On November 18 of 2025 a large part of the Internet suddenly cried out and went silent, as Cloudflare’s infrastructure suffered the software equivalent of a cardiac arrest. After much panicked debugging and troubleshooting, engineers were able to coax things back to life again, setting the stage for the subsequent investigation. The results of said investigation show how a mangled input file caused an exception to be thrown in the Rust-based FL2 proxy which went uncaught, throwing up an HTTP 5xx error and thus for the proxy to stop proxying customer traffic. Customers who were on the old FL proxy did not see this error.
The input file in question was the features file that is generated dynamically depending on the customer’s settings related to e.g. bot traffic. A change here resulted in said feature file to contain duplicate rows, increasing the number of typical features from about 60 to over 200, which is a problem since the proxy pre-allocates memory to contain this feature data.
While in the FL proxy code this situation was apparently cleanly detected and handled, the new FL2 code happily chained the processing functions and ingested an error value that caused the exception. This cascaded unimpeded upwards until panic set in: thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
The Rust code in question was the following:
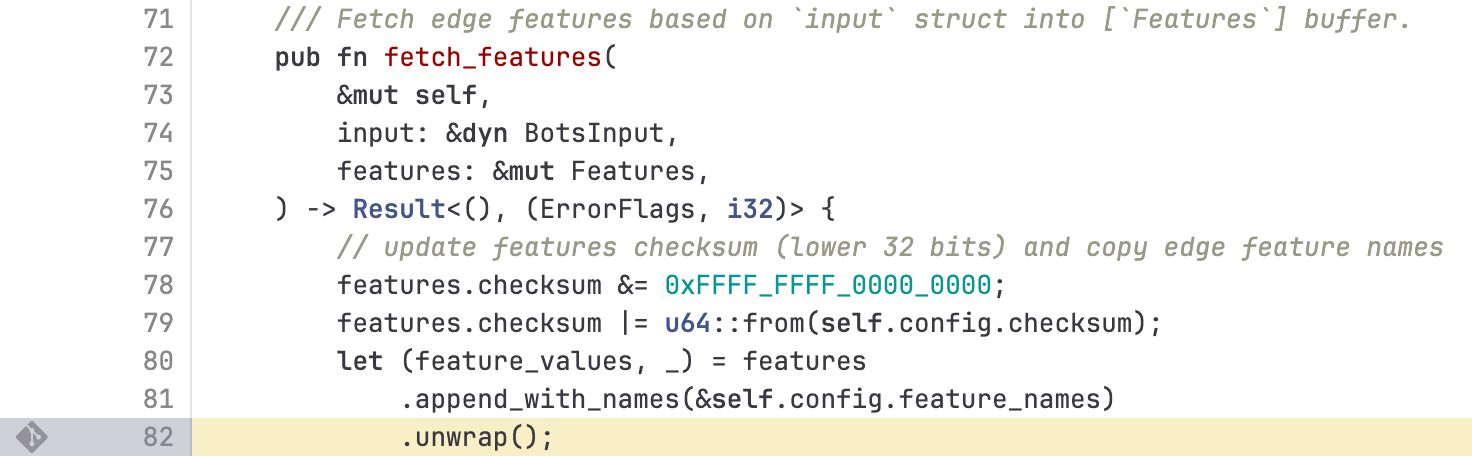
The obvious problem here is that an error condition did not get handled, which is one of the most basic kind of errors. The other basic mistake seems to be that of input validation, as apparently the oversized feature file doesn’t cause an issue until it’s attempted to stuff it into the pre-allocated memory section.
As we have pointed out in the past, the biggest cause of CVEs and similar is input validation and error handling. Just because you’re writing in a shiny new language that never misses an opportunity to crow about how memory safe it is, doesn’t mean that you can skip due diligence on input validation, checking every return value and writing exception handlers for even the most unlikely of situations.
We hope that Cloudflare has rolled everyone back to the clearly bulletproof FL proxy and is having a deep rethink about doing a rewrite of code that clearly wasn’t broken.














That we know of.
Or, to put it another way, assume any given code has bugs until formally proven otherwise.
Hello World, might be safe.
You just assumed it would be run on a world. What about the people on the ISS?
The ISS power supply network is coded in Ada…
… until your write buffer is 1 byte.
What if the world doesn’t exist?
Hello hell is safe
Every code contains bugs. It is not about proving that the old application has no bugs. It is about the new application being an improvement. First prove that the “improved” FL2 proxy has less bugs than the “proven” FL proxy before replacing the old one.
However I agree with you that they must have had a very good reason to replace it. Maybe because it was difficult to maintain, slow or dangerous?
Judging from the companies I worked at, usually a “very good reason” is a new programmer that thinks he knows best, rust is better, why do we even have all this code to handle edge cases, this is too complicated, I can do it better. Remember Apple’s MDNSResponder rewrite and rollback?
