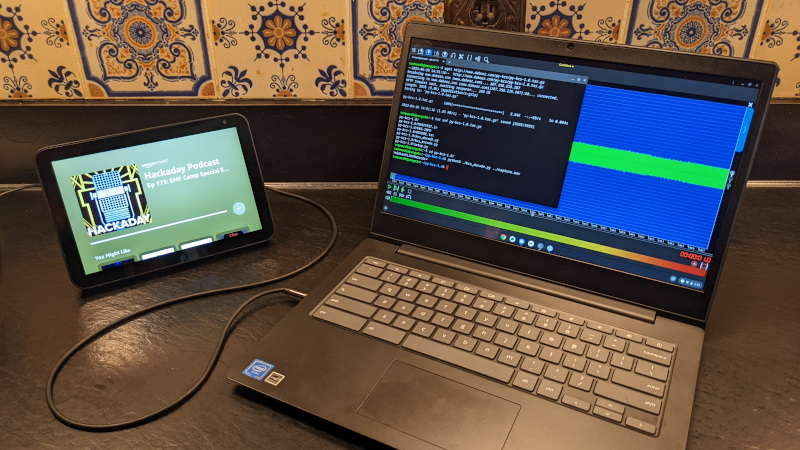
When Elliot and I record the raw audio for the weekly podcast, it’s not unusual for us to spend the better part of two hours meandering from topic to topic. During one of these extended gab sessions, we wondered if it would be possible to embed a digital signal into the podcast in such a way that it could be decoded by the listener. Of course, storing and transmitting data via sound is nothing new — but the podcast format itself introduced some level of uncertainty.
Would the encoded sound survive the compression into MP3? Would the syndication service that distributes the file, or the various clients listeners will use to play it back, muddy the waters even further? Was it possible that the whole episode would get flagged somewhere along the line as malicious? After a bit of wild speculation, the conversation moved on to some other topic, and the idea was left to stew on one of our infinite number of back burners.
 That is, until Elliot went on vacation a couple weeks back. In place of a regular episode, we agreed that I’d try my hand at putting together a special edition that consisted of pre-recorded segments from several of the Hackaday contributors. We reasoned this simplified approach would make it easier for me to edit, or to look at it another way, harder for me to screw up. For the first time, this gave me the chance to personally oversee the recording, production, and distribution of an episode. That, and the fact that my boss was out of town, made it the perfect opportunity to try and craft a hidden message for the Hackaday community to discover.
That is, until Elliot went on vacation a couple weeks back. In place of a regular episode, we agreed that I’d try my hand at putting together a special edition that consisted of pre-recorded segments from several of the Hackaday contributors. We reasoned this simplified approach would make it easier for me to edit, or to look at it another way, harder for me to screw up. For the first time, this gave me the chance to personally oversee the recording, production, and distribution of an episode. That, and the fact that my boss was out of town, made it the perfect opportunity to try and craft a hidden message for the Hackaday community to discover.
I’m now happy to announce that, eleven days after the EMF Camp Special Edition episode was released, ferryman became the first to figure out all the steps and get to the final message. As you read this, a coveted Hackaday Podcast t-shirt is already being dispatched to their location.
As there’s no longer any competition to see who gets there first, I thought it would be a good time to go over how the message was prepared, and document some interesting observations I made during the experiment.
Follow the Yellow Brick Road
Now as already mentioned, encoding digital data into audible sound is by no means a new technique. There was even a time when bog-standard audio cassettes were used to distribute commercial software. So rather than reinvent the wheel and come up with some new way of converting the first part of the message into audio, I went with a true classic: Kansas City standard (KCS).

