With billions of computers talking to each other daily, how do they decide anything? Even in a database or server deployment, how do the different computers that make up the database decide what values have been committed? How do they agree on what time it is? How do they come to a consensus?
But first, what is the concept of consensus in the context of computers? Boiled down, it is for all involved agents to agree on a single value. However, allowances for dissenting, incorrect, or faulting agents are designed into the protocol. Every correct agent must answer, and all proper agents must have the same answer. This is particularly important for data centers or mesh networks. What happens if the network becomes partitioned, some nodes go offline, or the software crashes weirdly, sending strange garbled data? One of the most common consensus algorithms is Raft.
Raft
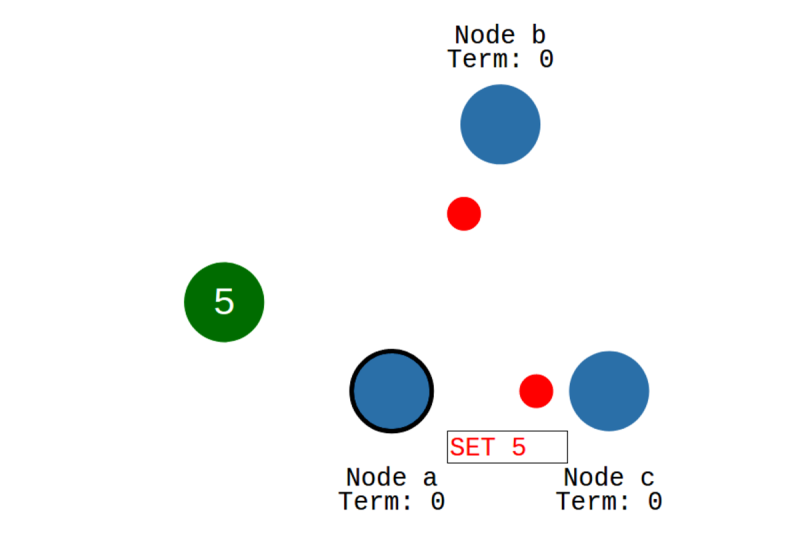
The Secret Lives Of Data has a great animated demonstration of how data flows inside the Raft algorithm between agents. The Raft GitHub page also has helpful diagrams. The Raft has provable guarantees that offer fault tolerance by an elected leader. Importantly, this elected leader does lead to a weakness in Byzantine failures, but we’ll cover that later. Databases such as Cockroach DB, Splunk, and MongoDB often use Raft, which is particularly tuned for allowing agents to agree on a set of state transitions, like transactions to a database. To summarize the Raft algorithm, there are two parts: leader election and log replication.
Imagine a set of servers communicating with each other and a client producing messages. These messages can be anything, like “set register Y to 6” or “delete row with id = 1230231”. When servers first come up, they are in a follower state and are looking to hear from a leader via a heartbeat. They try to become candidates in an election if they don’t receive a heartbeat within 150 to 300ms. The servers then vote on the candidates, and in the case of a split vote, the election term ends, and the cycle begins again. Timeouts are randomized to attempt to prevent divided votes.
The client sends messages to the current leader, and then the leader replicates the message to all the followers. Once it hears back from a majority of followers, the message is considered committed. The messages are appended to a log to be consistent across all servers. In the event of a leader failure, the logs of the newly elected leader are used, and inconsistent entries are deleted. Because any follower must have the most up-to-date committed log to be considered for election, it ensures that data committed to the majority cannot be lost.
