
Modern physics experiments are often complex, ambitious, and costly. The times where scientific progress could be made by conducting a small tabletop experiment in your lab are mostly over. Especially, in fields like astrophysics or particle physics, you need huge telescopes, expensive satellite missions, or giant colliders run by international collaborations with hundreds or thousands of participants. To drive this point home: the largest machine ever built by humankind is the Large Hadron Collider (LHC). You won’t be surprised to hear that even just managing the data it produces is a super-sized task.
Since its start in 2008, the LHC at CERN has received several upgrades to stay at the cutting edge of technology. Currently, the machine is in its second long shutdown and being prepared to restart in May 2021. One of the improvements of Run 3 will be to deliver particle collisions at a higher rate, quantified by the so-called luminosity. This enables experiments to gather more statistics and to better study rare processes. At the end of 2024, the LHC will be upgraded to the High-Luminosity LHC which will deliver an increased luminosity by up to a factor of 10 beyond the LHC’s original design value.
Currently, the major experiments ALICE, ATLAS, CMS, and LHCb are preparing themselves to cope with the expected data rates in the range of Terabytes per second. It is a perfect time to look into more detail at the data acquisition, storage, and analysis of modern high-energy physics experiments.
Major Upgrades for ALICE
The ALICE experiment is the oddball among the experiments, because it studies lead-lead collisions instead of proton-proton collisions. It also faces one of the greatest challenges for the upgrade because the observed rate of collisions will increase fifty-fold from 1 kHz to 50 kHz in the upcoming LHC run. With about half a million detector channels being read out at 5 MHz sampling rate this amounts to a ~3 TB/s continuous stream of data.
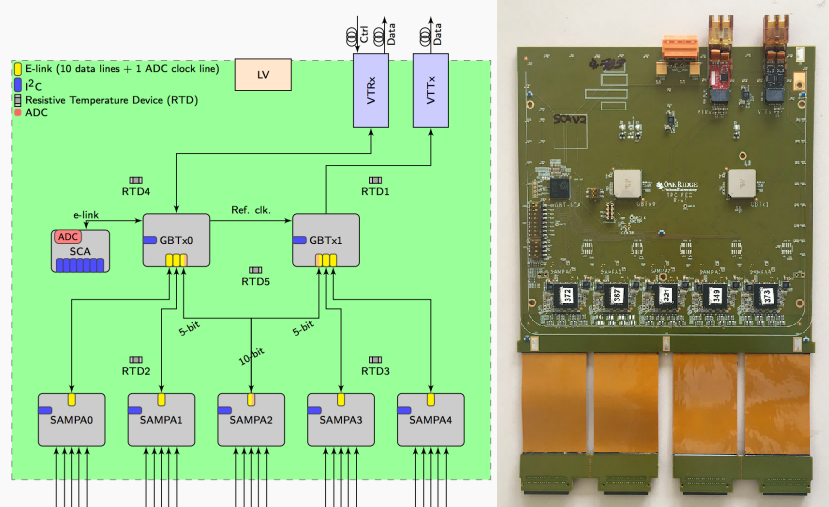
Credit: C. Lippmann
In order to cope with these numbers, the main detector of ALICE, a Time Projection Chamber (TPC), received 3,276 new front end electronic cards developed by the Oak Ridge National Laboratory. At the heart of the boards is a custom ASIC called SAMPA designed at the University of São Paulo. The SAMPA chip includes a charge sensitive amplifier, a 10-bit ADC, and a digital signal processing (DSP) unit. Doing DSP on the device can already reduce the data to ~1 TB/s through zero suppression.
Because the front-end electronics are located directly at the detector, they have to cope with high doses of radiation. Therefore, CERN started early to develop the GigaBit Transceiver (GBT) platform, a custom ASIC and data transfer protocol that provides a radiation-tolerant 4.8 Gbit/s optical link which is now used by several LHC experiments.
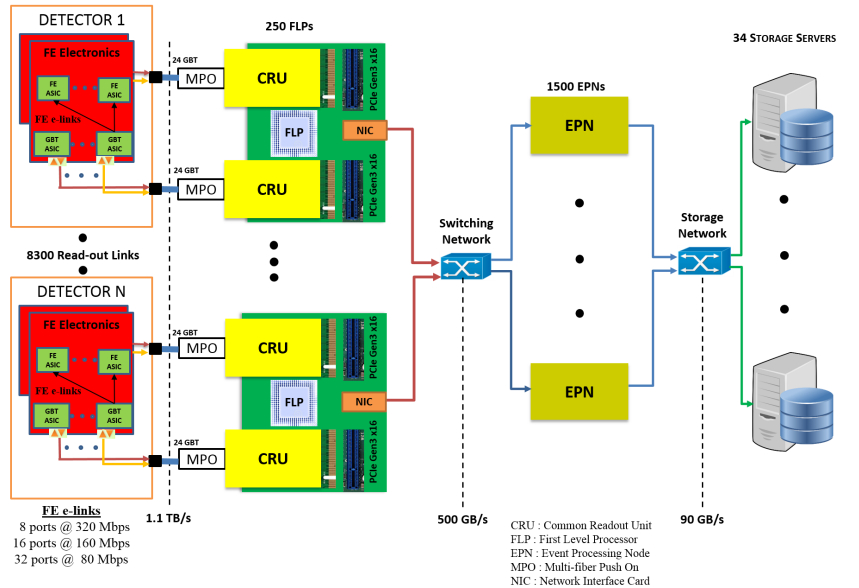
Credit: J. Mitra et al.