The product of a conference hosted by Byte magazine in 1975, KCS was intended to be a universal standard for storing digital data on audio cassettes. Initially designed to provide speeds of up to 300 bits per second, later variations managed to eke out slightly improved data rates at the cost of interoperability.
In the end KCS wasn’t much of a success, as individual companies seemed hell-bent on coming up with their own proprietary way of doing the same thing (sound familiar?), but it did lay important groundwork, and several encoder/decoder packages are still available today.
The initial 20 character message was encoded into a WAV file using py-kcs by David Beazley. As a spot check, I also ran the same message through a Perl implementation of KCS written by Martin Ward. Being more than a little worried that not many listeners would be familiar with a nearly 50-year-old audio format designed for cassette tapes, I added a little clue at the last minute in the form of Dorthy’s famous “Toto, I have a feeling we’re not in Kansas anymore” line from The Wizard of Oz. Finally, because secret messages always have to be played backwards, I reversed the whole thing and tacked it right onto the end of the edited episode before it went through Elliot’s final mastering script.

Note the very clear digital nature of the KCS data compared to the waveform of Dorthy’s speech. I was sure that anyone who opened this up in an audio editor would immediately recognize there was more than just noise here. But what would it look like after Elliot’s carefully crafted Podcast Perfection™ Bash script had at it?

Well, that’s different. Getting converted to stereo shouldn’t be a problem, but clearly the script came through and cleaned house during the MP3 encoding. Dorthy’s vocals are now much more prominent, which if you think about it, makes sense given the file was just run through a script designed to make podcasts sound better. But the data is now no longer a series of perfect square waves throughout, as it does a weird fade at the start. More importantly, we can now clearly see what appears to be the encoded data in the middle of the signal.
[Elliot: Compressor/limiter with a slow attack keeps our ever-changing volumes relatively constant for earbuds. And that digital audio section was waaay too loud originally. If it had started out at the average loudness, it wouldn’t have been ducked at all.]
Despite my initial concerns, the MP3 version of the sound still decoded correctly by the tools mentioned previously, so long as it was first converted into the WAV file they were expecting. Confident that the message was intact, the episode was sent off to the syndication service for it to be pushed out the next morning.
Can You Hear Me Now?
Once the podcast was pushed out Friday morning, the real fun started. Would Spotify or Google Podcasts kick it back? Would some automatic trimming on their end cut out the signal because there was too much dead air in front of it? The short answer seems to be…nobody cares. I figure it’s a bit like the dinosaur erotica on the Kindle Store; once you’ve fully committed to letting folks upload whatever they want, you have to accept there’s going to be the occasional oddball.
As far as I can tell, the episode played as expected on all the different services out there. We had a couple people email us wondering if we knew about the “weird noise” at the end of the episode, and somebody in the Hackaday Discord wisely advised headphone wearers to steer clear of those last few seconds, but that was it.
But did the message survive, and how would users extract it? For the sake of argument let’s forget that we offer a direct download of the MP3 for each podcast, since obviously that would be the most direct route. I wanted to see if it was possible to pull the message out from the various podcast services. So I set Audacity up to record from a monitor of the system audio, opened the podcast in the web players for Spotify, Google, and TuneIn, and jumped right to the end of the track.
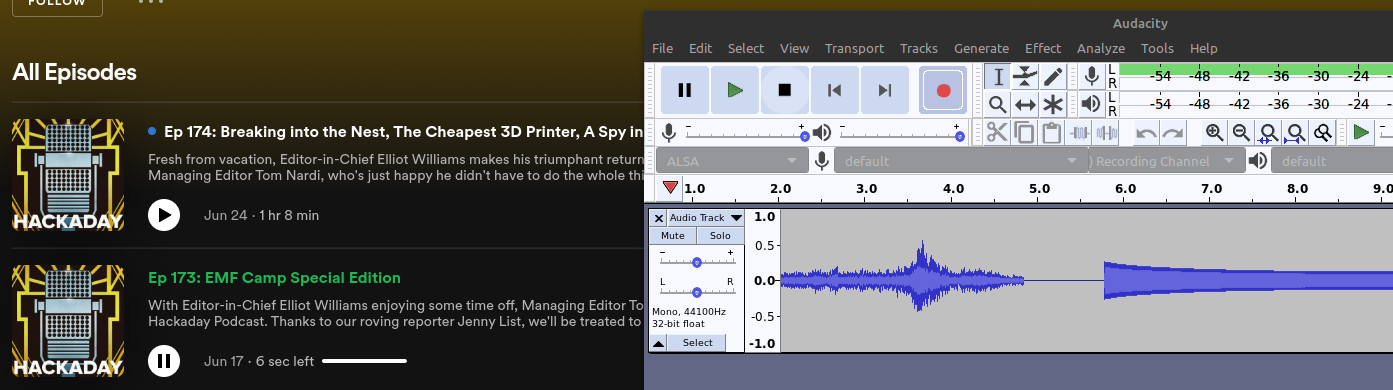
Sure enough, the audio captured directly from the web decoded properly using the KCS tools. Next I wondered if I could plug different podcast playing gadgets, such as my Pixel 4 or Echo Show into the computer, and record the audio from them directly.
Interestingly enough, this actually caused some issues. While the waveform looked the same in Audacity, py-kcs would routinely add garbage characters to the front of the intended string. Martin Ward’s Perl tool did slightly better, but would also run into the occasional error. Results were the same when recording from my Thinkpad T400 and Lenovo Chromebook. I’m not sure why this is, and would be interested in hearing from anyone who might have a theory.

