
For every very clever security protocol that keeps people safe, there’s a stupid hack that defeats it in an unexpected way. Take OAuth for instance. It’s the technology that sites are using when they offer to “log in with Facebook”. It’s a great protocol, because it lets you prove your identity using a trusted third party. You don’t have to use a password at whatever site you’re trying to use, you just to be logged in to your Google/Facebook/Apple account, and click the button to allow access. If you’re not logged in, the pop-up window prompts for your username and password, which of course is one way phishing attacks try to steal passwords. So we tell people to look at the URL, and make sure they are actually signing in to the proper site.
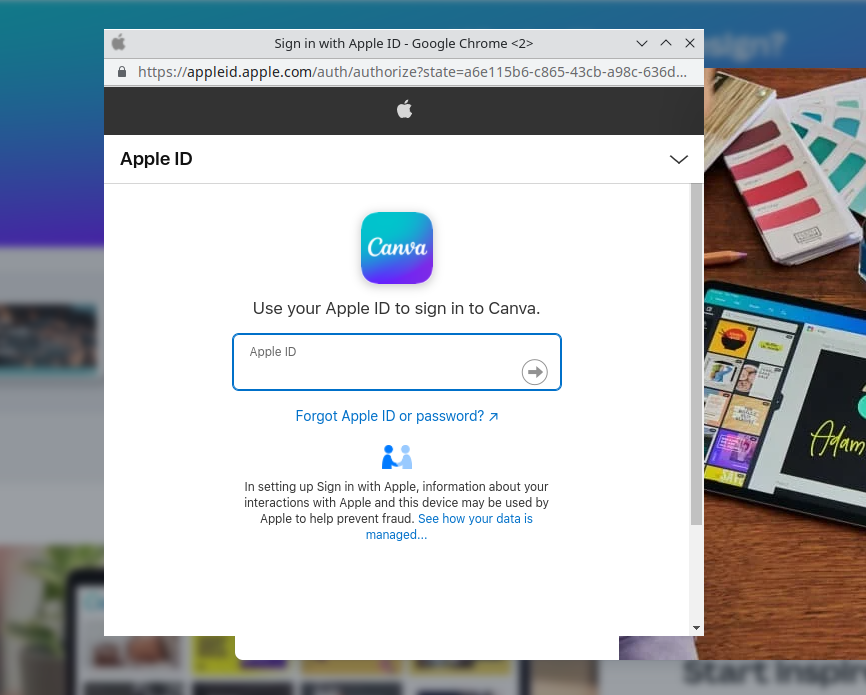
The stupid hack that isn’t stupid, because it works: Recreating the browser window in HTML/CSS. Yep, it’s pretty straightforward to add a div to your site, and decorate it to look just like a browser window, just like an OAuth pop-up. In the appropriate place goes an iframe pointing to the actual phishing form. It looks convincing, but once you’re aware of the game, there’s a dead giveaway — try to move the OAuth window outside the browser window that spawned it. Websites can’t draw outside the browser window or over its window decorations, so this limitation makes it easy to confirm whether this hack is in play. The other saving grace is that a password manager isn’t fooled by this trick at all.
Via: Ars Technica
Typo-squatting At Scale
There’s a typo-squatting campaign going on at NPM, primarily targeted at Azure users. NPM has a packaging feature called “scoped packages”. A scope starts with the at sign, and indicates packages intentionally grouped together. In this case the scope is @azure, including packages like @azure/core-tracing, with over 1.5 million weekly downloads. The typo? Just drop the scope. NPM considers it completely acceptable to have both the @azure/core-tracing and core-tracing packages — in fact, it’s a feature of the scoping system. But forget to include the scope, and you may get a malicious package instead. Over 200 packages were targeted in this way, but have since been pulled by NPM.
The payload was strictly reconnaissance, grabbing directory listings, IP addresses, and the like. It’s likely that the information would be used to craft more malicious future updates, though no such behavior has been observed. This is likely due to how rapidly these packages were caught and removed — after only about two days. The domain used for data collection is 425a2.rt11.ml, so that string showing up in a DNS log somewhere is an indicator that one of these packages were installed.
Lapsus$ Strikes Again, Again
The loose collection of hackers knows as Lapsus$ have potentially scored breaches at both Microsoft and Okta. KrebsonSecurity has a bit more information about the group and the Microsoft case. The group seems to be doing some of their coordination over a Telegram channel, which is open for anyone to join. The group boasted of their exploits on this channel, and Microsoft respondents found and cut their access during the data exfiltration. A 10 GB file has been released containing partial source to Bing search, Bing Maps, and Cortana.
