
If you are a Star Trek fan, you’ll probably remember the phrase “You have to learn why things work on a starship.” The truth is, in most episodes, knowing how to override another ship’s console or make gunpowder didn’t come in very handy, but boy when it did, it really saved the day. Linux is a lot like that. There are a few things you probably don’t need to know very often, but when you do need to know, it makes a huge difference. In this particular post, I want to look at an odd use of the fork system call. For many purposes, you’ll never need to know this particular irregular use. But when you need it, you are really going to need it.
This is actually based on an old client of mine who used Unix to run a massive and very critical report every day. The report had a lot of math since they were trying to optimize something and then generate a lot of reports. In those days, the output of the report was on old green-bar paper on a line printer. The problem was that the report took something like 14 hours to run including the printouts. If someone discovered something wrong, there was no time to run the report again because the next day’s report would have to start before the second run would finish.
The client had a bunch of Windows programmers and — at that time — there wasn’t anything really analogous to a real fork call in Windows. I looked at the code and realized that probably most of the code was spending time waiting to print the output. The computer had multiple CPUs and there were multiple printers, but that one program was hanging on the one printer. There was a lot of data, so writing it to a database and then running different reports against it wasn’t a great option. The answer was to use the power of fork. With a change in the code that took less than 30 minutes, the report ran in five hours. They were very pleased.
So how did I do it? The answer lies in how fork works. Just about every time you see a fork, you see some sort of exec call to start a new program. So if you think about fork at all, you probably think it is part of how you start a new program and, most of the time, that’s true.
What does fork() Do Exactly?
The call, however, does something very strange. It actually copies the entire running process into a new process. It then runs the new process. Of course, the original process is running, also. Normally, when you see fork, it looks like this:
int childPID; childPID = fork(); if (childPID == 0) exec....; /* load child program and run that */ /* the parent only gets here with childPID set to the new process' PID */ ...
 In other words, the return value for
In other words, the return value for fork is zero for a child process and something else for the parent process. Some early Unix systems really copied everything in the running process. However, that’s really inefficient, especially when most of the time you just immediately load a new program.
Modern systems use COW or Copy On Write semantics. That means the new process gets what amounts to a pointer to the original process memory and it only copies relatively small amounts of memory when the child or parent program makes changes to that region of memory. This is good for things like instruction spaces that shouldn’t change anyway since very few people still write self-modifying code. That means that right after a fork call, both parent and child see the exact same data, but any changes they make will not reflect to the other side.
Parallel Processing Made Easy
For my client’s long report, the program was mostly I/O bound. However, each report also had some pretty hairy math to go along with it, in addition to all the math required to get to the point that each report could execute. Instead of executing all of it in one process, I broke the program up into multiple pieces. The first piece did as much math as it could that applied to nearly everything. Then the program called fork a bunch of times and each child started a report which did a little more math just for itself and claimed a printer to write the output.
Since the CPU had multiple processors, everything got sped up. Report three didn’t have to wait for reports one and two to complete. Everyone was able to drive the printers at once. It was an overall win and it took almost no time to make this fix.
Granted, not every problem will allow for a fix like this one. But giving each report process a memory copy of the data was very fast compared to reading it from a file or database. The data didn’t change after the reports started, so real memory consumption wasn’t too bad, either.
An Example
So is it really that simple? It is. The only problem now is that with modern machines, it is hard to find a simple problem to demonstrate the technique. I finally settled on just doing something simple, but doing lots of it. My made up task: fill a really large array of double-precision floating point numbers with some made up but predictable data and then find the average. By really large I mean 55 million entries or more.