Maybe cloudflare is the exception, we have little evidence but what we have is not good…
Well in the case of something like cloudflare that ‘thinks he knows best’ can easily be true despite missing this – I’d assume they are moving to Rust for the new stuff anyway because it is better at preventing human errors, so redoing all the old stuff in Rust for a common language across your codebase is probably not a bad idea.
I can’t imagine theirs is even close to as vast or old as something like the Linux kernel where a real complete rewrite in Rust would be the work of decades, and you’d probably be better off starting from scratch inspired by Linux (perhaps even broadly compatible) to cut out legacy concepts that don’t really work and support for hardware you don’t need etc. For cloudflare I expect it is still a fair bit of work, but if it makes ongoing maintenance of the code easier, reliably issues in your service fewer and means you only need programmers good in one language that would be worth it.
There will always be occasional cloudflare outages, just as every other program has some bugs in it somewhere, be it caused by external attack, a small error or edge case missed in the preproduction testing for some reason, hardware flaw perhaps caused by age etc it will happen. The important part is effectively that it will remain fit for purpose, which in a dynamic operating environment means it can’t ossify at a stable functional state and actually remain stable and functional for long.
There are no ‘programmers only good in one language’.
If they only know one language ‘well’, they are shit (or 14).
14 YO has potential, once he learns a few more languages.
But they are still better then CS types that don’t code:
‘Ewww! Actual code, next you’ll be handing me a soldering iron.’
‘Not until you show me some coding skills!’
@HaHa The more languages you really try to be really GOOD at the more you will end up sliping grammar, logic structures and words incorrectly from one of the others into your code, to who knows what result as the compiler won’t catch everything like that.
I’d expect anybody good enough to get employed professionally as an x programmer to be able to follow along in almost any other language, and somewhat slowly write good code in almost any language! But slowly and/or error prone because programming languages are so often incestuously similar and weird…
Foldi:
You occasionally slip in the morning and write a few lines of the wrong language.
Happens.
Have you ever know a coder ‘only good at one language’ that was actually good at it?
The ‘only knows one language’ coder is an obvious clown.
But the ‘only good at one language’ coder?
I did know a Fortran guy once…
But he was an applied math PhD, coding was peripheral.
I looked, it was a mess (I’ve talked about Fortran calculated Gotos before).
I couldn’t do it from scratch.
Also I saw what he did when asked to make a database structure…
‘My first schema’…
Confident it was easy and that Indexes weren’t needed.
You might and almost certainly are ABLE to be good at many languages if you are good at one. But if you only ever work in one for year after year at that moment you are only really good at the one you use, and just won’t slip into the others you could or previously have been that good at after a while. The knowledge likely isn’t really forgotten, but it is now in the deep archives that you won’t easily recall, and certainly won’t pull up in place of the stuff you actually wanted often.
A rather different situation than trying to stray really really good at them all, and jumping around between updating legacy code in whatever mishmash of languages and ‘best practices/style guide’ they were written with potentially 20+ years ago, and the primary language and style guide all new code is supposed to be written in, where now you are asking these people to stay perfectly fluent in who knows how many languages, jump between them often and somehow never mix ’em up – some folks no doubt can do that, at least well enough, but plenty of great programmers won’t be able to.
No.
Once you’ve got C, you’ve got C.
C++ similar…It’s not C, but one useful new feature every 2 decades is ‘fine’.
Only the libraries change, but you call them from many of the languages.
Who works in the same language for decades?
Academics? Not in my experience…
Applied mathematicians? Some.
You will have a ‘goto language’, that you use for most projects, where you can choose.
Even there, likely using thing like SQL mixed w primary language.
Which if you’re smart is 99% ANSI SQL.
Avoiding non-standard SQL extensions and never touching ‘Shit Query Language’ (‘We didn’t understand, so reinvented wrong’…MyShitQueryLanguage).
‘Right tool for job’ requires proficiency in more than one tool.
As to style guides/design patterns etc.
There is no universal one for most languages.
The ‘latest and greatest/gods own design pattern’ people are usually zealots who should be ignored.
Experienced devs know to adapt to the teams standards as they’ve done it a dozen times already.
Sucks, but no workable alternative.
All just an overcomplicated version of tabs vs spaces.
You occasionally need to revisit code as you ‘newed’ when you should have ‘factoried’.
You adjust the syntactic sugar.
Thank dog most languages aren’t a shifting pile of sand, constantly breaking old code.
That joy is for Python coders.
Just like JS coders have a special version of library hell.
Begin good at some languages is simple, you just need to know to never use them.
There are no good server side JS programmers.
That said, you are only wallowing deep in one stye at a time.
That much is true.
There is no substitute for knowing where the recently buried bodies are.
When the docs are just wrong and the answer is ‘don’t do that’.