The Okta situation is even murkier, as the released screenshots indicate access back in late January. The access seems to have been limited to a administrative portal, via a Support Engineer’s account. Okta has gone out of their way to assure everyone that there was no actual breach, and the rogue access was quickly dealt with. This seems to be a bit disingenuous, as Lapsus$ was after companies making use of Okta services, and didn’t need to compromise their systems any further. Okta provides access management for other companies, like Cloudflare. There’s likely been some quiet infiltration happening in the months since this happened.
Linux Gets More Random
[Jason Donenfeld], kernel hacker and main developer of Wireguard, has worked recently on the Linux random number generator. A few changes landed in release 5.17, and more are coming in 5.18. He was kind enough to write up some of the interesting changes for our education. He considers his most important contribution to be documentation. I can confirm, among the most frustrating problems a programmer can face is when the documentation has bit-rotted to uselessness.
One of the biggest user-facing changes was the attempt to unify /dev/random and /dev/urandom. We say attempt, because this change caused multiple failures to boot on the kernel’s test setup. Apparently some architectures, specifically when being virtualized, have no method of generating high quality randomness during boot. There next killer feature is the new add_vmfork_randomness() call, that allows a newly cloned virtual machine to request a regeneration of its randomness pool. Without a call like this, the first few random numbers generated by the kernel after a VM fork would be identical — obviously a problem.
Internally, the randomness code retires the venerable SHA-1 algorithm, replacing it with the more modern BLAKE2 hash function. An interesting advantage is that BLAKE2 is intentionally a very fast algorithm, so the kernel gains a bit of performance when generating random numbers. The rest of the changes delve into more complicated cryptography considerations. Definitely worth reading if you’re interested.
Western Digital NAS RCE
We’ve covered plenty of vulnerabilties and attacks in NAS boxes from QNAP and Synology, but this week it’s Western Digital getting in on the action. Thankfully it’s research from NCC Group, demonstrated at Pwn2Own 2021, and fixed in a January update. This Remote Code Execution (RCE) vulnerability is in how the NAS handles the Apple Filing Protocol (AFP), and was actually a problem in the Netatalk project. AFP supports storing file metadata as a separate file, for the sake of compatibility. These files are in the AppleDouble format, are take the name of their parent file, prepended with a ._. The kicker is that these files can also be accessed using the Windows SMB protocol, allowing direct manipulation of the metadata file. The function that parses the metadata file does indeed detect a malformed data structure, and logs an error to that effect, but fails to fail — it goes ahead and processes the bad data.
This continue-on-error is the central flaw, but actually building an exploit required a data leak to defeat the address layout randomization in place on the device. A simpler first step was to write memory locations into the AppleDouble file, and use SMB access to read it. With the leaked address in hand, the full exploit was easy. This would be bad enough, but these devices ship with a “Public” share world-accessible over SMB and AFP. This configuration makes it a pre-auth RCE. And this demonstrates the purpose of Pwn2Own — it was discovered, made the researchers a bit of money, and was fixed before the details were made public.













[OAuth] “… It’s a great protocol…”
No, it’s not. It’s a Rube Goldberg, and as we see, a bunch of mishaps waiting to happen.
The driving force is the Big Ones, who want to stick their proboscis into every little life stream of the Internets.
Me? I use passwords. For so many reasons. Each site its own password.
Bah.
Agree. Each site one uses, needs it’s own username/password. Also the user should use a ‘different’ password for each site too. Use a local password manager on your system (not in the cloud) to keep track of them all. Simple and a bit more secure.
sure, but add a 2nd factor for authentication if possible. It’s not 100% foolproof but it increases security bigtime against opportunistic hackers/malware. FIDO2 is the most secure if your cloud service of choice supports it.
2FA mostly protects from somebody else logging in to your account from their PC. If they own your PC it’s game over anyway.
>Facebook
>trusted third party
Sorry? No!
You can trust facebook to abuse you in every way they can as long as it generates profit for them.
not quite, I think they would abuse you on general principles, even if they didn’t make money out of it..
I recently had cancer so I Joined a sort of self help group for cancer sufferers and their friends and family.
My outcome is definitive so I’m not suck up in the air wondering if I am going to survive or for how long however for many members they’re positivity desperate to prolong their life against near impossible odds. It’s absolutely gut wrenching.
After joining this group I saw so many ads for false cures (snake oil) or treatments for cancer. And I am sure some desperate cancer sufferers would part with lots of their money just for the glimmer of false hope and of course facebook gets their cut of the money for the advertising.
