
You might not think that it would be possible to have a favorite optimization algorithm, but I do. And if you’re well-versed in the mathematical art of hill climbing, you might be surprised that my choice doesn’t even involve taking any derivatives. That’s not to say that I don’t love Newton’s method, because I do, but it’s just not as widely applicable as the good old binary search. And this is definitely a tool you should have in your toolbox, too.
Those of you out there who slept through calculus class probably already have drooping eyelids, so I’ll give you a real-world binary search example. Suppose you’re cropping an image for publication on Hackaday. To find the best width for the particular image, you start off with a crop that’s too thin and one that’s too wide. Start with an initial guess that’s halfway between the edges. If this first guess is too wide, you split the difference again between the current guess and the thinnest width. Updated to this new guess, you split the differences again.
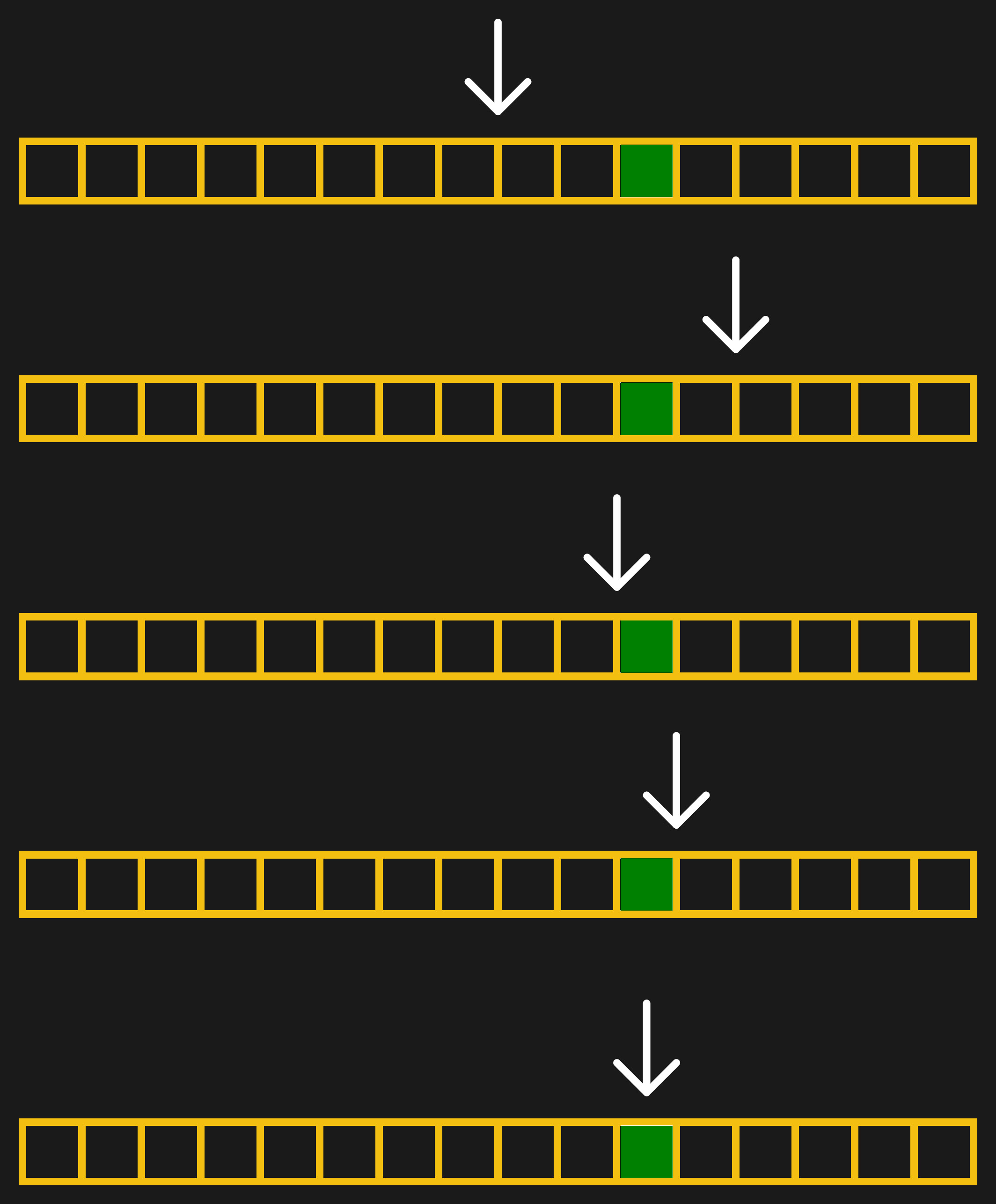 But let’s make this even more concrete: an image that’s 1200 pixels wide. It can’t get wider than 1200 or thinner than 0. So our first guess is 600. That’s too thin, so we guess 900 — halfway between 600 and the upper limit of 1200. That ends up too wide, so we next guess 750, halfway between 600 and 900. A couple more iterations get us to 675, then 638, and then finally 619. In this case, we got down to the pixel level pretty darn fast, and we’re done. In general, you can stop when you’re happy, or have reached any precision goal.
