If you’re going to be a hacker, learning C is a rite of passage. If you don’t have much experience with C, or if your experience is out of date, you very well may benefit from hearing [Nic Barker] explain tips for C programming.
In his introduction he notes that C, invented in the 70s by Dennis Ritchie, is now more than 50 years old. This old language still appears in lists of the most popular languages, although admittedly not at the top!
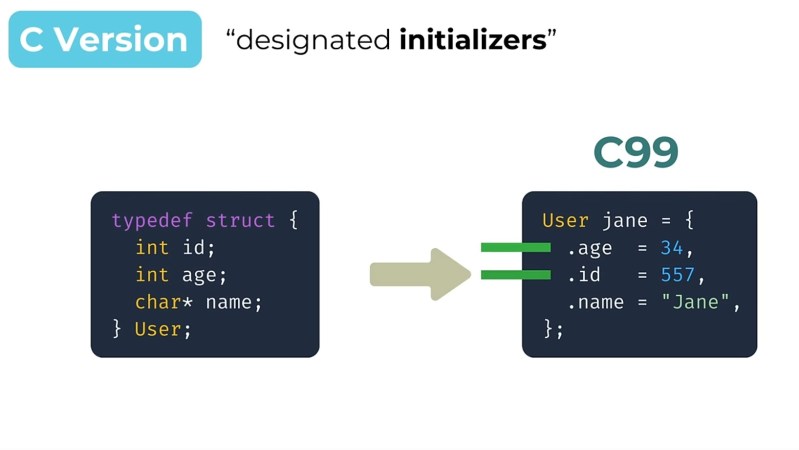
He notes that the major versions of C, named for the year they were released, are: C89, C99, C11, and C23. His recommendation is C99 because it has some features he doesn’t want to live without, particularly scoped variables and initializing structs with named members using designated initializers. Also C89 is plagued with non-standard integer types, and this is fixed by stdint.h in C99. Other niceties of C99 include compound literals and // for single-line comments.
He recommends the use of clang arguments -std=c99 to enable C99, -Wall to enable all warnings, and -Werror to treat warnings as errors, then he explains the Unity Build where you simply include all of your module files from your main.c file.
It’s stressed that printf debugging is not the way to go in C and that you definitely want to be using a debugger. To elaborate on this point he explains what a segfault is and how they happen.
He goes on to explain memory corruption and how ASAN (short for Address Sanitisation) can help you find when it happens. Then he covers C’s support for arrays and strings, which is, admittedly, not very much! He shows you that it’s pretty easy to make your own array and string types though, potentially supporting slices as well.
Finally he explains how to use arenas for memory allocation and management for static, function, and task related memory.














Or you enable C17. Or C23, the actual version. C99 is history.
Still used a lot actually. rtl_433 is written in C99
If C11 didn’t enable unicode spoofing attacks it would be good idea. But with this you can’t get external contributions.
Who?
You know, Nic Barker. He writes about C programming and other technical stuff.
Mark Topham writes songs for Steps, a popular beat combo from the UK.
Int Steps[] = {5,6,7,8};
Mark Topham writes a lot of songs.
Mark Topham writes Unix books.
Etc…
None of which are me. The name is common enough I’ve almost run across myself directly once or twice.
I was thinking of buying a few samples of various things made/written by Mark Topham and shoving them on a bookshelf just to see if it would trigger people; but people would misunderstand. (Thinking I’d claim authorship, instead, it just breaks first impressions and assumptions).
I usually do web development, electronics, photography [nature, event, or astrophotography].
Looks like this morning I’ll be a Network Engineer as I try and diagnose my wifi network so I don’t have to drive into the office.
“Looks like this morning I’ll be a Network Engineer”
So, are you going to write a song or a book about it? 😁
I have a couple of cookbooks written by an author who shares my first, middle, and last names. Probably close to 20 years ago, I did a series of web searches on variants of my name, intending to write a “composite autobiography” for my blog, complete with links to the individuals whose backgrounds I was going to borrow. I never did write the bio, but I thought the most amusing career someone sharing my name had was “ice-skating illusionist.”