I though that was the lowest and most discussing thing I could ever imagine a social media organization do.
But then more recently facebook has been targeting me with ads advertising dating sites that are suggesting (in the facebook ad) that: Ukrainian women are attracted to older 40+ western men.
This when the reality is Uranian woman (and often their children) are fleeing war and leaving their companions, husbands and sons behind to fight the war.
This can only be described as exploitation and in my opinion at least, one the the very lowest levels of exploration.
I’ve gotten spam from “Ukrainian women”. Looking for a husband. But they’re no different from previous spam, except they are now Ukrainian.
ROB, that’s rough mate, look after yourself. Cancer support groups aside, remember back in the day when special-interest groups had their own forums? PHPbb made it (relatively) easy to set up. Unlike facebook, user posts were properly indexed and searchable. Ads were at the discretion of whoever set up the forum, i.e, a fellow enthusiast.
Now most of that is gone, and what remains is a hollowed-out, scam ridden husk that the facebook maggots have eaten the guts out of. It’s a damn shame.
I’m all good, even some improvement.
I have run several forums over the years. Now days it’s just too much effort keeping up with the moderation.
And that’s not member moderation, the vast majority of members conduct themselves in a respectable manner if not an acceptable manner – everyone has a bad day here and there.
The time consuming moderation that makes you throw in the towel and close the forum site is the endless link spammers (seo). Some will even hack the site to avoid moderation. Multi-site automated systems work for a while then they’re useless as spammers find away around them.
And then there the fear that someone will put up entirely offensive material or even worse child abuse material which would very quickly bring a lot of undesired attention from law enforcement.
I would love to be able to post simple schematics here on this site but you can’t even embed a picture from hackaday.io, once you could embed a picture from anywhere like even xkcd. So the team here has the same problem to deal with and we all suffer as a result.
It’s sad that we can’t even post a schematic as that’s the actual international “language” of electronics.
You would have thought that generating random numbers would have been fixed in 2022.
Don’t all (modern?) processors have a built-in hardware random number generator?
Random number generation is also a part of the TPM modules.
Problem is, can you trust them?
It’s certainly not trustworthy if it’s made by any US based company, as they have laws about building in backdoors, and forcing companies to lie about their products.
Simply the existence of that law makes all US companies untrustworthy. I do not know if a company is being extorted by such a law, and the only sensible way is to distrust them all.
The only way I can see a TPM module being trustworthy is if it’s completely FOSS. Free from commercial interest, out of reach of government meddling and source code reviewable to be scrutinized by “the community”.
My main board has an (empty) header for a TPM module. I hope to be able to use mainboard without TPM as long as possible but these days between the Intel Management Engine and AMD Secure Technology (formally called Platform Security Processor), I really feel that is already a defeated effort.
The irony is that these “trust platforms” are being created by companies we don’t trust because they work under a government we don’t trust.
Got a legit reference to the specific law you are talking about? I’m sure just about every government does this sort of thing but never heard of specific laws that try to legitimize it. Otherwise it just sounds like you have an agenda to grind with the US gov without substantiation.
RE: LINUX GETS MORE RANDOM
I wonder why the BLAKE2s hash function was chosen over BLAKE3?[1][2][3] Right at the top of the BLAKE2 homepage it says this: “CONSIDER USING BLAKE3, faster than BLAKE2…” (That’s a big understatement, see below.) Also on the BLAKE2 homepage it says this: “BLAKE2s is optimized for 8- to 32-bit platforms and produces digests of any size between 1 and 32 bytes”. Hmmm, what about 64-bit platforms? BLAKE3 was announced on 09-January-2020, so it’s not fresh out of the oven.
I read [Jason A. Donenfeld]’s write-up on his Linux kernel changes [4], there is no explanation why BLAKE2s was specifically chosen over other hash functions to replace an obviously weak LFSR. Plus, there’s no mention of BLAKE3 at all! There is probably a good reason BLAKE2s was chosen, but it’s not obvious to me. Then again, I’m a relative lay-person when it comes to this subject.
On the BLAKE3 GitHub page it says this:
BLAKE3 is a cryptographic hash function that is:
– Much faster than MD5, SHA-1, SHA-2, SHA-3, and BLAKE2.
– Secure, unlike MD5 and SHA-1. And secure against length extension, unlike SHA-2.
– Highly parallelizable across any number of threads and SIMD lanes, because it’s a Merkle tree on the inside.
– Capable of verified streaming and incremental updates, again because it’s a Merkle tree.
– A PRF, MAC, KDF, and XOF, as well as a regular hash.
– One algorithm with no variants, which is fast on x86-64 and also on smaller architectures.