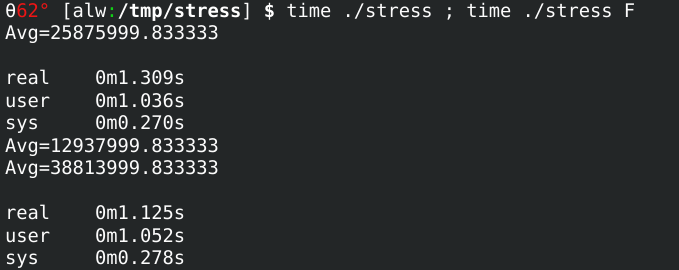 I created a program that can do the job in two ways. First, it just does it in the simplest way possible. A loop walks each item in the array, you add them up, and you divide at the end. On my machine, running this a few times takes an average of about 458 milliseconds — using the
I created a program that can do the job in two ways. First, it just does it in the simplest way possible. A loop walks each item in the array, you add them up, and you divide at the end. On my machine, running this a few times takes an average of about 458 milliseconds — using the time command to figure that out.
The program can also accept an F parameter on the command line. When that is in effect, the setup is the same, but a fork creates two processes to split the array in half and find the average of each half. I didn’t want to have the child communicate back to the process, but that is possible, of course. Instead, you just have to read the two averages, add them together, and divide by two to get the true average. I didn’t want to add the overhead to communicate the result, but it would be easy enough to do.
The time for the fork version to run? About 395 milliseconds. Of course, your results will vary, and while 60 or so milliseconds doesn’t seem like a lot, it does show that having two processes working together can allow multiple cores to work at the same time.
The larger the array, the bigger the time savings. For example, setting the size to 155,256,000 showed a savings of around 150 milliseconds. Of course, these timings aren’t scientific and there are a lot of factors to consider, but the data clearly shows that splitting the work between two processes works faster.
The Code
The code is straightforward. The work isn’t hard, there’s just a lot of it.
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/wait.h>
// compile: gcc -o stress stress.c
// run: time stress
// time stress F
#define SIZE 55256000 // how big is the array?
double bigarray[SIZE];
// The process routine will go from llimit to ulimit
// For the single case, that's everything
// For the child case we will split in half
unsigned int ulimit=SIZE;
unsigned int llimit=0;
double total; // running total
// Load up the array with some bogus data
void setup(void)
{
unsigned int i;
for (i=llimit;i<ulimit;i++)
{
bigarray[i]=i/3.0f;
}
}
// Average the range defined by llimit and ulimit
void process(void)
{
unsigned int i;
unsigned int n=ulimit-llimit;
total=0.0;
for(i=llimit;i<ulimit;i++)
{
total+=bigarray[i];
}
printf("Avg=%f\n",total/n);
}
int main(int argc, char *argv[])
{
int dofork=0;
int pid;
if (argc>1 && (*argv[1]=='f' || *argv[1]=='F')) dofork=1; // f or F will trigger a fork
setup(); // load array
if (!dofork)
{
// single case
// ulimit and llimit are already set
process();
exit(0);
}
else // forking here
{
if (pid=fork())
{
// parent -- adjust ulimit
ulimit=SIZE/2;
process();
waitpid(pid,NULL,0); // wait for child
exit(0);
}
else
{
// child -- adjust lower and upper limit
llimit=SIZE/2;
ulimit=SIZE;
process();
exit(0);
}
}
// we never get here
}
Why Things Work on a Starship
Now that you know how fork really works. Well, sort of. There are plenty of nuances about what handles get passed to the child and which don’t. And, as I said, you won’t need this very often. But there are times when it will really save the day.
If you want a higher-level look at multitasking, try an older Linux Fu. Or, check out the GNU Parallel tool.














I must be getting old, the number of times I used `fork()` like this far outshadows the number of times I used it combined with `exec()` 😅 It’s what we did before multithreading was common place.
Out of curiosity, when did threads (with shared memory, vs. standalone processes with independent memory) become a thing in *Nix, if they weren’t always there?
I’ve always found it odd how the pthreads library feels like it’s been bolted on, and I get the distinct impression that merely using fork() and various forms of IPC was the way to do parallelism “back then”.