Byzantine Failures
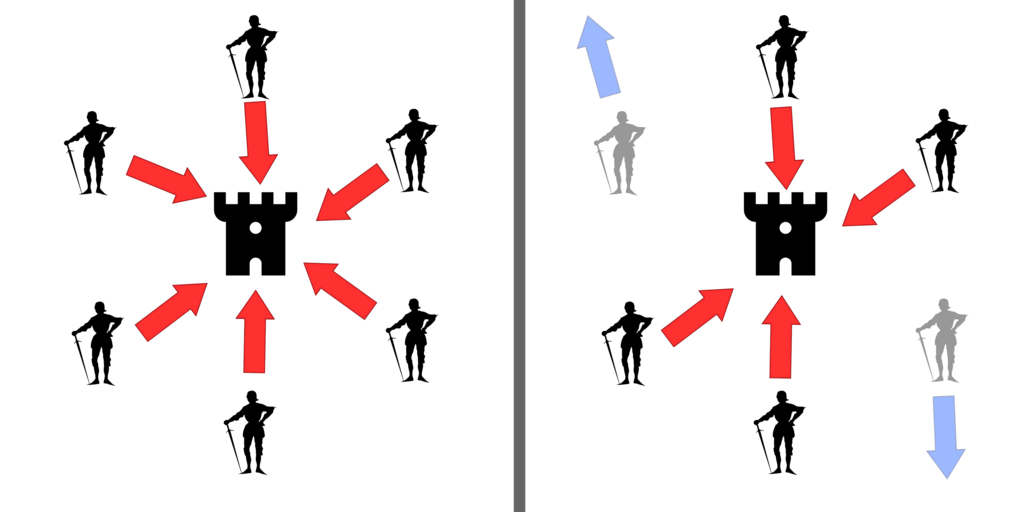
As mentioned, Raft/Paxos protects against server failures, not Byzantine failures. The name comes from the famous Byzantine Generals problem, where some generals are unreliable. They say one thing but do another. Raft assumes that when a system crashes, it fails and restarts. This is not the case in a hardware sense, as the device could continue to produce incoherent data, act incorrectly, or even be taken over by a hostile entity.
Nevertheless, many real-time systems, such as those on an airplane or spaceship, must keep Byzantine failures in mind. A component can generate erroneous data, and the rest of the systems must work around that. This can be done by additional messages to verify the actions of other servers, signing the data, or even getting rid of the idea of a leader altogether.
Lockstep Protocol
If you’ve played a real-time strategy game, you might wonder how the game can be consistent across dozens of players with incredibly slow connections. Unfortunately, the networking for Age of Empires was developed in 1996 when a 28.8 modem was relatively standard. So how can you serial the position and updates of every single object on the screen when you have a few bits per second to spare with wild network latency swings? The answer is that you don’t.
There’s a fantastic article on having 1500 archers running in real-time from [Paul Bettner], who worked on Age of Empires (among other things). The answer is only to send players’ actions rather than the state of each object in the game. Each game runs the exact same simulation, and each player’s commands are simulated on every player’s computer. In many ways, this is just like the Raft protocol: messages are passed and appended to a read-only log, and the log must always be consistent across all computers. But unlike Raft, there is no leader, and every server is also a client. There is a host, but there is no one true authority on the state of the game.
There is a monotonic turn number that is consistent across all clients. Each command is scheduled to be run in two turns. This allows the command to be sent, acknowledged, and processed while the game simulates. This does mean the simulation can only run as fast as the slowest machine, and there is a speed controller to change the length of a turn to keep the game playable. By separating render time from turn time, the gameplay stays buttery smooth for the player, even if the turn rate is relatively low.
Since each client runs the same simulation, it is hard to cheat (the Byzantine problem again). Any client sending confusing or non-sensical messages was de-synced and kicked out of the game. However, as you might be thinking, getting a simulation with randomness and probabilities to be consistent across dozens of machines with different processors and potentially even different architectures is challenging to say the least.
Crypto
Here at Hackaday, we tend to focus on the actual mining side of Bitcoin, but how does the network agree on the next hash? That’s the real power of Proof of Work. It is a distributed consensus algorithm at a large scale that can accommodate a large percentage of bad actors. We won’t go into detail (perhaps an article for another time). At the end of the day, that’s the only power of the blockchain and all the hype that goes with it. It is just a log of entries that we can all agree on in a decentralized way. Chia is another cryptocurrency that works on a similar principle but uses proof of stake instead of proof of work but has the same concept at its core.
Consensus is Everywhere
Consensus is everywhere, from airplanes to web services to cryptocurrencies. As a result, there are hundreds of consensus algorithms, each with different tradeoffs and performance profiles. Perhaps next time you’re implementing a mesh scale IOT project with many nodes that need to agree on shared values, you can reach for some of the ideas here.














Kudos on the shout out to Chia, the most decentralized and secure cryptocurrency blockchain in the world.
Isn’t Chia proof of space not proof of stake?
Yeah Chia is proof of space.