For an old CPU, finding all the valid instructions wasn’t very hard. You simply tried them all. Sure, really old CPUs might make it hard to tell what the instruction did, but once CPUs got illegal instruction traps, you could quickly just scan possible op codes and see what didn’t throw an exception. Modern processors, though, are quite another thing. For example, you might run a random instruction that locks up the machine or miss an instruction that would have been valid but the CPU is in the wrong mode. [Can Bölük] has a novel solution: By speculatively executing the target instruction and then monitoring the microcode sequencer, he can determine if the CPU is decoding an instruction even if it refuses to execute it.
Some unknown instructions may have power for good or evil, such as the recently announced undocumented instructions that can apparently rewrite the microcode. We expect to see a post soon on how to reprogram your Intel processor to run as a 6502 natively.
The speculative execution exploit is quite clever. Modern processors execute code out of order and run different parts of instructions at the same time. In other words, it might be fetching instruction C while storing the result of instruction A and decoding instruction B. The problem is when the code can conditionally branch it causes a problem. If instruction A is a conditional jump, do you take B and C as the next instructions or the instructions at the branch address? Either way, if you are wrong you’ll need to discard any work you’ve already done and restart.
One answer is to simply stall the pipeline until the decision is final. That’s bad for performance, though. Another common technique is to try to guess what direction a branch in your code will take and use that. That might be a simple heuristic such as mode jumps go backward or it could keep a history of where the jump has gone in the past.
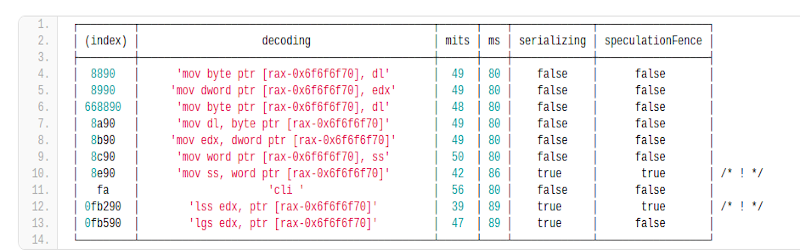
The key is that the code is partially executed, but can’t do whatever it is supposed to do until the branch resolves. Normally, that wouldn’t be helpful, but watching the performance counters of the microcode translators tells you if the instruction generated actual low-level microcode instructions or was simply pruned out immediately as a bad instruction. The assumption is that if the CPU designer sent an instruction to microcode it must do something. [Can] provides a list of instructions found on his i7 6850K CPU.
We love these deep dives into CPU architecture. Sometimes it leads to god-like powers, at least at the CPU level.














> reprogram your Intel processor to run as a 6502 natively
That would be cool, but the 16 bit address space would limit you to 64KiB of RAM :)
But having all your RAM fit in the CPU L2 Cache four times could be interesting performance.
i7 6850K
#cores: 6
Cache L1: 32K (per core)
Cache L2: 256K (per core)
Cache L3: 15MB (shared)
Then increase the size of the load/store instructions (add load/store instructions for 32 and 64 bit widths).
Or use the 6509 which can address 1 Meg of RAM.
Or use the 65816, it thinks it’s a 6502 until convinced otherwise.
But the 6509 was bank switched. It didn’t give you a bigger adress space, just 64K. You had to switch memory into the address space, yku coukdn’t address 1M directly.
Memory management was much more useful, shift blocks anywhere in the address space. The Radio Shack Color Computer III had that, get up to 512K, and Microware OS-9 had the code to make use of it.
Honest question here: Are you confusing the 6509 with the 6809? I’m pretty sure the Radio Shack Color computer was based on the 6809.
Nope, 6509, short lived 6502 variant with a four bit page register. There is a Wikipedia page for it.
I owned a CoCo and ran OS-9 on it. It most definitely contained a Motorola 6809. I also had an older SWTPC computer (my very first computer, built from a kit) that started out with the standard 6800, which I later upgraded to a 6809.
It might be helpful to mention that attempting to execute these instructions outside of a custom-hardware enabled debug mode will end in a #UD exception.
“Either way, if you are wrong you’ll need to discard any work you’ve already done and restart.”
And then there’s the GPU way.
https://core.ac.uk/download/pdf/191395004.pdf
Microcode is hard enough even with full documentation. It’t take a miracle to do anything useful with this.
It is like wondered into an Amazon warehouse *blindfolded* and try to figure out what and where everything are without sight or breaking the package.
So, what’s the OpCode for HCF?
(asking for a friend)
0xDEADBEEF
the run natively as xxx does that mean ine can implement multible instruction sets at once? so a x86 could also implement arm and mips and magically everything works?
Microcode effectively carries out the function of opcodes which are not natively executable (I.e. CPU does not have the hardware for it).
Rather than simple convert them into executable instructions like a JIT compiler it might use hardware in the CPU that’s not otherwise available to a programmer.
Back in the nineties, my group at the university designed a cpu architecture. We then tried to make it emulate x86 code. That was horribly slow because of the differences in handling of “flags”. So our emulator was doing real work 20% of the time and messing with the flags 80%,,, hardware support for the right flags behaviour would have sped things up enormously.
moooo
Any y’know… Evidence?
Evidence…? There’s supposed to be… Evidence?
Does that mean I can run the games I wrote for Apple ID?
| index | decoding | mits | ms |
│ 6690 │ ‘data16 nop’ │ 53 │ 67 │
didn’t understand the rationale for the decrease in the microcode sequencer. As data16 was was not decoded by mits, why did ms decrease below the baseline as well?