
I think most of us who make or build things have a thing we are known for making. Where it’s football robots, radios, guitars, cameras, or inflatable textile sculptures, we all have the thing we do. For me that’s over the years been various things but has recently been camera hacking, however there’s another thing I do that’s not so obvious. For the last twenty years, I’ve been interested in computational language analysis. There’s so much that a large body of text can reveal without a single piece of AI being involved, and in pursuing that I’ve created for myself a succession of corpus analysis engines. This month I’ve finally been allowed to try one of them with a corpus of Hackaday articles, and while it’s been a significant amount of work getting everything shipshape, I can now analyse our world over the last couple of decades.
The Burning Question You All Want Answered
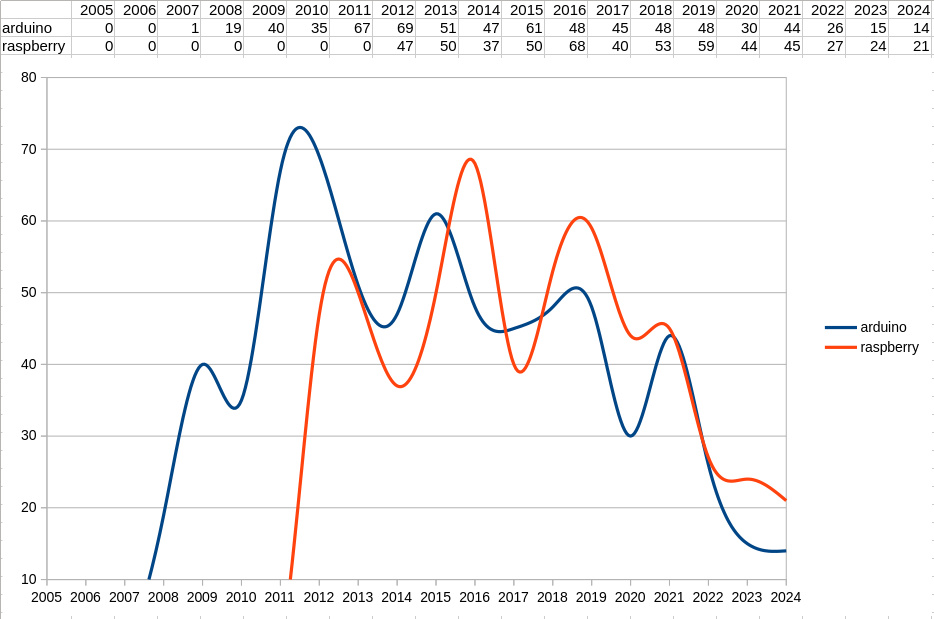
A corpus engine is not clever in its own right, instead it will simply give you straightforward statistics in return for the queries you give it. But the thing that keeps me coming back for more is that those answers can sometimes surprise you. In short, it’s a machine for telling you things you didn’t know. To start off, it’s time to settle a Hackaday trope of many years’ standing. Do we write too much about Arduino projects? Into the engine goes “arduino”, and for comparison also “raspberry”, for the Raspberry Pi.
What comes out is a potted history of experimenter’s development boards, with the graph showing the launch date and subsequent popularity of each. We’re guessing that the Hackaday Arduino trope has its origins in 2011 when the Italian board peaked, while we see a succession of peaks following the launch of the Pi in 2012. I think we are seeing renewals of interest after the launch of the Pi 3 and Pi 4, respectively. Perhaps the most interesting part of the graph comes on the right as we see both boards tail off after 2020, and if I had to hazard a guess as to why I would cite the rise of the many cheap dev boards from China.
The Perils Of The Corpus Maintainer
The astute among you might wonder why the figures on the graph above are not higher, because surely we have featured more Arduino or Raspberry Pi projects than that. And here we touch on a problem faced by anyone working with data. It comes down to this: are we looking at spotting the trends from the data, or absolute figures? When I built this corpus, I had to make two choices, one over how much I was allowed to stress Hackaday’s infrastructure, and the other in how much computing power and physical storage space I was prepared to give the project on my bench. I lack a computing cloud for my work, instead I have to rely on silicon and spinning rust I own, and to that there’s a finite limit.
Thus in building this corpus I reasoned that the more important words pertaining to each story would be nearer the start, and restricted myself to the title and first paragraph of each Hackaday piece, or about a hundred words. It’s definitely enough for trend analysis, but for obvious reasons if the word you are looking for is way down in the third or fourth paragraph, you’ll be disappointed. Furthermore if this technique angers you, don’t look too closely at how your oscilloscope samples higher frequency waveforms.