Lol
What is a good program project for a C learner? First semester student or self teacher. Be advised that if you say “Hello World” I will invoke kanly.
I often ask people to calculate a Fibonacci series using four different methods described in the comments shown below from my reference solution. It teaches them something about recursion and about runtime optimisations and how you can use approximations if you do not need precision, so not just C but also good programming practice. Apologies already for the expected presentation mess due to Hackaday formatting.
// 1: Recursively where Fib(N) = Fib(N-1) + Fib(N-2) N ≤ 2; Fib(1) = 1; Fib(0) = 0
// This method scales badly as each calculation of Fib(N) calls itself recursively at every step
// and thus grows exponentially
// Fn(N) is the number of calls required to calculate Fib(N):
// Fn(0) 1 Fn(1) 1
// Fn(2) 3 Fn(3) 5
// Fn(4) 9 Fn(5) 15
// Fn(6) 25 Fn(7) 41
// Fn(8) 67 Fn(9) 108
// Fn(N) ≈ 21.6^N Fn(90) ≈ 510^18
// The runtime of the current implementation is somewhat saved by optimisation of tail recursion
//
// 2: Linear progression of the above formula using temporary variables to store Fib(N-1) and Fib(N-2),
// requires N steps to calculate Fib(N)
//
// 3: Recursive variant of the progression with N calls of the routine to calculate Fib(N)
//
// 4: Calculates Fib(N) as ⎣ Phi^N / √5 + ½ ⎦ where Phi is the Golden Ratio (1 + √5)/2
Great video, the only bit that would not work for me is the arena concept. It assumes large amounts of ram is available and that the scope is open for a long time. I can see it working for documents as he suggests.
I dunno, I only skimmed most of it but the “unity build” idea is terrible. Maybe he doesn’t know about static or why it is used.
It can save a lot of compile time and therefore build time: If you have 60 separate compilation units and there’s a lot of the same header files imported, the C preprocessor runs 60 times as often. Building from a single .c file that #includes the remaining source files can very much decrease your build times.
amdahl’s law. 60 times nothing is nothing. can’t improve on nothing.
you’re thinking of C++ where parsing the header files takes wall time. in C, it’s not a consideration. except in rare / contrived cases, parsing header files is effectively free in C.
if you’re talking about comple-time, it’s actually potentially the opposite. one of the advantages of unity build is exposing opportunities for the inliner, which means it’s actually doing more work. unlike header files, inlining does often contribute meaningfully to compile time, because it makes bigger functions and a lot of optimizer and codegen steps degrade to O(n^2) in the size of the function (which is a big part of why C++ header files are so slow)
C99 is a good choice it is simple and good to learn with can still be used for modern software. I wouldn’t necessarily recommend newer versions unless you know what you are doing, at which point you don’t need my advice.
Far too many think they know what they are doing. Most don’t understand the subtle pitfalls waiting to catch you out. Doubly so in multicore/processor systems.
For example, consider that Hans Boehm had to forcibly point out to experts that you couldn’t write a threading library in C. Yes, experts had forgotten some of the fundamentals, and had deluded themselves that they could write threading libraries in C.
That prodded the standards committees into inventing the memory model, something that other languages had known was necessary almost 25 years (a quarter of a century) earlier!
I’m sceptical whether most C programmers understand the memory model and use it correctly.
Moral: use a modern language for most purposes, leaving C for small programs.
Small programs like the Linux kernel and most of the userland?
With modern coding practices you don’t need to think, but rather follow a set of precise guidelines. The worst cases of spaghetti code are usually written by independent thinker programmers, who though they are too smart to do as they’re told.
Nice phrases, but there are problems when they encounter The Real World.