On the BLAKE3 page there’s a bar-chart comparing BLAKE3’s speed in MiB/s with other popular hash functions (AWS c5.metal [5], 16 KiB input, 1 thread). BLAKE3 runs at 6,866 MiB/s versus BLAKE2s at a poky 876 MiB/s. That makes BLAKE3 784% faster than BLAKE2s (Wow!)
I doubt there is an licensing problem with BLAKE3. Straight from the BLAKE3 page:
[BLAKE3] Intellectual property
The Rust code is copyright Jack O’Connor, 2019-2020. The C code is copyright Samuel Neves and Jack O’Connor, 2019-2020. The assembly code is copyright Samuel Neves, 2019-2020.
This work is released into the public domain with CC0 1.0. Alternatively, it is licensed under the Apache License 2.0.
* References:
1. BLAKE (hash function)
https://en.wikipedia.org/wiki/BLAKE_(hash_function)
2. BLAKE2 — fast secure hashing
https://www.blake2.net/
3. GitHub – BLAKE3-team/BLAKE3
https://github.com/BLAKE3-team/BLAKE3/
4. Random number generator enhancements for Linux 5.17 and 5.18
by Jason A. Donenfeld, 2022-03-18
https://www.zx2c4.com/projects/linux-rng-5.17-5.18/
5. Now Available: New C5 instance sizes and bare metal instances
by Julien Simon | on 18 JUN 2019
https://aws.amazon.com/blogs/aws/now-available-new-c5-instance-sizes-and-bare-metal-instances/
I suspect the kernel is trying to be very conservative about introducing new crypto. Give it another 5 years, and Blake3 might be considered.
Yep, with encryption it’s always always always a case of guilty until proven innocent… multiple times. No matter how good the provenance, the sexiness of the math, or the speed or novelty of the approach, assume it’s weak and easily broken, if it survives a couple of years of postgrads picking at it, assume it’s weak-ish and breaking it isn’t that hard, if it survives a few more years and has been bombarded by high caliber doctorates, then assume it’s not all that bad… etc.
Some of my work at Mozilla involved working on Firefox’s primary browser chrome – ie, the main UI elements involved in basic navigation of the web: navigation toolbar, url bar, tabs, main menu, primary security indicators, etc. *Everything* we did there, no matter how seemingly insignificant, had to be considered for how it could be spoofed (faked) or otherwise abused by web content.
And web content can of course be built to look like anything. And it knows a lot about the environment it’s running in. There’s enough data exposed directly or indirectly to fingerprint you with scary good accuracy worldwide without the need for anything like cookies, so figuring out what browser/OS version combination you’re running is trivial. The attacks can range from spoofing the entire UI (like mentioned in this article), to spoofing a seemly harmless secondary information element.
The example here isn’t new, but it’s a particularly good example of it. I argued for years to disallow (most) web content to open windows without browser chrome – there’s legit arguments for & against, sadly. And we got some way – my memory is a bit fuzzy on the details now, but the attack example here only has examples for Chrome, so maybe Chrome allows this while Firefox requires at least a basic url bar to show.
Designing/coding around this type of attack was always a huge challenge, often involving subtle tricks, while being mindful that it had to be noticeable by anyone using the browser. So there’s a lot of design decisions that may not seem like much, or may not necessarily make much sense, or seems needlessly over-engineered, or even appears under-engineered for the attention it gets, or you wonder why it took a year of work to change something – a lot of the times, it’s because of this.
Fun historical side-step: Mozilla’s use the term “browser chrome” is how Chrome got it’s name. Before Chrome, Google was paying some of their engineers to work with Mozilla on Firefox. There was some overlap, but essentially Google pulled them off to build Chrome. When Chrome was announced, the product name was a bit of a surprise at Mozilla at the time – cos it was our jargon (inherited from Netscape, along with other stuff like the numerous Ghostbusters references). Which became amusing to us when Chromecast was announced years later – the story we heard at the time was that the Chrome team had no idea that name “Chromecast” was going to be used, and weren’t very happy about it.
The linked ArsTechnica article points to the wrong source.
Apparently the idea was already one year old as stated in this (italian) newspaper article:https://www.repubblica.it/tecnologia/2022/04/12/news/tre_ricercatori_italiani_hanno_scoperto_come_neutralizzare_lautenticazione_a_due_fattori-344196332/?ref=RHVS-VS-I302503236-P7-S5-T1
The security researchers that actually invented thee technique published their findings in april 2021 (https://link.springer.com/article/10.1007/s10207-021-00548-5). When contacted by the authors via twitter, mr.d0x blocked their account.