But let’s make this even more concrete: an image that’s 1200 pixels wide. It can’t get wider than 1200 or thinner than 0. So our first guess is 600. That’s too thin, so we guess 900 — halfway between 600 and the upper limit of 1200. That ends up too wide, so we next guess 750, halfway between 600 and 900. A couple more iterations get us to 675, then 638, and then finally 619. In this case, we got down to the pixel level pretty darn fast, and we’re done. In general, you can stop when you’re happy, or have reached any precision goal.
[Ed note: I messed up the math when writing this, which is silly. But also brought out the point that I usually round the 50% mark when doing the math in my head, and as long as you’re close, it’s good enough.]
What’s fantastic about binary search is how little it demands of you. Unlike fancier optimization methods, you don’t need any derivatives. Heck, you don’t even really need to evaluate the function any more precisely than “too little, too much”, and that’s really helpful for the kind of Goldilocks-y photograph cropping example above, but it’s also extremely useful in the digital world as well. Comparators make exactly these kinds of decisions in the analog voltage world, and you’ve probably noticed the word “binary” in binary search. But binary search isn’t just useful inside silicon.
Why Can’t I Beat It?
That example of cropping photographs above was no joke. I follow that exact procedure multiple times per day. Or at least I try to. When I’m carrying out a binary search like this in my head, it’s incredibly hard to discipline myself to cut the search space strictly in half each time. But I probably should.
 My son and I were calibrating a turtle bot a few weeks back. Basically, we needed to figure out the magic PWM percentage that made two different DC motors spin at the same speed. This would have been a perfect application of binary search: it turned either slightly to the left or the right, and we had good bounding PWM values for each case. But we kept saying, “it’s only going a little to the left” and bumping the PWM up by tiny increments each time. After repeating this five times, it was clear to me that we should have been using a binary search.
My son and I were calibrating a turtle bot a few weeks back. Basically, we needed to figure out the magic PWM percentage that made two different DC motors spin at the same speed. This would have been a perfect application of binary search: it turned either slightly to the left or the right, and we had good bounding PWM values for each case. But we kept saying, “it’s only going a little to the left” and bumping the PWM up by tiny increments each time. After repeating this five times, it was clear to me that we should have been using a binary search.
To see why you probably shouldn’t cheat on your binary searches, imagine that you don’t know anything more than that the goal is between the top and bottom values, but you’ve got this hunch that it’s closer to the bottom. So instead of picking the midpoint, you pick 10%. If you’re right, your next guess is going to be inside range that’s 10% of the current range, which is awesome, but if the target is even just a little bit bigger than 10%, you’re looking at a huge search space next round. Nine times bigger, to be exact. And the more uncertain you are about where the truth lies, the more likely you are to make a bad guess because there’s more space on the side that you’re betting against.
The choice of the midpoint isn’t arbitrary, and the above intuition can be given mathematical rigor (mortis) to prove that the midpoint is optimal when you don’t have extra information, but at the same time it’s incredibly hard for us humans to resist gambling. Take my son with the PWMs — he knew he was really close. But what he didn’t know was how close. Humans fixate on the current value. We “anchor“, in the terms of negotiations.
Part of why I love binary search is that this discipline helps beat down this human decision bias. But the other reason I love binary search is how readily it’s implemented in silicon.