Posix Threads (pthread) have been standardized in 1995, so I guess not for long?
https://en.wikipedia.org/wiki/Pthreads
Exactly right. And recall that was the era of proprietary closed source Unix variants, so pthreads was often an extra-cost software add-on.
Not for long? Thats 27 years ago…
I dont even remember what distros were around back then? What computer i had?
Also, few computer stuff from then still is around or relevent
Slackware, redhat and debian 1.0 – I tried all three on a 486 :)
Threads, or “lightweight processess” became commonplace in the 1980s, possibly earlier, but there was no standard way to do it across operating systems. There are some languages that have built in support for threading, though sometimes they call it tasking (see Ada). The ideas for fork and join, along with inter-thread synchronization, single vs multiple cores (true parallel vs sequentially alternating execution) transparency, and automatic parallelization (see Fortran) have been banging around since the 1970s when I was in college.
Even without OS support, people managed to support multiple threads on uniprocessor systems (I wrote my own for MS DOS, the Atari ST (TOS), and a few others, but they weren’t portable. There were also commercial products that provided this to software developers.
Eventually, things settled down and it became a common thing supported by lots of systems, and POSIX threads became available on lots of systems. Still, there is, or was, a variety of other threading libraries and interfaces in use.
Yep. This is not an odd usage. It’s a completely standard usage that anybody with a few months Unix programming experience should be very aware of, already.
I actively have code in production right now that does exactly this too. In PHP of all languages even. Super reliable and bullet proof.
Hey Al! It looks like there was a bit of html translation that occurred when your code sample was added to your article. Some people might find this a little confusing. Nice article btw!
Amdahl’s law: “the overall performance improvement gained by optimizing a single part of a system is limited by the fraction of time that the improved part is actually used”.
Then there was the other guy who showed that adding more than the optimal number of parallel processes to the program starts to slow you down even if you had the CPU cores to run them, because communication and coordination between the tasks starts to eat up computing time. For many everyday problems, the optimum number of parallel units in terms of both laws is surprisingly low, somewhere around 10-20.
Do you have any links to back up what you say?
The observed behavior by myself and phoronix is that adding jobs beyond the # of cores does provide a speedup because the pipelines stay full all the time. If the # of jobs equals the # of cores then the pipelines will not stay full.
The kernel can only optimize IO that it knows about, so throwing as many requests as possible to the kernel as fast as possible is good because it makes more opportunities for optimization. Full pipelines!
The slowdowns you are talking about were fixed in the Linux kernel decades ago when oracle etc started using Linux as a platform for their servers. We run thousands of processes on servers with terabytes of ram and performance is awesome.
Sorry, I’m trying to remember what the name of the guy was, but I’m coming out short.
They were testing algorithms on machines up to 128 cores and found that for many tasks they started getting diminishing returns and then adverse returns after about 24 cores.
> We run thousands of processes
Yes, but independent processes. The problem was about splitting a single task N ways, and the amount of communication and logistics that needs to happen to coordinate an N-way collaborative task.
I can remember way back in the day, before kernel modules, frequently compiling the Linux kernel. This took a long time in those days so we were always seeking optimizations. Once two and four core systems became available we started experimenting with compiler threads. To this day I remember the “formula” we found to deliver the shortest compile times. Threads = CPUs x 2 +1.
Now I wouldn’t try this today on systems with 16,32,64 cores etc. But for the 2 and 4 CPU systems of the day, it proved to consistently be the best optimization for fastest compile times.
My experience is that it depends. The high-CPU and (perhaps) high-memory-bandwidth tasks tend to work best if you keep to the number of CPU threads. Tasks involving disk or network traffic can take more threads or processes. But it requires testing on the system in question.
On a free Google Cloud e2 instance I found one graph generator was suitable (despite the two threads, it was on one core), but we could use 16 threads for the requests to as many nodes for data. However, that number was smaller when it was an f1-micro, because that had less RAM. Adding more RAM let us avoid eviction of the database files.