“Cargo cult programmers” follow guidelines as they understand them.
The reasons for guidelines need to be visible and to be understood, in order to avoid cargo cult programming.
Guidelines are hints and tips based on presumptions. Guidelines cannot be comprehensive, and their quality strongly depends on the person writing the guidelines, how well they can understand their audience, and the application’s existing codebase. A language like C exacerbates those problems.
Thinking is always necessary; there is no substitute.
Given two imperfect tools/products, one of which makes demonstrably unrealistic presumptions about how it will be used, and one of which prevents/avoids well known misuses, which tool should a responsible engineer choose?
Misunderstanding “cargo cult” is a red flag. “Cargo cult” programmers make and follow rituals without understanding, that’s the point of the term.
Pretending the Linux kernel doesn’t exist worsens your case.
You have given a number of obviously incorrect statements and baked them up with barely disguise anger and frustration instead of engagement. Why not bring up real issues?
Seriously, get some fresh air or something, C isn’t a cult, it just has a lot of solid work done in it that has built logical frameworks for implementation.
Spaghetti code is not a symptom of thinking, it’s a symptom of a lack of planning. You ad-hoc your way through the problem and then either run out of time, money, or the will to do it properly. This is the real sin of “smart programmers”, because they tend to think as they go rather than think ahead, because they’re smart enough to do that.
The not-so-smart programmers who follow the guidelines are better in the sense that if there’s no guidelines and no canned solutions, they just can’t do it. You get no output, but at least it’s not terrible.
Programming is easy.
Systems analysis is hard.
Many programmers will do systems analysis by building a throwaway prototype.
But PHBs are dumb AF.
Cookbook programmers need all the hard work done for them.
They’re always shit testers too.
Can you elaborate? When was this, and what was the problem?
Looks like this is what they’re referring to: https://www.hboehm.info/misc_slides/pldi05_threads.pdf
It just identifies a a subtle issue for multithreading that means it’s impossible for C99 to implement fully correct concurrent access to shared memory without some extra language features. Anything that synchronizes that access completely avoids the issue though, and Boehm actually commends pthread for how close it gets to full correctness.
This isn’t a problem for 99% of developers, and it’s not like the world has imploded because of it. At worst, some people need to add extra thread synchronization that “might” not have been necessary with a different language (and it’s not like there’s a long list of alternatives listed.)
This is also from twenty years ago. So before C11 came out.
That is indeed the specific issue.
If concurrent memory access isn’t “fully correct”, then it is incorrect. Maybe 99% of programmers don’t notice an incorrect result, or are content to reboot the application/system, but not all of us are in that position. Some of us write life critical programs.
Later versions of C have addressed the problem, but the standards committee members (?experts?) should have noticed the problem decades earlier and corrected the omission.
For those that fancy themselves expert C programmers, there’s always the drolly amusing C++ FQA to calibrate their belief https://yosefk.com/c++fqa/ . Many of the infelicities noted for C++ are equally valid in C.
Tom G – The “problem” isn’t that the result isn’t correct but rather that the way the programmer specified the process to the compiler didn’t exactly correspond to a certain model of how they could have specified the process to the compiler. There are more expressive ways to deal with assumptions about memory models than pre-C11 standard C, but the old fashioned way to do it was provably correct too (albeit less portable). I’ve been doing multiprocessor programming in C since 1997, and have specifically confronted this concept of ‘provably correct’. The fact of the matter is that even with all of the expressive capability of C11, you should only really be using “seq_cst”. The other memory models are kind of “neato”, but if you are doing code where the optimizations they enable are more than zero then you really should rethink your algorithm to minimize shared data in the first place.
If I was writing a pthread implementation from scratch using the C11 atomic interface, maybe the new expressive power would be worth something. But the guy writing pthreads has always cared about the specific target platform in detail, and that hasn’t changed in the 30 years of pthreads.