Not Just a Lifehack
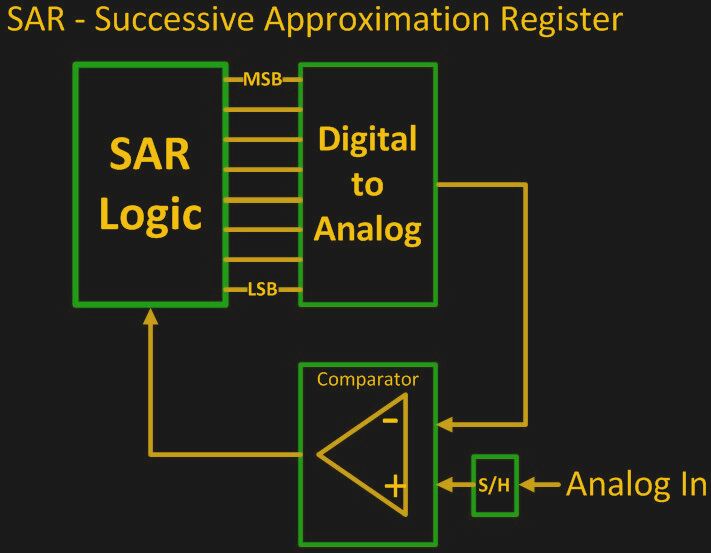 Those of you of a more software bent probably already have a deep love for binary search trees, but I’m a hardware guy. The analog to digital converters (ADCs) in my favorite microcontrollers all use binary search under the hood. They start out with the premise that the voltage they’re digitizing is between
Those of you of a more software bent probably already have a deep love for binary search trees, but I’m a hardware guy. The analog to digital converters (ADCs) in my favorite microcontrollers all use binary search under the hood. They start out with the premise that the voltage they’re digitizing is between GND and VCC.
Internally, the input voltage is stored on a sample-and-hold capacitor that’s connected to a comparator. The other input to the comparator takes the output of, ironically, a digital to analog converter (DAC). This DAC starts out with the midpoint voltage, VCC/2, and the comparator says whether the input is higher or lower.
With a 10-bit DAC, you can do this ten times, and that gives you a ten-bit ADC result. The coolest part is that the binary value on the ADC just falls out of the process. The first choice is the most-significant bit, and so on. If you’d like to see the circuitry in action, check out [Mitsuru Yamada]’s IC-based demonstrator. For more on ADCs in general, watch Bil Herd’s video.
Twenty Questions is Too Many
That’s why binary search is one of my favorite things. It’s a tool-slash-algorithm that I use multiple times per day, and it’s what underlies ADCs. Each step gets you essentially an extra bit worth of resolution, so in many real-world situations, you’re not likely to take more than 12 steps or so. Pick a number between 0 and 1,000 and I’ll guess it in ten tries.
As my photo-cropping example shows, you don’t even need to have a computable objective function, just the ability to say “bigger” or “smaller”. And where you do have an objective function, the computation burden is exceptionally light.
Of course there’s a time and a place for more complicated optimization routines — there are entire branches of science based on refining that particular mousetrap — but you’re not running simulated annealing in your head, or implementing it in raw silicon. The beauty of the binary search is that it’s also the simplest algorithm that could possibly work, and it works marvelously well for simple problems. Solving simple problems simply makes me smile.














Recently there was a post on Hackaday which linked to some documents describing (among other things) how to optimize binary search. Specifically it describes how to adjust binary search to go faster on modern hardware by doing things like reorganizing the data to make more optimal use of cache lines, or by removing branches to better take advantage of pipelining.
See https://hackaday.com/2022/03/09/modern-cpus-are-smarter-than-you-might-realize/
and specifically https://en.algorithmica.org/hpc/data-structures/binary-search/
Yep … there is a fine balance between being algorithmically perfect (as in smallest Big-O notation) and optimizing for real hardware. These days the most efficient algorithms are somewhere between binary search and linear search, splitting the dataset into manageable chunks binary(ly?) that then get searched linearly.
The math is off slightly, last I checked 900 was halfway between 600 and 1200.
800 is correct. If you’re counting South African desert crab hairs then definitely 800 because 100 of them will always blow away.
Oh, that’s silly. Fixed.
There’s another very good use for this style of something (binary).