Similarly for PostgreSQL we tend to set the max active processes such that it uses the number of threads as the limit for query handling processes in total (not considering other background processes), and a max parallelism such that a single process can spin up as many backend processes to fill all cores, but not threads. This might not be fully optimal if there is disk access, but but in that case it is likely to be the bottleneck anyway.
To this I will add: measure it! Just because something “looks” like it has N-way parallelism doesn’t mean splitting up even more won’t be a win. Sometimes it’s OK to stall one core waiting on another just so you can use both L1 caches. The L1 cache is very approximately 0.5 nanosecond memory, but there isn’t a whole lot of it. More cores -> more caches -> more speed.
To be clear – I’m not disagreeing with Dude, just mentioning a dirty trick I’m exploited a few times. :-)
Even though single core processors hardly exist anymore for some 10+ years there are still fare to many programs who do not manage to make proper use of them. I bought a Ryzen 5600G a few months ago and whenever my PC is feeling slow and I look at the task manager, then 11 threads of this 6 core 12 thread PC are idling.
Adding a -j12 to make can help a lot when compiling stuff, but I do not compile much beyond uC stuff, which usually is finished within a second or two anyway.
Just had a look at https://www.cpubenchmark.net/high_end_cpus.html and I find it worth mentioning that there now is a processor that has past the 100 000 passmark rating. It’s a 64 core processor, and even if I had it,it would probably make no difference for me because of single thread performance which has not been able to keep up with moore’s law for quite a few years now.
Moore’s law has nothing to do with thread performance anyhow. It’s about the most economical size of a silicon chip, measured by how many transistors would fit in it.
Calling it ” Moore’s Law” at this point is just silly. It never was a “law”, just an “observation” and not a very good one. Expecting it to go on forever is magical thinking.
You are both entirely right and I had a big brainfart in writing it down in that way.
But the point I wanted to make still stands. single thread performance has mostly plateaued and although there still can be some performance to be gained in that area, the way forward is making more use of multiple threads and a lot of software is lacking in that regard and it leaves the hardware just idling.
A lot of problems can’t be parallelized, or only with great complexity. u
I agree completely. Modern commercial software and Operating Systems are garbage at parallelism and so are most dev environments. Linux isn’t a whole lot better with some underlying key optimizations yet to be made due to the huge changes they would require.
Also universities are not teaching (very well anyway) programming methods that result in highly optimized parallelism in the final code.
IMO is because we really haven’t figured out how to do it well yet. Again, IMO, it will require moving beyond C++ and other common languages and into new development environments and system libraries designed to maximize parallelism and core usage. Unfortunately this is on direct conflict with green-o-mania and the push to lower power consumption on everything. Like most manias this is based on stupid assumptions. In this case the idea that peak power consumption (max cores used) is worse than area under the curve power consumption. In other words “OMG the system peaked at 450w power consumption” causes panic while no one notices that the “optimized” system, while only peaking at 183w took 5x as long to run and had a higher total watt/hours consumed.
The code isn’t rendering correctly due to some HTML confusion.
But at least the curley brackets are in the right place!
Fixed, I think. There is something in WordPress where sometimes you do an edit and it does this. I know any undo in the document does it. So somewhere between me putting it in and it getting published, someone did one of the magic things that makes WordPress go crazy on it and there you are… Sorry ’bout that.
forking is still the linux way of doing threads. A good practice is to use async for I/O loads and forks for CPU load. I nowadays work in a Windows Copmpany and they use Threads for I/O as well, wich is not fine.
The speedup is also limited see Amdahl’s law
https://en.wikipedia.org/wiki/Amdahl%27s_law
Using threads for I/O is perfectly fine since they’re so lightweight, although not as performant as asynchronous procedure calls or overlapped I/O.