As shown in the schematic picture, data from the front-end electronics at ALICE is transferred to the Common Read-out Units (CRU) that serve as interfaces to the First-Level Processors (FLP). The FLPs are a farm of servers that perform a reduction of the data to ~ 500 GB/s by grouping the detector hits into clusters. The CRU boards are based on Altera Arria 10 GX FPGAs and use the commercial PCI-Express interface since it is cost-effective and widely available for server machines. The data merging and final data-volume reduction is performed by a second farm of computers: the Event Processing Nodes (EPN) reducing the data flow to about 90 GB/s which is then stored to disk.
The most time-consuming step during event processing is the reconstruction of particle trajectories. While other LHC experiments are still using regular multi-core CPUs for this task, ALICE is designing their tracking implementations to run on GPUs, which offer significantly more parallel computing power. A study showed that track-finding with an NVIDIA GTX 1080 is up to 40 times faster compared to an Intel i7-6700K processor. Interestingly, the tracking algorithm for the ALICE TPC is based on a cellular automaton.
Multi-Level Triggering, Machine Learning, and Quantum Computing
While the ALICE experiment will be able to continuously stream data from all Pb-Pb collisions happening at 50 kHz, the rate of proton-proton collisions at the other LHC detectors is as high as 40 MHz. Therefore, these experiments employ a multi-level triggering scheme that only reads out preselected events. The CMS experiment, for example, uses an FPGA-based level-1 trigger that can filter data within microseconds. The High-Level Trigger (HLT) at the second stage uses commercial CPUs to process the data by software where longer latencies on the timescale of milliseconds are allowed.
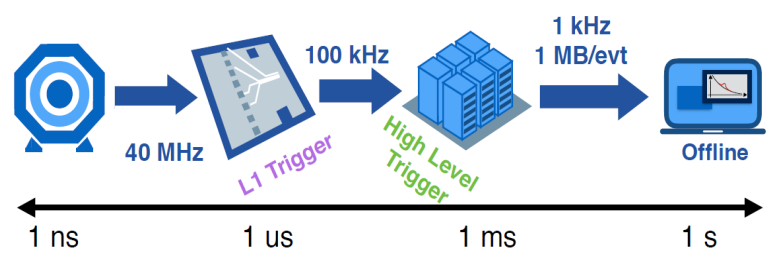
Credit: A. Castaneda
The HLT is responsible for track identification, a task that is currently moving towards the implementation of machine learning techniques. In 2018 CERN hosted the TrackML competition, challenging people to build a machine learning algorithm that quickly reconstructs particle tracks. An even more ambitious approach is pursued by the HEP.QPR project which is developing track-finding algorithms for quantum computers since these can potentially overcome the problem of combinatorial explosion. They already tested their algorithms on the TrackML dataset using D-Wave, a company that is offering cloud service for their quantum computers.
While a track finding algorithm can run comfortably on a CPU or GPU, the required low latency of level-1 triggers and limited hardware resources of FPGAs allows only very basic algorithms for data selection. More sophisticated algorithms could help to preserve potential interesting physics signatures that are currently lost. For this reason, researchers at Fermilab developed the hls4ml compiler package which translates machine learning models from common open-source software packages such as Keras and PyTorch into Register-Transfer Level (RTL) abstraction for FPGAs.
Data Analysis on the Grid
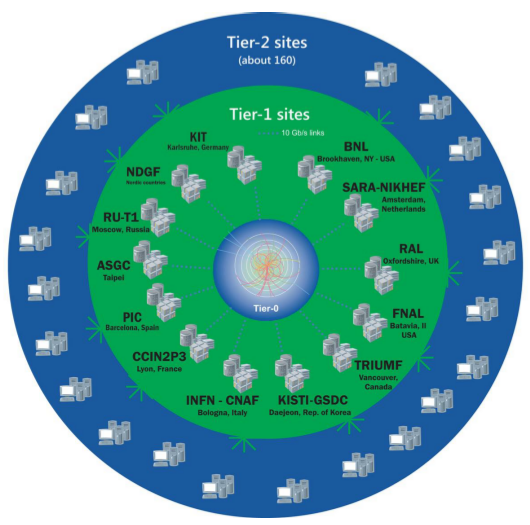
Credit: A. Castaneda
Machine learning is already extensively used in the offline analysis of stored data, in particular for particle identification. One example is b-tagging, which refers to the identification of events originating from bottom quarks that are important for new physics searches. Currently, the most efficient b-tagging algorithms are based on deep neural networks like the DeepCSV algorithm developed by CMS.