Before C11, we just used the guarantees compiler and hardware vendors gave us, and we were perfectly able to produce provably-correct code. In fact, C11’s model is very closely derived from a proprietary interface that Intel invented and gcc supported since long before 2011.
Greg A
…
Yes, of course parallel processing was done in C long ago. The point is that it relied behaviour beyond that specified in the C standards.
The original C “spec” explicitly stated that multithreading/multicore and similar was outside the scope of the language and was a library issue. And didn’t provide guaranteed behaviour that would allow the library to be written in C.
The consequence is that the libraries had to rely on the behaviour of a specific compiler for a specific processor.
“Experts” never got around to fixing that, “experts” forgot about it, hence Boehm’s having to rub their noses in it.
That repeated itself when Erwin Ruh forced the C++ committee to realise they were creating a language where a valid conforming program could never finish being compiled. Stunning. Still true!
If the people creating the language can’t understand it, what chance do mere mortals have?!
The language becomes part of the problem, not part of the solution.
Tom G – pthreads has always been written in C, just with target dependencies. Many things are written in C with target dependencies. That’s both a strength and a weakness of C. The standards committee has made many mistakes over the years but they are definitely all well aware of the benefits and drawbacks of leaving things undefined so that the C language can be used in a broad diversity of ways.
Frankly, i don’t even think you disagree with their judgement on this matter. I think you’re just looking for reasons to disapprove. I think you’re trying to lay the foundations for an ad hominem attack against the C committee’s decisions in general based on a decision that they waffled on after 20 years. I don’t believe you truly understand or care about this decision. Among people who actually use C for multiprocessing systems, every step of the evolution has looked pretty sensible, if frustrating at some moments.
Have you ever used any of these features you’re today talking about? Have you ever used target-specific APIs for multi-processing, have you ever looked in a hardware architecture manual or target ABI manual to find out answers to questions you wish had been answered in the C standard? Have you ever reviewed parallel code for correctness? Ever used SYSV IPC, pthreads, openmp, or the old __sync_xxx builtins? Ever waded into the morass of memory access models that represent the modern C and C++ approach to reducing synchronization overhead while ensuring correctness?
Ok, now it’s clear that either you didn’t understand the issue completely or you are deliberately misunderstanding it in order to bolster a straw man attack against C. C isn’t Goliath, you’re not David, and the world doesn’t care about stones you’re throwing in some random website’s comments section.
There are countless things in the language that cause Undefined Behaviour, and this is one. The paper even says that the construction which doesn’t work is explicitly illegal under threads. If you don’t want undefined behavior, don’t write code that invokes it! You can still share memory, you just can’t do it unsynchronized.
Also would like to recommend the usage of static code analysers. I use cppcheck myself with the GUI. Its easy to use and catches a lot of stuff (mostly edge cases that you might have missed)
The worst way to find the memory corruption is to use debugger…
Can obfuscated uncertified hacker c be hacked?
i stopped watching the video when he was talking about using single translation unit and including .c files
This is the kind of content that absolutely should not be presented in a video. In order to make use of it, the really determined student will have to take notes while they watch the video, so they can use the notes when it is over. Far better to have provided this information in a “skimmable” and “truly random-access” format like a document.
That’s just a general nit about the genre but this particular example lives up to all the weaknesses of the youtube farmed content tradition. The guy doesn’t actually understand or love C, and therefore presents both counterfacts and bad advice. I was astonished by the summary in the hackaday write up of C89’s scoping limitations, so I watched just enough of the video to verify that it is a faithful summary of the counterfact in the video.
C89 has local scoping, it just requires that they are declared at the start of the scope — not necessarily at the start of the function. I am absolutely at peace with the fact that anyone born after 1990 will consider that distinction to be absolutely irrelevant. But anyone who doesn’t understand that kind of distinction can’t be teaching anyone else about the evolution of the C language. Not knowing pre-history is normal, but precludes teaching it.
Yes indeed.
That’s yet another reason why I dislike 99.99% of yoootooob vids.