In my opinion that heavily depends on how much memory the thread has to copy and how you share it and do locking. With massive I/O (e.g. webservers apache vs ngix) you might enter a threshing hell or need to do a a lot of clever usage of caches. Also lockfree implemenations are more heavy then “just” use normal stuff. Mutexes and semaphores consume memory as well. Then it depends on your threading model. If it is userspace you might get away with it. Memory pooling might also be a good idea in such cases. In my opinion doing I/O async is so much more easier and lightweight. With syntactical sugar like async it also is not a callback “hell” But well I accept your answer as tthat is what my colleges tell me all the time. C++ would not implement async in threads if that would hurt anyone. (Well that is not true in all the cases as it, depending on the implementation, has a threading pool)
Depends highly on the kind of I/O.
If you have, say, a 4 core machine having just 10 000 connections, a thread for each connection, having it’s own stack of maybe 2 MB, is gonna use up 20 GB of memory, just to keep track of the connections.
Using a poller-thread and asynchronously serving connections with a worker-pool of 4 threads, is using 5 threads * 2 MB = just 10 MB of memory.
When serving fewer, high-demand connections where bandwidth, disk or CPU-usage is the limit, yes, threads will be just as good as an async workerpool
I like ‘fork’ing as well, whenever there’s opportunity. But the ‘child’ processes eat up all my resources. ( read ‘groceries’.
So the server has 32 cores and 100000 mips and it’s still not enough to run the programs in those 1985 programming textbooks and yet somehow they ran great on a Sun 3.
My ‘child’ processes also eat up my time and money…
Use more interprocess protection :)
I had to port a big Unix server application to Windows NT back in the 90’s. The lack of a fork() in Windows caused me all sorts of grief. Windows had “spawn” which was like a combination of fork() and exec(). But one particular program would listen for connections and fork() for each connection with no exec(). I looked at how Cygwin (then called gnuwin32) implemented fork() on Windows and it was pretty horrible. So I wound up splitting the program into two pieces… a listener and a runner.
The cygwin answer was necessary but yes… Truly ugly. I had the same experience.
I think this article should have been titled “how to use a hammer on a star ship” ie it is much better – and has been for many decades – to write your program as a proper multithreaded one in the beginning…
It very much depends. One doesn’t go designing a warp core into a navigation beacon. It excessively complicates the beacon, and introduces unnecessary failure modes, including opportunities for sentience.
The original use, with different reports generated for different printers, is a good use case for fork(). But in the array averaging example, it would be a lot simpler to just use openmp which is built into modern versions of gcc. You just precede the for loop that fills the array with:
#pragma omp parallel for
and the for loop that sums up the values with:
#pragma omp parallel for reduction(+ : total)
and then give a -fopenmp (or equivalent) option to the compiler. The result is neater code, with automatic adding up of the totals across all the threads without having to write any communication code between threads, the compiler/library takes care of figuring out how many threads to start on the specific processor, and the code will have backwards single-thread compatibility with compilers that don’t support openmp. (The downside of the openmp appraoch here is that if some cores finish their part of filling the array, they will idle until the other cores finish this part of their task before starting on the summing.)
People that can do this stuff never cease to amaze and put me in awe. Rocket science as far as I am concerned.
I guess this gives new meaning to “Stick a fork in it, it’s done”
There’s nothing odd about using a system call to do what that system call is designed to do.
Well theres nothing ‘hack’y about most of the stuff on hack a day. So … par for the course really ….
Most Linux libraries (foremost glibc) have been using clone/clone2/clone3 instead of fork() for a very long time.
True, though don’t forget heat dissipation capacity.
A lot of the chip design innovation is focused on mobile processors which might exceed their thermal budget and have to throttle before they complete the task at the higher wattage.
…and, of course, there’s always those idiot web developers who love to just assume they can guzzle sustained CPU ’til the cows come home because nobody has passed any kind of law to put the cost of burning customer CPU time back on the companies.
Ugh. I forgot WordPress says “replying to…” but doesn’t actually record that information if you have JavaScript disabled.
I was replying to https://hackaday.com/2022/04/21/linux-fu-an-odd-use-for-fork/#comment-6464093