On your favourite uC if you want to generate some PWM signals (as pseudo analogue or even passive filtered analogue) then the age old method is to attach an interrupt to a down counter/timer or the carry of an up counter/timer and flip the GPIO on the interrupt.
All is good. But now if you want to do the same thing with 20 PWM’s on 20 GPIOs then you don’t have enough counters and it would be a nightmare to work out which GPIO the interrupt is for.
In comes BAM Bit Angle Modulation (not my creation or naming).
The principle is the same. I’ll use approx 256us conversion time as an example. Check each binary value, if bit 7 is set then set the corresponding GPIO to 1 else set it to 0. Wait 128us then INTerupt. Check bit 6 of each binary value, if it is set then set the corresponding GPIO to 1 else set it to 0. Wait 64us then INT. Repeat at intervals of 32us,16us, 8us, 4us, 2us and 1us for bits 5, 4, 3, 2 and 1.
This can give you a large number of PWM outputs using one counter and one interrupt.
There’s a couple of gotchas, The first time you code this you will have PWM values range from 255 to 1. Your second attempt will be PWM values ranging from 254 to 0. So then you have to accept a range of 255 (either way) or get you nut working harder. It can be done but I leave that as a challenge for readers to get some satisfaction from.
FWIW in IC design we trim a lot of our parts after fabrication but before packaging, and do something quite similar. The first few thousand parts we trim (by vaporizing parts of something like an R/2R ladder so only one path is left) using a binary search exactly like this, but when we finally finish a trim program and release it, what we do is start with our first guess the guess closest to the average of the value used for the several thousand parts we already ran, and then start dividing from there. That gets us (on average) about 1.5 guesses less than a strict binary search, and if you’re running a million parts, that few microseconds of saved time becomes very worthwhile.
Man, I love the industry experience that pops up in these comments.
Have you ever though about doing a running average, so on the second chip using the first’s result, on the third chip the average of the first two? With an average of 1.5 guesses I can’t imagine the stddev is huge, so even before the first couple of thousand you could likely save a good few guesses.
Maybe not worth the engineering hours for implementation, though it would only take a few more rungs of PLC code (assuming you run the machine on a PLC).
This is a perfect example for the simplest Kalman Filter – to find the optimal starting point, not to vaporize stuff.
800 — halfway between 600 and the upper limit of 1200
Eh?
Imperial units i guess…
Homework: Find a base where this is true or prove it is impossible.
Isn’t this the same as the “Intervallhalbierungsverfahren”[1] (Interval-halving-method)?
Got a defect in a long cable and you want to rescue as many long stretches as possible -> divide and conquer!
I know I’ve used this method on other real life physical problems in the past – comes in quite usefull.
[1] bisection method – https://en.wikipedia.org/wiki/Bisection_method
It is! Funny how a super useful thing can gather a number of labels.
My most frequent use of the algorithm is determining exactly what caused the bug we’ve just noticed in our release candidate build: https://git-scm.com/book/en/v2/Git-Tools-Debugging-with-Git#_binary_search
Tell git which commit is known good, which is known bad, and it’ll help you binary search your way through builds until you find the exact offending commit.
Yep! Troubleshooting should always be done with a binary search approach, and it’s amazing how non-obvious that can be. When I train new people on troubleshooting data flow issues, everyone naturally wants to work backwards or forwards.
>> Between 1200 and 0 .. So our first guess is 600. That’s too thin, so we guess 800 — halfway … so we next guess 700, … 650, 675
Pro tip, If you’re doing this in a less powerful processor, like an Ardunio, start with the next biggest power of 2 as your upper bound.
Then, work your way down the chain by algorithmically working left to right, testing and flipping bits down to b0, which is very fast, instead of actively calculating the midpoints, which can be quite slow in a machine without a hardware divide
In this case assume between 0 to 2047. Set b10. Test >1024? No, clear b10, set b9. Test >512? Yes, keep b9, set b8. Test >768. No, clear b8, set b7. Test >640? Yes, keep b7, set b6… etc
On average, the worst penalty is 1 extra compare, and that is a small price to pay compared to all those divides.
This is exactly the same way that the SAR ADC’s in the example work, and they are very fast.
Good tip!
In software I’m finding a lot of algorithms that have unfortunate O(n**2) time complexity but can be reduced to O(n*log(n)) with the use of binary search or something equivalent on the inner loop. Linear time algorithms are often OK in isolation, but when they get nested your performance will really suffer.