—-John Elliot V says:
—-October 8, 2025 at 6:07 am
—-You don’t know what you’re talking about grandpa.
That is offensive, demeaning, arrogant, and hence should not be part of a Hackaday conversation.
It is also wrong.
We have a troll who is impersonating various regulars and posting racist and offensive comments at the moment. If a comment seems wildly out of character, best to assume it’s that asshole.
And it’s probably no coincidence that this is showing up while the moderation system is broken.
That is unpleasant and unfortunate, and does not reflect well on Hackaday staff.
I am mildly surprised impersonation is possible: comments must include the not-visible email address as the moniker, so simple automation could easily trap out imposters.
But to do that, the system would have to verify the e-mail addresses, which completely undoes anonymity.
(Posted by Elliot Williams, in an incognito window, just for funsies.)
And FWIW: We’ve had people impersonating other anonymous posters too, in the past. That’s also not cool, but trolls gotta troll?
We think about locking down the comment section every couple years and going authenticated-only. My fear is that we’d lose more good comments than bad. So we just keep whacking at the moles as they pop up. :)
I’m honestly surprised things go as well as they do. Authenticated sites still have issues as it is.
John Elliot V has confirmed it was a troll, and deleted the comment.
Job done :)
Yup. It was a troll.
FWIW: the way you can tell a verified account from an anonymous one is the color. Yellow = verified. This one was white.
Unfortunately, allowing anyone to post under any name leads to this sort of shenanigans.
(And I confirm that’s me above impersonating Tom G. But this time “in yellow”.)
Write code. Use valgrind. Free yer memory, don’t dereference stuff off the end. Profit. C is not hard to write good code for anybody that can’t handle pointers should stick to basic
Hey now, don’t be mean.
I’ve written many small ‘C’ programs without running into any issues. So I was always confused when our Java programmer claimed Java was better for programming our Robot as it did not have C++’s memory issues. While I found Java a clunky language for calling the underlying C and C++ routines that actually controlled the Robot Hardware. Especially earlier when the Java equivalent methods were incomplete and undocumented.
Thank you for showing us what type of Memory issues we might encounter in C99. Now we need to know if they still exist in C++ 11 or 23?
As for rewriting the C Standard String Library I doubt most companies would appreciate programmers taking time to rewrite Standard String Libraries in order to use their favorite programming language. If your “Strings” are longer than 80 or 132 characters then maybe defining a custom Struct and overloading String methods makes sense. Imagine every legacy program in your company having a custom String handling method written by a different programmer.
C is not modern programming. Even in 1974, C was a devolution on programming languages. C is a primitive coding language. Not only was it a quick and dirty development full of flaws that lacked pragmatic thinking to avoid potential traps, but it was not developed to support the process of programming and project organisation. These are the hallmarks of modern languages (at least since the 1960s).
Those features of modern programming are not ‘training wheels for beginners’, ‘crutches for weak programmers’ or the other trite platitudes that the C cult puts around. Yes, they appeal to programmer ego, but it is taking programmers for fools.
Not only that, but C burdens programmers with many details that other languages and compilers take care of — like all the awful pointer referencing and dereferencing.
Why Pointers are Wrong
From the logical programming point of view:
https://www.quora.com/Why-is-it-hard-to-understand-pointers-in-programming/answer/Ian-Joyner-1
From the physical implementation view.
https://www.quora.com/What-are-the-memory-addresses-that-a-pointer-points-to-in-C-programs/answer/Ian-Joyner-1
Pointers weren’t even invented in C. They were Christopher Strachey’s mistake. Dennis Ritchie was not a language designer, he was a programmer and compiler writer. Here is the history of C:
https://www.quora.com/How-did-Dennis-Ritchie-and-Ken-Thompson-who-created-everything-without-knowing-OOP-manage-to-maintain-the-efficiency-of-their-programming-work/answer/Ian-Joyner-1