, it didn’t have memory protection, so it couldn’t implement copy-on-write.
Same thing, from most practical points of view, for users or programmers. If you’re writing the OS you need to worry about it. It’s just a hack to increase efficiency.
Unix is full of aliases, Unix file systems are full of them. For didactic purposes, like this article, you may as well miss out that little exception.
aliases are fun alias popular dos commands to rm *.*
Why do you miss them? They are still alive and well in GNUstep.
It’s called MPI 😉
MPI does not facilitate sharing memory between processes and cannot directly send code to execute to another node. One node can ask another to spawn another MPI application process, but that’s done by giving an executable name that the target node must have in its filesystem.
Well I thunk that was already possible on some linux clustering systems, maybe it was just launching a process on a node, not forking to one.
Sounds like he’s headed in the InfernoOS/Plan 9 direction with his future plans.
Those have every network facility but process migration. It’s been discussed and desired, of course, but in 10+ years, I don’t quite remember even hearing a claim of implementation, not even from the SP9SSS. ;) In a sense, Plan 9 & Inferno would make parts of the job seem easy: a migrated process could continue to use the same /net, but to do so all its packets would pass through the original machine twice, which is ridiculous.
telefork, not telework
Grammarly adding autocorrect has been killing me. I really need to go figure out how to turn that off. You know the old saying… a poor workman blames his tolls… I mean tools… $*(#($ autocorrect! lol
Four womb the belle tools!
B^)
Not to mention they upload everything you type to the mothership. Obviously not an issue for material that you’re actually planning to publish, but make sure you turn it off as part of your sanitising procedures (VPN, private window, you all know the drill!) before you do “extracurricular” stuff.
I know enough about fork to know that you shouldn’t use it. Seriously, it’s not good.
The only way to start a subprocess on Linux is with fork() (or something that wraps it like system()) …
So, yes, maybe *you* shouldn’t be using it, but there are many valid reasons to.
Watch out, Lenny Potter will deprecate it, bc SysDerp could handle that.
(Yeah, I do know how he spells it. I just don’t care)
And goto is evil
People don’t appreciate a good GOTO, even when you use entertaining labels like hell: or the_deevil:
chance are mone that I’ll ever use this function but, please elaborate. Thank you.
This is actually a very similar problem to live VM migration… You can do a lot of this from user space even with mprotect() and a SEGV handler (marking pages read-only when migrated and if they fault, mark them read-write and stick ’em back on the dirty list) and at some point when your working set stops shrinking hit pause, copy the whole shebang over and unpause on the far end.
This is much easier with VMs because their TCP/IP stacks are *inside* the state that’s snapshotted and migrated but other processes that use taps or other raw-L2-based communication and contain their own user space network stack should in theory be able to maintain active TCP sessions across migration. (Forking with established sessions is probably not what you want to do anyway).
bproc()! And yes, it really IS a beowulf cluster this time. :-)
That’s exactly what I was going to comment: that looks a lot like the old Beowulf cluster.
https://en.wikipedia.org/wiki/Beowulf_cluster
scp your program (e.g., progname.sh) to the remote host then do this:
ssh user@host.com ‘nohup progname.sh >/dev/null 2>/dev/null </dev/null &'
See more here:
https://unix.stackexchange.com/questions/345832/how-can-i-start-a-remote-process-on-a-remote-machine-via-ssh/345843#345843
It seems the goal here is subtly different. They want to mimic the functionality of the fork() system call over a network – that is to duplicate the entire running state of a program on another machine, not just start a new instance from scratch.
The threads-thing is going to be difficult: threads expect to have common variables in memory. An implementation of that would need to do something like write-protect all memory and when one of the threads writes to that memory, all threads across the cluster would need to be stopped until you’ve updated that page in memory on all cluster members….
This “weak sauce” approach will fail for just about any program that’s more sophisticated than “hello world”. If you put in the needed work to get file descriptors to function, (don’t even think about listening sockets or shared memory or pipes or threads or mutexes or semaphores, all lost causes, and we’re back to “hello world”) you might as well just write your own operating system from scratch.
i agreed with you, X, before i read your comment….but such a clean statement of the problem produces an obvious (and preposterous) remedy of keeping a tcp connection open and doing all fd i/o over that. IPC (shared mem/mutex/semaphores) would still be a bridge too far, but pipes and open file descriptors could be preserved. slowly.
In the same memory to be precise.
Would it not make more sense to add a system call that just transfers the current process to another machine?
You could still accomplish what Tristan has done, but that would require two system calls (fork + transfer).
The good things about separating fork and transfer are
1: a process can be transferred without a need to create a duplicate process
2: if (some) file descriptors or sockets cannot be transferred, this can be more obviously documented
Look up process migration. ;)
Here is yet another shameless low-effort mention of OpenMosix and its successor LinuxPMI.
Man, the memories. I was looking into OpenMosix back in the day for some cluster compute problems. It looked promising, but we ended up going with custom MPI code b/c we could get it working.
