The idea behind Lua is a beautiful one. A simple and concise syntax offers almost all of the niceties of a first-class language. Moreover, a naive implementation of an interpreter with a giant switch case can be implemented in an afternoon. But assembly is your go-to to get decent performance in a JIT-style interpreter. So [Haoran Xu] started to ask himself if he could achieve better performance without hand-rolled assembly, and after a few months of work, he published a work-in-progress called LuaJIT Remake (LJR).
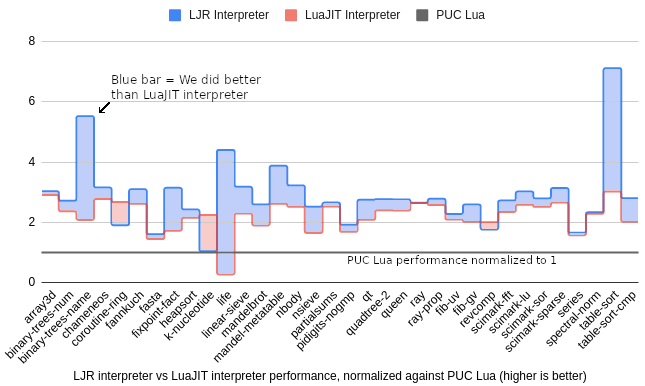
Currently, it supports Lua 5.1, and on a smattering of 34 benchmarks, LJR beats the leading fastest Lua, LuaJIT, by around 28% and the official Lua engine by 3x. [Haoran] offers a great explanation of interpreters that provides excellent background and context for the problem.
But the long and short of it is that switch cases are expensive and hard to optimize for compilers, so using tail calling is a reasonable solution that comes with some significant drawbacks. With tail calls, each case statement becomes a “function” that is jumped to and then jumped out of without mucking with the stack or the registers too much.
However, the calling convention requires any callee-saved registers to be preserved, which means you lose some registers as there is no way to tell the compiler that this function is allowed to break the calling convention. Clang is currently the only compiler that offers a guaranteed tail-call annotation ([[clang::musttail]]). There are other limitations too, for instance requiring the caller and callee to have identical function prototypes to prevent unbounded stack growth.
So [Haoran] went back to the drawing board and wrote two new tools: C++ bytecode semantical description and a special compiler called Deegen. The C++ bytecode looks like this:
void Add(TValue lhs, TValue rhs) {
if (!lhs.Is<tDouble>() || !rhs.Is<tDouble>()) {
ThrowError("Can't add!");
} else {
double res = lhs.As<tDouble>() + rhs.As<tDouble>();
Return(TValue::Create<tDouble>(res));
}
}
DEEGEN_DEFINE_BYTECODE(Add) {
Operands(
BytecodeSlotOrConstant("lhs"),
BytecodeSlotOrConstant("rhs")
);
Result(BytecodeValue);
Implementation(Add);
Variant(
Op("lhs").IsBytecodeSlot(),
Op("rhs").IsBytecodeSlot()
);
Variant(
Op("lhs").IsConstant(),
Op("rhs").IsBytecodeSlot()
);
Variant(
Op("lhs").IsBytecodeSlot(),
Op("rhs").IsConstant()
);
}
Note that this is not the C keyword return. Instead, there is a definition of the bytecode and then an implementation. This bytecode is converted into LLVM IR and then fed into Deegen, which can transform the functions to do tail calls correctly, use the GHC calling conventions, and a few other optimizations like inline caching through a clever C++ lambda mechanism. The blog post is exceptionally well-written and offers a fantastic glimpse into the wild world of interpreters.
The code is on Github. But if you’re interested in a more whimsical interpreter, here’s a Brainf**k interpreter written in Befunge.














Python is useful for code which does HTTP requests, for everything else C and makefiles do good enough job.
I always wondered if one could write a Lua (or whatever) interpreter in Rpython and use the pypy toolchain to create a decently fast JIT from it.
(As far as I understood it, thats how pypy works. They created a python interpreter in a restricted Python subset (RPython) and have a Python toolchain, that creates a compiled JIT for that Interpreter.)
“and a few other optimizations like inline caching through a clever C++ lambda mechanism. ”
Inline caching is what’s providing the speedup, according to the post. The underlying JIT compiler isn’t actually faster (unsurprising, if it’s hand-written assembly) it’s just “close enough,” and the fact that you can easily add optimizations in a high-level language is what adds value.