You might have heard of the Worldwide LHC Computing Grid (WLCG), where the data analysis is usually carried out. It consists of around 170 computing centers in more than 40 countries and totals about 1 million CPU cores and 1 Exabyte of storage. Perhaps less known is the fact that more than 50% of the WLCG workload is represented by Monte Carlo simulations. These “what-if” models of collisions are a crucial part of the data analysis and needed to optimize the event selection criteria.
Although many people are probably disappointed that the LHC did not yet lead to the discovery of new physics like supersymmetry there are still some persisting anomalies in the data. Even if the upcoming LHC upgrades will reveal these as merely statistical fluctuations, CERN will continue to be a driver for new technologies in the field of electronics, computing, and data science.














I’ve nothing against blue-sky research per se, but the scale of operations at CERN has in the past made me ask “why?” Space research and projects like the ISS, yes, I can see the end goal – similarly any research into fusion power. Is there a simple explanation out on the internet somewhere that could explain the reasons behind the experiments at CERN to an interested layman? Or is it “research for research’s sake”?
*goes to a website, posts from web browser* “Go on then, what’s one thing CERN has ever done for us?”
Also, 3 clicks from the historic info.cern.ch they explain their contributions thusly… https://home.cern/about/what-we-do/our-impact
Well one thing the LHC or its next iteration could possibly do is to verify graviton particles… which would give us the ability to hopefully manipulate them, imagine ditching rockets for ships that use no fuel and harness gravity. That’s kind of pie in the sky wishfullness but none the less, its these kind of things the LHC could find along with more standard particles leading to at least better material science, and a greater understanding of the universe.
There are a lot of things that could be detected at LHC, but gravitons are not among them. Gravitons would have to be massless (that speed-of-light 1/r^2 thing) so going to higher energies does not help in detecting them.
What LHC really is looking for is any evidence of supersymmetry, which would be required for anything even close to string theory (and which has not yet been found), and maybe, just maybe, high-mass WIMPs that would be the main component of dark matter.
So are you saying that trying to understand the fundamental laws in the nature of the fabric of our universe is not a worthy goal in and of itself. Because currently we do not have an application for that knowledge.
You could have said exactly the same thing about nuclear magnetic resonance back in the 1930’s, and now application of that knowledge is worth multiple trillions per year, the MRI market alone is projected to be about around 11 trillion in 5 years time. Or lasers in the 1950’s, at the time of their invention were considered to have no practical applications at all, I would not even attempt to guess how much money is spent globally on them today for many diverse applications.
Just because no one can see a useful application for that knowledge today, does not mean that in 20 to 50 years time that insight gained today might not be a pivot point for our species.
Sorry, I just double checked my numbers and I’m out – that line should be ….
application of that knowledge is worth multiple billions per year, the MRI market alone is projected to be about around 11 billion in 5 years time.
Nothing says “Trust me” like being off by a factor of a thousand. More troubling still is that you had to “douible check”. It didn’t look completely wrong to you? Harrumph.
If only I had an edit button, it is only a 60 dB error. no one would notice that :)
I have no clue about particle physics, but all this looks nice and with this processing power you could probably mine quite a few bitcoins. Or run Doom in ultra-hyper-3D-HD for several millions of people in parallel.
Or …?
“Or run Doom in ultra-hyper-3D-HD for several millions of people in parallel.”
Oh, I take it you haven’t joined us on Saturday nights?
I’ll ask the Grand Master to maybe shoot you an invitation.
I hear team 0xff10eb2a could use more cannon fodder.
You do have electro shock haptic joysticks, right?
“Unlike armchair generals, we will share the pain of our soldiers.” – Max Largo …
https://www.youtube.com/watch?v=vUc4GkMN1qs
Lead is diamagnetic,
how will they get it to go down the beamlines?
Diamagnetic materials have no unpaired electrons. Ionize an atom and you change the number of electrons, so the balance of paired electrons is thrown off. The LHC fully ionizes the lead atoms, so they lose all their electrons. Now it’s just a bare nucleus, so it behaves like any other highly positively charged particle.
“The times where scientific progress could be made by conducting a small tabletop experiment in your lab are mostly over. ”
That will come as a surprise to a great many experimental physicists.
^This
Most of my experiments can fit on an average benchtop. The biggest pieces of equipment I’ve ever needed to use were about the size of a small car (XRD, SEM, sputtering system etc.) Right now I’m running experiments for a paper that investigates an unexpected light emitter with very high brightness. The instrument I’m using is small enough for one wimpy scientist to pick up as a single unit and tote it around the lab.
https://www.extremetech.com/extreme/193725-the-worlds-most-advanced-particle-accelerator-is-just-12-inches-long-and-sits-on-a-lab-bench-in-the-us
And how many of you would be surprised to learn that the computers involved in running things over there are in fact running Linux?
wow, I read this article and thought – that could even run the current versions of microsoft software, instead of the normal 10 year wait to get hardware good enough to run the bloatware they make today (and that has been try for decades)!
And on another note, research like this invariables pays off one way or another – either what you find, what you don’t find, or what you make (or invent) to do the finding in the first place.. Really understanding what’s going on at the smallest end of the scale could potentially be the biggest payoff of them all..