LinuxPMI pulls up dead servers.
Any slightly-less-low-effort links?
In operating systems, all the really interesting stuff ends up as dead links in the end while we all rehash a few last-century ideas with enthusiasm and sometimes a lot less sense. :/ I’m exaggerating slightly, but it’s depressing to see all the lost tech. Still, it can be reinvented, and to be honest, I get enthusiastic about rehashing some last-century ideas too, they’re fun.
Hm… not all the really interesting stuff is lost. Plan 9 from Bell Labs managed scrape through and has a maintained fork now. Recently I’ve got interested in this Plain English Programming thing a couple of guys got together about 10 years ago — it’s more practical than previous attempts and wonderfully easy to read. It’s well on its way to being lost though, because the vast majority of software enthusiasts these days hate anything which isn’t a slave of the Temple of the Continous Update. ;)
All ur hosts r belong to us!!
Seriously though, yes, there are just a couple bandwagons out there and nobody dares to try anything original. Seems like there should be some way to create a useful OS that isn’t Linux or BSD or windows, that wouldn’t require this damned continual update crap show. Seems like if you could nail that model, people might actually be attracted to something that doesn’t have to phone the mothership at every turn.
CP/M is what you guys want, unpatched for nearly 40 years. Security by obscurity is it’s greatest feature! … Oh crap, just broke the first two rules of CP/M club.
@ RW ver 0.0.3
(No ‘reply’ link? They disallow stacking em more than 5 deep here?)
Maybe CP/M or something like it isn’t such a bad idea. Seems like back when computers were islands and communications were purely for data, there was a lot less trouble with ‘security’. It’s only since we’ve gone all-in for just executing anything we find from anywhere, that we’ve gotten into the security mess.
It’s OK, turns out CP/M club is just you and Gary Kildall, and he’s a figment of your imagination.
Plain English programming! May I introduce you to a little thing called “COBOL”?
Well, it’s not actually that little. In fact it’s fuckin’ enormous, it’s like writing a novel just to sort a list.
I’m not gonna ask how you do it, cos I don’t wanna heap yet more complicated trivia onto my abused brain, but you would think English would be a terrible programming language, with a fairly weak logical structure, tons of ambiguities, and tons of exceptions. It’s probably less of a headache just doing it in machine code.
new man eating shark
we have http://web.archive.org/web/20170518080021/http://linuxpmi.org/trac/ and a quick web search for any clone of their missing git repo turned up one of the locals: https://hackaday.io/JuliaLongtin
Back in my college days, when phones were phones, PDAs were little more than calendars and powerful handheld computers with wireless internet that one can carry in their pocket were out of reach on all but the biggest budget I played with OpenMosix.
My dream was a PC in every room. To achieve it I would use old, inexpensive parts to build them so most would be slow. They would achieve speed by all being linked together and spreading their processes around. Basically I wanted a distributed desktop.
In reality I had two computers, one ok for the time, the other slow. I had thought that the slow one might migrate some of it’s processes over to the faster one. It never happened unless I manually made it do so. Perhaps my network (10-base T at the time) was too slow. Or maybe it only worked with jobs that split into a really large number of processes. I don’t know.
I hoped that some day OpenMosix would get merged into the kernel itself and with more development something like I wanted to build would be possible. I also hoped to eventually get involved myself. But OpenMosix is gone now and it looks like LinuxPMI is too. I still have an interest but zero motivation to learn that kind of low-level OS programming. Coding is my day job now although it’s much higher level application stuff. It’s hard to want to do something as a hobby when you do it all day for a job. Also, the distributed desktop idea make a lot less sense now that my cellphone has enough power to be a desktop PC all by itself.
There’s not a lot of heavy loads these days that you encounter at home to be worth doing. Myself I could be interested in some video conversion and reformatting load spreading. But automated solutions I’ve tried on that, just to leave one machine doing batches have tended to go a bit “sorcerers apprentice” on me and screw up in various ways.
the funny thing is a thin client will serve, and now that i have a $180 “toy” chromebook with 4 cores and 2GB of RAM, i finally am living the dream…treating this supercomputer as a thin client. i even run the browser over rdesktop. :)
;-)
Mosix was fun 20 years ago. I need to read about what it has evolved into today. Didn’t get far yesterday and only saw x86_64 stuff… retry later…
This is process migration with the restriction that it can only happen during fork. It’s not a new idea. I briefly thought the “only during fork” bit might simplify implementation, but it won’t for reasons mentioned by the OP and other commenters. In fact, I think it’s a pointless restriction.
Hahaha! I just thought to check Wikipedia, and I see this very idea as the first concept under the first heading. It doesn’t mention fork though; that moves it more into the second of the two concepts, giving it some of the disadvantages of both. Regardless, it’s good to know someone’s having a go at implementing some form of process migration. Exciting stuff!
Boy do I NOT miss working on CORBA.
Sounds like what erlang already figured out
This looks pretty danged cool:
http://popcornlinux.org/