[[musttail]] seems pointless to me. modern compilers with modern function linkages already do a great job at limiting function call overhead. if your function is trivial like int add(int a, int b) { return a+b; } then almost always it will become simply “add return_reg, parm_reg1, parm_reg2; branch linkreg”. try it yourself with gcc -S -O. unnecessary register saves go away, and stack base manipulation also goes away. parms and return values are all in registers for common types. if your function is bigger, has function calls in it or needs stack space or uses more registers, then i assure you: it is well worth the meager cost to save and restore registers at the edges of the function.
i point this out because there’s *STILL* this fetish for meditating on procedure call overhead. Guy Steele’s “Debunking the “expensive procedure call” myth or, procedure call implementations considered harmful or, LAMBDA: The Ultimate GOTO” was published in 1977! it took a while for compilers and linkages to catch up to the dream of that paper — and there are still niche environments where they fall short — but for most of us the expensive procedure call is just lore from our fathers.
meditating on procedure call overhead has all sorts of insane downstream effects — C++, for example, puts a ton of emphasis on the fact that you can have an infinite number of wrappers with no cost so long as you use inline templates pervasively. the problem is two-fold: first, it is very expensive because C++ hides a ton of semantically meaningful transitions in innocent-looking type logic, which *are* expensive. and second, because the resulting code is itself unreasonable-about. the cheap procedure call is a tool to help us be expressive but by meditating on the cost of the procedure call (by insisting it can be eliminated with inlining), they made excuses to make it *LESS* expressive. because they’ve bent over backwards to avoided mythical procedure call overhead, they’ve patted themselves on the back for a job well done while they’ve actually accepted a ton of other overhead. including the worst overhead of all: unclarity.
anyways, that’s my nit. optimizing switch/case isn’t that hard, and there are a lot of clever things a compiler can do with it. i’m sure clang/llvm does a good job of it (though i haven’t experimented with it). it is hard to optimize very large functions, though, so it can be a benefit to break the case bodies into their own functions. it’s probably a good choice. this article just chose to focus on a cost that doesn’t exist.
Procedure calls in languages that dispatch on the procedure parameters or return value still seem like they would incur procedural overhead. For instance, virtual calls and exceptions. So I can see your argument being true for C but not general C++.
nah. not at all.
C++ virtual calls are just a function pointer dereference combined with a subobject cast operation. subobject casts can be rather involved, but there’s no overhead for doing it at a function call. if you want the kind of features you get from generic types with function pointers — polymorphic types — then the function call overhead is nothing. it doesn’t matter. it’s no worse to do the subobject cast at a function call than to do it anywhere else.
if you have a truly runtime type system in an interpretted language…again, it’s gonna be slow. it’s gonna be slow. the fact that you have a function call involved isn’t worth thinking about. your choice to use an interpretted language made it slow, and your choice to think about function call overhead doesn’t make it any faster, it just makes your code less clear.
Yes, C++ virtual calls are indeed “just” an indirect function pointer call, but you’re wrong to say this incurs no overhead. The overhead can actually be considerable for this kind of call, and Steele’s papers from the 70s are not evidence to the contrary because his data predates the deep pipelines and cache hierarchies that are now common. Just looking at data from the 90s [1] you can see that virtual function call overhead can account for up to 50% of running time in some programs that use them heavily!
Pipelines are bigger and branch predictors are better, so those numbers are no doubt different now, but more recent toy benchmarks still show a significant difference [2]. I’m just pointing out that my original caveat to your claim is valid: function call overhead largely doesn’t matter *except* in dispatching cases where branch targets are dynamic and thus unpredictable. This applies to virtual calls, exceptions, continuations and many other dynamic features.
For interpreted languages other overheads dominate these considerations, but these overheads can still matter for compiled languages.
[1] https://dl.acm.org/doi/10.1145/236338.236369
[2] https://gist.github.com/rianhunter/0be8dc116b120ad5fdd4
again, that’s not function call overhead. that’s dynamic dispatch. if you want dynamic dispatch, then you get similar overhead no matter whether you’re dispatching to function calls or dispatching with a different mechanism (for example switch with no function calls / inlined methods).
they’re explicit about this in the paper — their reference “ideal” implementation has the same number of function calls, they’re just “magically” (they used that word, “magically”) dispatched staticly. it also says that they saw a 21% improvement in performance by putting the subobject cast inside a “thunk”. that is, they say performance is improved if you simply move the subobject cast into a new procedure, adding another call. it’s specifically saying you can alleviate some of the dynamic dispatch overhead by having *more procedure calls*. because procedure call overhead doesn’t exist, but useful variations in cast mechanisms do exist.
it makes a strong argument for static typing, but it is neither here-nor-there for function calls. never think about function call overhead. it isn’t worth thinking about.