World Events Playing Out On Our 3D Printers
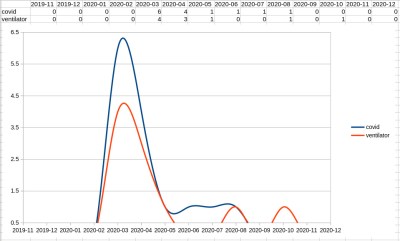 We’re not a world news site, but there are times when events intrude upon our world. Perhaps the greatest of these was the COVID pandemic, when for many people the world stopped. Hackaday kept going, but unsurprisingly there was a lot of discussion of the pandemic and the projects which surrounded it.
We’re not a world news site, but there are times when events intrude upon our world. Perhaps the greatest of these was the COVID pandemic, when for many people the world stopped. Hackaday kept going, but unsurprisingly there was a lot of discussion of the pandemic and the projects which surrounded it.
Do you remember the period in which governments were in a panic about not having enough ventilators? We had quite a few stories on the subject at the time, and they appear in the corpus. Fortunately it was pretty soon understood that home made ventilators would be dangerous so we were right to be cautious covering such projects.
Language Evolving Before Our Very Eyes
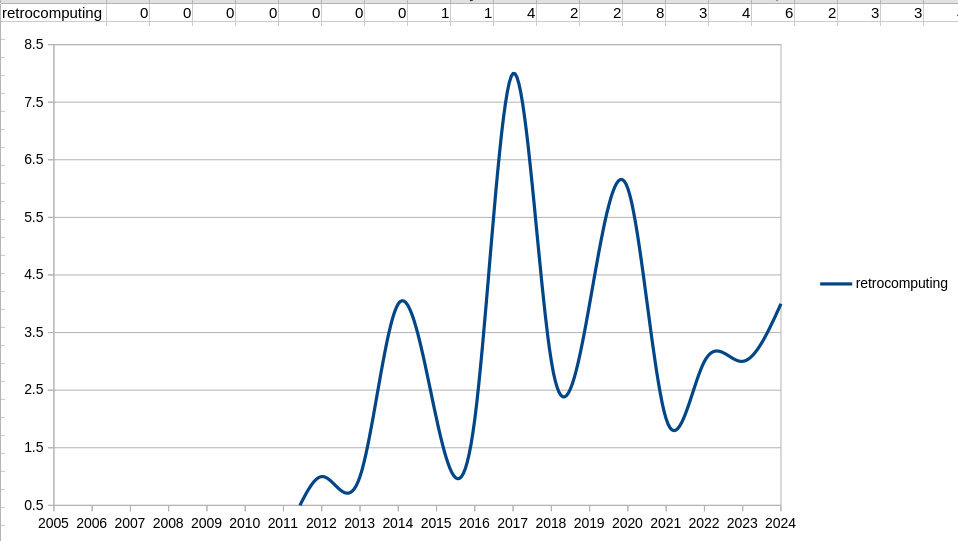
When I started on my corpus software projects, I was interested in the relationships between words because I had spent a while working in the search engine business. Later on I became interested in using the same techniques to spot trends in news content which is what has sustained my interest, but there’s another use for these techniques.
In the dictionary business, lexicographers use corpus engines to track developments in language, and we can see that in action in Hackaday too. When did you first hear the term “Retrocomputer”? We’ve all been fooling around with old computers for years now, but in our corpus it first appeared in 2012. Since then it’s had a few ups and downs, but it remains on an upward trajectory. For the graph I combined all the various forms of the word, “retrocomputer”, “retrocomputing”, and so on.
So What’s Under The Hood?
Computers are not clever in themselves, they are merely very good at repetitively doing something you tell them to, for many hours without complaint. In this case, my computer is analysing and indexing a large body of text, and the way I’m doing it was arrived at over quite a few iterations. It’s a product of the hardware I had when i started work on it, an Intel Core laptop which was quite flashy for the mid-2000s, and then later a pair of always-on Raspberry Pi boards with USB hard drives. My problem was that if I tried to use any of the available databases to store my index they would quickly become unusable due to its immense size, so I arrived at a technique using flat files instead.
You can run a version of my software yourself, it can be found in my GitHub repository. The processing script takes the text and splits it into sentences and words, then stores frequency and collocate data as a huge tree of small JSON files on a hard disk volume, the reasoning being that the filesystem is an extremely fast way to retrieve data categorised by directory and filename.
The version I’ve used only deals in single word phrases, but other versions have extended the directory tree based index to support multi-word phrases. You can also plumb in a part-of-speech tagger if you wish. The result is a fully functional corpus engine that can run on an original Raspberry Pi 1, not bad considering that it can mine multi-million-word corpora in an instant. Mine has the task of continually updating a corpus of news data, allowing me to watch events unfold in real time.
Now. Over To You
I have spent a lot of time over the last month getting the Hackaday corpus together and ready for analysis, and then more time gathering the data for and writing this story. I’ve only been able to show you a small amount of what’s in this trove of data, so perhaps there are trends you’d like to see explored. Use the comments below to request, and maybe I can show them in a follow-up.














