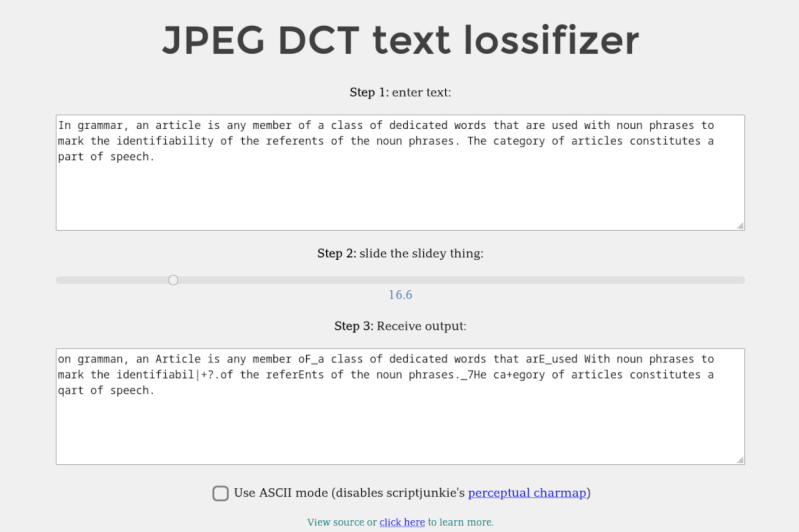
We’ve all been victims of bad memes on the Internet, but they’re not all just bad jokes gone wrong. Some are simply bad as a result of being copies-of-copies, as each reposter adds another layer of compression to an already lossy image format like JPEG. Compression can certainly be a benefit in areas like images and videos, but [Michal] had a bit of a fever dream imagining this process applied to text. Rather than let the idea escape, he built the Lossifizer to add JPEG-like compression to text.
JPEG compression uses a system similar to the fast Fourier transform (FFT) called the discrete cosine transform (DCT) to reduce the amount of data in an image by essentially removing some frequency information. The data lost is often not noticeable to the human eye, at least until it gets out of hand. [Michal]’s system performs the same transform on text instead, with a slider to control the “amount of JPEG” in the output text. The code for this script uses a “perceptual” character map, clustering similarly-looking and similarly-sounding characters next to each other, resembling “leet speak” from days of yore, although at high enough compression this quickly gets out of hand.
One of the quirks that [Michal] discovered is that certain AI chat bots have a much less difficult time interpreting this JPEG-ified text than a human probably would have, which provides a bit of insight into how some of these algorithms might be functioning under the hood. For some more insight into how JPEG actually works on images, we posted about a deep dive into the image format a while back.














Note_tI self: _don’t pIst coMmenTs.Ir Hackaday while druNK
That’s “11.9” compression of “Note to self: Don’t post comments on Hackaday while drunk.”
Sounds like a reverse turing test.
R U hmn?
Yes good point.
Except, unfortunately, it might not work because some chatbots apparently (mentioned in article) have a much less dificult time parsing the compressed texts.
But it might help *identify* those chatbots, since AI I don’t think was programmed to be humble and to hide its talents.
I believe that was the intent of the term “reverse Turing test.” Normally a Turing test provides a challenge that a human can answer but a machine cannot, but by running text through a meat grinder and getting a genuine response rather than “what?” suggests a LLM is interpreting the text.
Doubtful, that depends on the type of human. People respond normally to nonsense all the time. Would be tough to create a Voight Kampff that doesn’t class large groups of humans as machines
Interesting, I wonder what applications someone might come up with to use this transform. It certainly isn’t compressing the text in any meaningful way, so I doubt it will be useful for storage. Although… If you picked a level that was still readable but had enough noise it would probably defeat most text search algorithms, so if someone did a keyword search on your files, any doc that had this applied to its text would probably no register in the search at all. I could see a certain type of website admin using this to defeat web crawlers so their pages don’t turn up in search results.
Is it just me or does larger bodies of text read easier at higher levels? I also noticed if I try to read it fast it becomes easier, like your brain is auto correcting on the fly in a way we can’t when focusing too hard. Cool stuff.
Your brain does a lot of auto correcting. As the old meme goes: “it dseno’t mttaer in waht oderr the lterets in a wrod are, the olny irpoamtnt tihng is taht the frsit and lsat ltteer be in the rhgit pclae. The rset can be a taotl mses and you can sitll raed it whoutit a pboerlm.”
A text image should never, NEVER be saved as a JPEG! PNG and GIF are the formats of choice. Not only will these two formats look sharper and clearer, but the file size will be smaller than
… JPEG. I used to be a web developer (which included extensive optimizing of images in Photoshop), and can testify to the accuracy of this statement.
JPEG is for photographs of landscapes, nature, and people, NEVER for images like your example with large areas of one or two colors.
I’m not sure I’ve ever seen a GIF that was smart to use for anything large. But PNG, sure – if you quantize to a small palate of indexed colors without dithering, you can fit even something substantial like a 300-megapixel raster of a fairly detailed street map into ten megs or so. And I believe people have some ways of making valid jpegs that don’t look like complete crap even if they’re at lower quality equivalents, though I’ve never messed with it.
That said this isn’t actually about turning text into images.
I was going to point out the 256-color limitation of GIF (which I pronounce with a hard “g” and I will die on this hill because it’s not “jraphics”) but your rationale actually justifies it perfectly. 😁
I just don’t get the practicality of this… I mean, the file size will be smaller but the resulting text will be all messy.
Correct, exactly.
Welcome to shitposting 101
Big deal, I get the same effect when I turn spell check off.
I just send a prompt and let the AI at the other end of the link work out what I was trying to say.
Interesting but jpegs get smaller the more you move the slider. I guess I was expecting it to perhaps start leaving some letters out or combining two or three letter combos to one. The output should not grow longer than the input.
Jpeg images don’t get smaller, just the file size.
The results resemble how the game NetHack degrades text written in the floor dust. That’s been around for nearly 40 years!
Woohoo! I no longer have to tear up a document and put it through OCR.
“the_puikK_BroWn fI$ jumps over_The.L@V? dOg”
12.9
The whole purpose of compression is to reduce size. No matter how far you slide the slidey thing, the data size remains the same. I think he needs to release version 0.02 alpha.