“… Pick a number between 0 and 1,000 and I’ll guess it in ten tries.”
… not true if I can only answer YES or NO to your guesses. You need me to tell you HI or LO.
Is it greater/less than still provides a yes or no answer! In the example the author uses their eyes to judge if it’s bigger or smaller than the number chosen, so it’s still right.
when I read the title I was going to click and mention Newton–Raphson, but then the article did. I use it a lot, mainly with doing the derivative numerically.
It depends on what hardware you are on, and how big your table is, and what the distribution of the data is, but I have also found quite a few times that the Newton–Raphson ‘approach’ to searching data can be quite a bit faster than binary ie upper and lower range, take a stab at where it is on the values, then divide around that point instead of the mid point..
Some favourite animation about sorts –
https://panthema.net/2013/sound-of-sorting/
https://www.toptal.com/developers/sorting-algorithms
Some of them may seem to have no purpose. Many are where you have data distributed across many databases in different countries so data transfer (swap) costs time. Sometimes you need to end up with duplicate copies of the results in different places/servers. Some are where the data is always changing to close as you can get it is good enough.
Binary search is great, and can be massively improved if you can use non binary feedback. Ie for control loops you can use open loop, do one measurement and compensate for the difference, or closed loop by continuously checking where you are and where you need to go. As for the 2 motor robot, a feedback of bearing angle would allow a control loop to calibrate itself, taking in account slip of the wheel, objects that set the robot off course etc. So it’s not only just a human bias, but being a little clever about it, using more input than just high or low, you can get to the result quicker.
Binary search is great for fixing Christmas light strings! Check continuity between one end and the middle. Repeat with the open half. Repeat with the open quarter…
Nice to no: git can also do a binary search in your git history to find the latest commit that does not break your project. Use
$ git bisect start
to start the binary search for the bad commit,
$ git bisect bad
to mark the commit as bad or breaking and finally
$ git bisect good
if you found a commit that breaks your code.
I used to teach this to my students as a “phone book search” because they understood the concept immediately. “I bet i can find a name in that phone book of 65000 names in no more than 16 splits.”
Mind you, it was also easier to teach radix sort when students had used a punch card sorter. Sigh
These day’s isn’t it more politically correct to do a non-binary search?
*Ba-dum-dum-chh*
+funny
I was taught of binary search in uni, but I never thought I would end up using it where I did. I Had a line of christmas lights that were bad. About 60 lightbulbs in series. I set out to find the burnt out one, but after a visual inspection of each bulb I could not find the odd one out. So I cut the plastic off the wire in the two ends of the line as well as in the middle and used my multimeter to check for continuity. Instantly I slashed the suspected bulbs in half – the problem must be on the half of the line where continuity is broken. And then it hit me: this is binary search. I repeated the process and eventually found the culprit. In the end I had much fewer points on the line to patch up.
It is also the perfect method for finding out which breaker controls a circuit in an electrical panel.
One thing that I didn’t see mentioned about binary search (in the post) is the
fact that you can use it to find any piece of data (not just numerical values)
if you can apply yes/no or true/false to the current value.
For instance, recently I had an interview and they wanted to guage my problem
solving skills/process — they gave me a copy of the perodic table, said I
could ask them seven questions, and based on that I would need to figure out
which element they has selected.
By asking them if the element was in the middle to last row (or first to middle):
1. yes: the element is in that region
2. no: the element is in the other region
Contiuning that six more times will get pretty close to the containing row.
Afterwards you would need to switch to asking (as above) if it is between the
middle and last column.
Granted limiting it to only seven questions might be 1 or 2 questions short of
finding the exaxt element.
I demonstrated this to my 6 & 7 year old girls a few months back playing pick a number (generally up to 20 but now it’s much higher!) and they were gobsmacked I was getting it so fast. The way we played up to that point was always intuition (favourite number or a count of something in the current environment), but I took it up a notch to 1000 to show the binary method. It took a few tries for them to understand what it was I was doing and a few more to see how it worked (this part involved writing down the numbers 1-100 and showing how I was eliminating half each time with each guess). Low and behold both of them put it into practice when playing. I’d like to say parenting win here but they don’t play any more because I took the fun out of it, it’s too easy now they say (I’m slowly turning them into computers).