When you design your first homebrew CPU, you probably are happy if it works and you don’t worry as much about performance. But, eventually, you’ll start trying to think about how to make things run faster. For a single CPU, the standard strategy is to execute multiple instructions at the same time. This is feasible because you can do different parts of the instructions at the same time. But like most solutions, this one comes with a new set of problems. Japanese researchers are proposing a novel way to work around some of those problems in a recent paper about a technique they call Clockhands.
Suppose you have a set of instructions like this:
LOAD A, 10
LOAD B, 20
SUB A,B
LOAD B, 30
JMPZ DONE
INC B
If you do these one at a time, you have no problem. But if you try to execute them all together, there are a variety of problems. First, the subtract has to wait for A and B to have the proper values in them. Also, the INC B may or may not execute, and unless we know the values of A and B ahead of time (which, of course, we do here), we can’t tell until run time. But the biggest problem is the subtract has to use B before B contains 30, and the increment has to use it afterward. If everything is running together, it can be hard to keep straight.
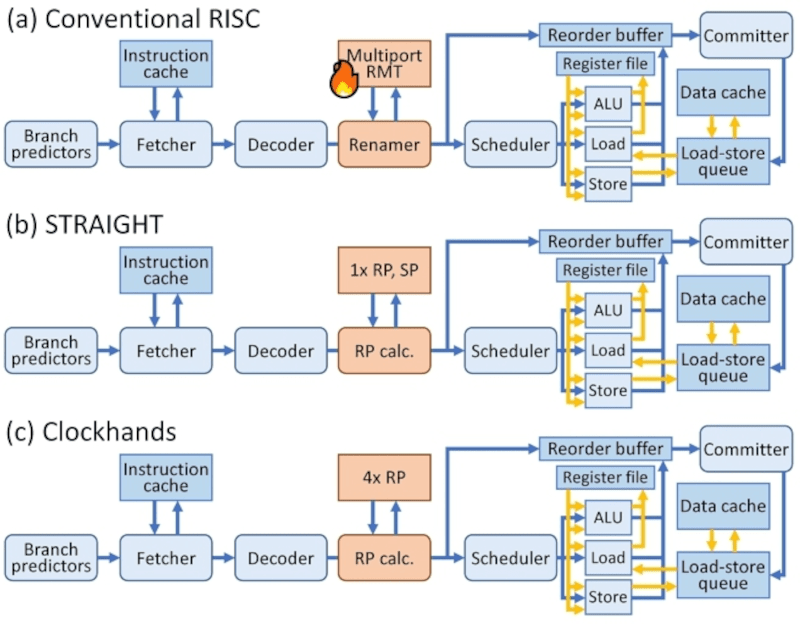
The normal way to do this is register renaming. Instead of using A and B as registers, the CPU uses physical registers that it can call A or B (or something else) as it sees fit. So, for example, the subtraction won’t really be SUB A,B but — internally — something like SUB R004,R009. The LOAD instruction for 30 writes to B, but it doesn’t really. It actually assigns a currently unused register to B and loads 30 into that (e.g., LOAD R001,30). Now the SUB instruction will still use 20 (in R009) when it gets around to executing.
This is a bit of an oversimplification, but the point is there’s plenty of circuitry in a modern CPU thinking about which registers are in use and which one corresponds to a logical register for this particular instruction. One proposed way to do this is to stop referring to registers directly and, instead, refer to them by how far away they are in the code (e.g., SUB A-2, B-1). This can be easier for the hardware, but more difficult for the compiler.
Where Clockhands is different is it refers to the number of writes to the register, not the number of instructions. It is somewhat like using a stack for each register and allowing the instructions to refer to a specific value on the stack. The hardware becomes easier, there is less for the compiler to do. This could potentially reduce power consumption as well.
Confused? Read the paper if you want to know more. Some background from Wikipedia might help, too. It reminded us of a CPU architecture from way back called The Mill (dead link inside, but there’s always a copy). If you didn’t know your CPU registers aren’t what you think they are, it is even worse than you think.













The Mill people reorganized their website.
https://millcomputing.com/docs/
I check the mill forum about once every 6 months (libre-SOC as well), to see how far they have progressed. And from an average Joe, reading what has been made public, neither project is dead, just not moving a long as fast as I would wish.
We have many CPU ISA, spark, motorola , powerpc etc.
problem is wit hpower eficience
All those ISAs rely on a complex and costly register renaming machinery. Remove it and you’ll have better power efficiency.
Many happy lawyers ?
https://millcomputing.com/topic/tokyo-universitys-straight-compiler/#post-3958
2033 the patents should expire.
Doesn’t this really mean your compiler just sucks at optimization? If the compiler/assembler is doing a “dumb” compile into assembly assuming a limited number of registers, then it’s leaving a lot on the table if you got 16+ registers to play with. It should be able to scan through and change the registers to enable more speed w/o the CPU having to do such lifting.
But the example is simple. What about branches that depend on data the is unknown at compile time?
the thing is, most popular ISAs expose on the order of 16 registers. but hardware has much more than that, specifically to support superscalar / out-of-order execution. and you can’t just expose these registers in the ISA, because they keep changing…it’s nice to have a relatively fixed ISA that doesn’t expose too many details of the execution engine, so the execution engine can change.
i am not gonna bother to click through to read a better summary of clockhands than the one here, but it doesn’t seem to me that it’s worth much. no one needs a more complicated and more implementation-specific way to define references to hidden registers. it seems to me like a waste to add bits to your instruction encoding just to reference “past values of a register”. if you’re going to add the bits, you might as well just name more of the registers. i mean, that’s ultimately how register allocator would have to treat it anyways.
though i’m not convinced referencing more registers is a huge win anyways. it seems hard to avoid the fact that a lot of operations simply are serial.
seems kind of like a baby step back towards VLIW?
From the paper: in a 3 argument instruction in RISC-V, they use 15 bits. In Clockwork, the equivalent instruction only uses 14 bits. So no, they are not adding bits to the instruction encoding, they are actually removing one.
You can have a lot more physical registers than the ISA register addressing space allows, and this is what OoO register renaming is for.
How are they going to make that thing secure? Surely the ‘S’ in ‘Clockhands’ stands for ‘Security’, but it is only a small ‘S’ right at the end, which might as well be left out altogether…
The efficiency gain probably holds true for exfiltrating secret data, no?
“””
NOTE: the slides require genuine Microsoft PowerPoint to view; open source PowerPoint clones are unable to show the animations, which are essential to the slide content. If you do not have access to PowerPoint then watch the video, which shows the slides as intended.
“””
*PLONK!*
I didn’t even get those and I have genuine PowerPoint. Maybe I need genuine EDGE.
Worked fine in Apple’s Keynote.