I’m not sure what you keep saying “no” to. I literally said in my first reply, “Procedure calls in languages that *dispatch on the procedure parameters or return value* still seem like they would incur procedural overhead”.
So if we now agree that there can be considerable overhead with dispatch, the question remains whether there’s a meaningful difference between function calls and dispatching. Operationally there is a difference in mechanism and performance, but the fact remains that most languages do not make a syntactic or semantic distinction between function calls and dispatch. So if you’re worried about consistent and predictable performance, “eliminate function calls” can be one legitimate technique, though typically not worth it for other reasons. Languages that expose the ability to inline as a language directive, like Zig’s comptime, are one way to do this better.
As for mitigating dispatch overhead via “more function calls”, that’s a bit of an oversimplification. IIRC, the optimization is that a dispatching thunk that acts like a polymorphic inline cache has more dispatching points and so the branch predictor works better since it can cache more locations. Not exactly what you’re saying but close enough.
I should also note that while static function calls have negligible overhead for pipelined out of order architectures these days, microcontrollers don’t have these optimizations and so they can incur more overhead. For instance, the ATMEGA328p requires 4 clock cycles for a direct subroutine call + 4 cycles for return instruction, 3 clock cycles for indirect calls + 4 cycles for return, and only 2 cycles for direct or indirect jumps with don’t require returns. Depending on how much performance you need to squeeze out of your microcontroller, pervasive inlining might actually be needed.
“So if you’re worried about consistent and predictable performance, “eliminate function calls” can be one legitimate technique, though typically not worth it for other reasons.”
no! if you need dynamic dispatch, then you will still need dynamic dispatch after eliminating your function calls. and that dynamic dispatch will not be any cheaper without the function calls than it was with the function calls. that’s the whole point — the function call itself is free. if you don’t need dynamic dispatch and your language is incapable of static dispatch then you’ve got other problems, and meditating on function calls won’t solve those other problems.
“Languages that expose the ability to inline as a language directive, like Zig’s comptime, are one way to do this better.”
no! this is exactly my point. sprinkling the keyword “inline” throughout your code is synonymous with “meditating on function call overhead”. but function call overhead doesn’t exist! meditating on it *decreases* your code quality. if your function calls should be inlined, they will be. C++ really is full of poorly-structured code specifically designed around the goal of being able to suggest that it should be inlined…they did this meditation to the detriment of every other goal and as a result it has a lot of non-function-call overhead in a vain and failed attempt to avoid small quantities of function call overhead.
“IIRC, the optimization is that a dispatching thunk that acts like a polymorphic inline cache has more dispatching points and so the branch predictor works better since it can cache more locations.”
why rely on recall when you could read the article like i did? why did you ask me to read the article? they say the function calls make it faster because providing exactly the operations that are needed for the specific subobject cast uses *fewer instructions* than having a generic table-driven subobject cast at the call site. the generic cast has to have operations that will usually not be needed (to support both virtual base classes and regular base classes). they say exactly what i said, that the subobject cast operation and the dynamic dispatch are the two classes of overhead, and that function call overhead is not. they say that alleviating the subobject cast overhead is valuable even if it incurs additional function call overhead. that is, addressing the overhead that does exist is more valuable than bending over backwards to avoid the overhead that doesn’t exist. it is literally exactly what i’m saying.
i prefer lua over python (which i think is way more popular than it deserves to be). its fast when interpreted and if you need something faster you can roll a module in c. its only real down side is its memory usage when using tables can be attrocious.
Isn’t lua this toy language where (integer) 1 is (boolean) false, and array are 1-indexed ? What a joke..
I’m not a fan of Lua, both of those claims appear to be completely false.
1) not 1 == false
2) Arrays can start at any index, including negative indexes.