That said, if you ignored the corrupt data, the appropriate message still got through. So I’m calling this one a partial win, since if you squint at the results just right, you can still move on to the next step.
The Truth is Out There
So now we have our answer. Not only is it absolutely possible to use an encoding scheme like Kansas City standard to put digital data into a podcast episode, but pulling the data back out on the receiving end is easily doable even if the listener doesn’t have access to the original MP3 file.
But what is the content of the decoded signal, and what do you do with it once you have it? Well, I never promised to tell you everything. Don’t worry though, this post should get you half-way there. After all, the intent was never to make this too difficult, it was only an experiment.
Of course, now that we know the concept is sound, the next time we hide a message in an episode of the podcast…expect to have your work cut out for you.














“ Of course, now that we know the concept is sound”
Ba-dum TSSHH!
There was probably a Software EXchange joke in there too somewhere, but I’m trying to cut down on the baudy humor.
Might wanna look at SSTV for a future version :D
(should have less issues with garbled data)
Unfortunately, sstv has an unmistakable sound most of the time. However, it would be possible to use DSP to create a low rate PSK (such as BPSK).
I believe this article uses clever DSP to hide some data inside audio.
https://lucasteske.dev/2020/05/hack-a-sat-phasors-to-stun/
Couple of years ago the Linux Unplugged podcast feature my data-over-sound library in one of their episodes, and they used it to encode a secret URL in the podcast audio. Here is a link to the episode – start listening at 00:28:00
https://linuxunplugged.com/381?t=1680
You can easily decode it with the Waver app – just open it in a tab and play the podcast in another tab:
https://waver.ggerganov.com
Theory on the garbage characters to the front of the recorded waveform file might be something to do with the ADC starting up for the MIC input / Line Input. The ADC on the phone would not be running continously as it uses juice but on startup the ADC device operation might not pull in straight away resulting in conversion errors. Eventually as you run into the waveform file the ADC internals have steadied and there are no conversion errors. High quality ADC converters never get turned off something like in a oscilloscope or DSP device but you have enough juice available. This actually maybe a way of finding when the ADC is in a good state.
There’s a delightful series of puzzles at the end of episodes for ‘Darknet Diaries’. I started down the rabbit hole but luckily reddit provided some clues/azimuth checks. There is some data as sound in at least one episode.
This is hardly a new venture – I did this 18 years ago with broadcasting a small BASIC program and image using the ZX Spectrum standard on my podcast: https://pohd-cahst.podomatic.com/enclosure/2008-08-06T12_18_30-07_00.mp3
I learned that, in order for it to work with the 56kb/s limitation of the platform, I had to convert the audio to stereo. It wouldn’t load if I converted to mono.