Erm not to be that guy but…HaD’s infrastructure will trivially handle a 1-time full scrape, and this isn’t even that much data, it’s weird you had to get permission for that.
I think you’d find that a standard database like postgres would do fine for indexing this given the right structure. ALSO this would be a great application for a bloom filter – create a filter for each day as a row, put all unique words into it, then use standard sql to query.
For a more real-world approach, with a few gb of ram you can run elastic/opensearch, and use its full-text search.
Agreed — but if you think about it, it hits our CDN funny. They’re used to serving the same page a lot, and this would be serving each page once.
We have routine backups, but one time we wanted to pull it all down for experimental/dev reasons, and it ended up being easier to put it on a hard drive and mail it. The media attachments are huge.
apropos of nothing, would you say there’s around 55,117 articles on HAD total?
It’s a WordPress site; no need to scrape anything, you should be able to take a copy of the database and query straight on that, surely?
SELECT count(*), post_date FROM wp_posts WHERE post_content LIKE “%arduino%” AND post_status=“publish” GROUP BY year(post_date), month(post_date)
That should run in a reasonable time on a typical workstation?
The whole stats-building step I can see would be useful back when PCs were less powerful, and would still be useful with a much larger corpus, but we get what 10 post/day here? That shouldn’t be a big corpus by today’s standards?
Great insights though, would be intrigued to know what else you find.
What I’m about to write may sound a bit dumb to some, but could be very comforting to others.
Her it comes: “I have absolute no clue at all what this entire article is about, completely clueless here”.
Honestly, it was a lot of words to say “I scraped HaD and put all the articles into a custom database that allowed me to query what words appear on what days.”
Datamining HaD. All the rage.
I wonder what the frequency is like of people asking for an edit button in the comments. Has that always been a thing?
The frequency of this and some flavor of “not a hack” are the KPIs we should be tracking
+1
+1 as well.
“All” we need from the comment plugin is that it’s secure, doesn’t require a login so that we can maintain anonymous comments, and enables edits without destroying thread history.
We continue to be unwilling to move to one of the comment services, because they are just too Big Brothery and track you all over the internet.
If anyone has any recommendations, we’re all ears!
regarding HaD comment plugin, Elliot wrote : “If anyone has any recommendations, we’re all ears!”
Please think about results. HaD comment section is consistantly excellent — better quality responses than any other website or social media I visit. No wierd voting, no encouragement for quantity of posts as opposed to quality of posts, no intrusive unnecessary questions.,
Just keep on managing comments your way.
Thanks Edward. For all the flaws of WordPress, Hackaday comments are pretty damn good for a free forum. Hopefully the HaD staff aren’t overwhelmed with manual moderation, because in general it’s a pretty good system.
And if you need to edit a post, just put your edits in a reply to the post that needs editing. though I do concede the limit of nested comment depth can sometimes make this awkward. HaD does let you quote by using a “greater than” sign though.
Finally, thank you to all those people who post useful info and links in the comments. I have learned a lot on here.
i didn’t analyse the comments.
you should! They are worth a fortune…
What is the HaD-approved way to get a full offline copy of the site for reference?
hmm … would “Paperbackaday” (or “Paperbhackaday”?) be a book of this site or a newspaper?
not enough 555 for me
Man, I didn’t realize it’s been so long. The first article that I read on HaD was this: https://hackaday.com/2005/03/03/make-a-palm-pilot-robot/
I just about had a stroke when I saw it was 20 years ago. I can’t believe it. It’s been a fun ride guys, even though I’ve just been a silent lurker for the most part
From my experience with fragmented and sparse data: how are the graphs so smooooooth?
Kudos for running this on “underpowered” hardware, I am a big fan of utilizing the low end for long running processes.
Wondering how putting the data into a data structure that is designed for time-based events would work out. My current favourite is VictoriaMetrics and also VictoriaLogs – they easily run on RPi1 hardware and have a really nice query interface with graphs built-in. My current playground for analysis runs on a RPI3 and querying over millions of data points gives instant results.
Graphs have humps that look like Gaussians to me, and probably represent a smoothing choice rather than the actual data. (It’s too smooth.)
I’d rather see it raw and jaggy.
I used LibreOffice Calc for most of it, and used the smooth line option.
Interesting how topics seem to run in cycles. “New and hot” for a 2 years, down for a year or two, then “what is old is new again”. Perhaps this is related to product cycles?
I don’t know if I’m an outlier on this, but would this not be a good candidate for a local RAG (Reinforce-Augmented Generation) LLM system? One way to test this first would be to try a few weeks worth of articles and comments using Google’s online NotebookLM – which I understand accepts data from urls as well as pdfs/docs etc.
This is new for me, but I’ve been looking into investing into a local (my machine) llm for my wife who is going to a new job in a very restricted environment. This job will involve a lot of information processing.
The reason for doing this would be to elicit insights and summaries, and maybe even sentiment, rather than straight greps or queries.