Conventionally though, yes, arrays begin at 1. But that hardly makes it a toy language, it’s very widely embedded into a variety of apps (lots of games, some versions of Adobe Lightroom, etc), just less common to use standalone. It is definitely very easy to integrate with, since that’s basically what it’s designed for.
they are not really arrays which is one of lua’s problems (and the reason it hogs memory). while you can use less memory with numbered indexes, it comes with the caveat that it has to start at 1. starting at any other number will hike the memory usage. named keys and you are using a lot of memory. even then the numbered indexes can use a lot of memory. sort of in the case where you have an array of a large number of structures. which in lua’s case is tables of tables. if i need fine binary data, i usually encode it in base 64 and store it at as a string, which while it does waste a quarter of the memory it uses, its still less cumbersome than using tables. int types are available in 5.2 onward but im mostly using 5.1. presumably you could pack several bytes into that type to store binary data without wasting any bits. but i find if you need a lot of binary data you are better off with c/++ or implement a userdata type via a c module.
What do you have against 1-indexed arrays?
Arrays starting at 1 makes-for loops less error prone.
You get a shit-ton of bugs from people doing mistakes around loops in C-style languages, that you just don’t get in 1-based arrays of lua or pascal.
1-based indexing is the actual indexing in mathematics, while 0-based indexing isn’t indexing at all but pointer arithmetic. This comes from C where an array is just syntactic sugar for a pointer.
Dijkstra said it best:
Why numbering should start at zero, https://www.cs.utexas.edu/users/EWD/transcriptions/EWD08xx/EWD831.html
1-based indexing doesn’t solve off by one errors, it just moves them around. Also, what indexing math uses depends on the field. Combinatorics uses 0-based indexing for instance.
One could easily counter-argue that having an array start at 1 is also syntactic sugar. At the end of the day, the concept is the same.
I honestly don’t care either way, just be consistant. I have found it useful in my C code to treat arrays as 1-based, but then add an offset to the actual operation. Example:
int myIndex = someCalculation(…);
someArray[myIndex – 1] = value;
Whatever scheme you come up with, stick with it and your off-by-1 errors solve themseves.
Every other language does 0-indexing. It’s not just ‘c-style’. It’s inherent to computer and how indexes work. Off-by-one errors happen (not only of course) because of languages such as lua, that teach bad habits to new devs, and confuse seasoned ones..
You’re arrogant and wrong. The 0 index comes from the world of pointer offsets to the memory backing of an array. Lua doesn’t have pointers, so why is that important?
Pascal and Fortran both use 1-based arrays. It’s just your biases and bad attitude shining brightly. Never good traits in a programmer.
Let’s get down to actual features. Lua provides Pythonic syntax in a language whose interpreter is <300KB big. Without JIT it's faster than every other interpreted language. LuaJIT, written by one guy, was the fastest JIT compiler (a binary of 400KB) until Google splashed 17 gazillion dollars into building V8 (what's the size of that compiler?).
So why is Lua this efficient and this good (and used everywhere from the glue code on supercomputers to tiny embedded devices)? Because of beautiful minimal orthogonal design: true asymmetric coroutines, first-class functions, multiple return values, fully lexical scoping. The table itself is a slightly weird but quite miraculous (and only) data structure, easy to implement modules, classes, whatever else you like.
Fewer superficial opinions and more thought would serve you well.
lePereT, you are incorrect, zero-based indexing has to do with saner bounds checking and the relationship the bounds have with sequence length, and nothing to do with pointers. Djikstra showed this in the 80s:
https://www.cs.utexas.edu/users/EWD/transcriptions/EWD08xx/EWD831.html
It really doesn’t matter much in lua. The only data structure is the table, which is either a hashmap or an array. Lua does use a 1-index like fortran and pascal, but that’s mostly for ease of use. The 1st element of an array is logically array[1]. Array[0] should logically be the 0th element. :) Besides, its mostly moot in lua: you don’t really use array indexes in idiomatic lua. Most of the time you append an item to a table: Table.insert(T, item) and iterate over a table to read it: for _,item in ipairs(T) do end. I have to agree with others: your preference for 0-index arrays is an artifact of C style languages. Dennis Richie liked to use array=pointer and countdown style loops because they were super efficient. Not safe, just fast. C has the scariest memory bugs of any professional language. We should seriously be distancing ourselves from array=pointers, countdown loops, and zero based anything. And null terminated strings and buffers. It’s not 1970 anymore.
1-indexed arrays? Like Fortran? I mean, nobody could possibly use *that* preposterous toy language for anything!
A note of caution: LJR claims to beat the LuaJIT *interpreter* by a third – but of course, the LuaJIT interpreter is the fallback. The LJR JIT layer is, as yet, a work in progress – so whether LJR actually beats LuaJIT overall will not be known at least until it’s done.
on Ruby is possible too?