That’s 99% library or environment.
Which can span languages.
“First prove that the “improved” FL2 proxy has less bugs than the ‘proven’ FL proxy before replacing the old one.”
Logic problem there. “Less” (should be “fewer” but no matter) implies that you have Count/FL2 and a Count/FL. If you can count them, you found them. If you found them, why not fix them?
I don’t know about you, but I shoot for 100% test coverage, and handle my unwraps and expects properly.
They could have 100% test coverage and still not account for edge cases.
“They could have 100% test coverage and still not account for edge cases.”
Allow me to express a 100% skepticism of that statement, but I may not understand the terminology so I can’t be 100% skeptical.
Basically, just because you have tests for every piece of code doesn’t mean you are testing everything about that code that could be a problem. And you can also have logic errors in the test themselves.
Ah. So it is my misunderstanding of the terminology, specifically “coverage”. It quickly becomes a quis custodiet situation.
“100% test coverage” can mean many things. In typical terms it means every line int he code has been tested (line coverage).
But it doesn’t mean every condition and every code path has been tested, which is called path coverage. So basically if you have a function that first does something if condition A holds and then something if condition B holds, the functions needs to be tested with just one situation (both A and B hold) to get 100% line coverage, but you’d need at least four tests to get 100% path coverage. Of course, if the cases A and B also have more diverging conditions inside them, the number of test cases would be multiplied.
If you have 100% path coverage in your app, having your tests pass would certainly be very good evidence that the code actually works in all cases as the tests specify!
However, getting 100% path coverage is near impossible, except for isolated cases. 100% test coverage, while very rarely happening, is at least much more realistic to achieve.
My company we completely moved out from Cloudflare , read our articles https://orlovskyconsulting.de/index.php/interesting-articles/end-of-cloudflare and here https://ocgforum.javaprofide.de/ocgforum/viewtopic.php?p=1761
Cloudflare caused mess and they are unreliable anymore , who the hell is manager for team which create such global mess?
These major outages have always happened and will always happen, but they do seem to be becoming more problematic as services centralise and become more integrated into everything. AWS, Cloudflare, OVH, CrowdStrike, and more recently have all had far more impact than similar outages last century.
And this risk grows as companies start to build their entire mission critical workflows around BigAI without thinking about “and what do we do when ChatGPT also fails for hours or days?” Let alone “What do we do if the bubble bursts and ChatGPT go out of business”
The thing many beancounters and c-suite forget is business continuity. One must assume that if you use a third party service, any third party service, you need to know what you will do when (not if) it fails, and you need to also ensure that you test these plans.
As for Cloudflare, I am pleased to see they are open and published so much information about the root cause. Too many companies also think they need to hide this stuff, when the opposite is true.
What’s amusing is the whole promise of the cloud was greater resilience – which can be sort-of-true for individual customers and specific sorts of small failure (EG a server going down, a link breaking) – but at scale we seem to be seeing more huge global outages affecting huge swathes of businesses and services because when a proper f*ck up happens, all the eggs are now in one of three or four massive baskets.
I’d be curious to know the reliability/cost stats for the average customer for the money spent Vs a sensibly specced on-prem solution – I’ll wager it doesn’t shake out as brilliantly as the marketing department would have us believe.
When people mention “the cloud” I will sometimes peevishly say “oh, you mean the server?”. Because, yeah, what we have now is not what that buzzword was created to sell. At best, it means there’s redundancy in your centralised service provider. But it can just mean “our single server is an EC2 instance”.
You could imagine a cool sci-fi ecosystem of diverse codebases sharing workloads and being all organically resilient, but the reality under the hood is still nerds on call at 4am. The marketing is just a way for executives to take credit for their work.
I can tell you about the resiliency, having managed systems for big and small companies, on prem and on cloud. When you work on prem you usually have at least 2 datacenters, managed by different companies ideally. You HAVE to plan in advance so you do, and once you have a second dc you start doing switchovers from one to the other, if nothing else for maintenance. In the cloud you could theoretically always switch to a different region, but to do that you need properly configured and generalised automation, and you need to test that and no manager I have ever had is interested in paying that cost, no matter if the company had 10M users or 10. Most of the time they don’t even have a backup in a different region…
‘Cloud’ didn’t generally replace on premises servers.
It replaced rented space in datacenter w remote access.
The point of ‘cloud’ wasn’t that your new virtual servers were going to be cheaper then your previous racks of servers (they aren’t, opposite is true).
It was that the cloud provider was going to handle all the dirty, day to day server admin, regular hardware upgrades, new servers, fail over etc etc.
Billing in much smaller increments…(but rate).
The customer could fire their local ‘digital janitors’ and net save money.
Cloud providers ‘digital janitors’ were also said to be ‘better’.
Also working on a much bigger target.
Anybody ever met a manager that knew who his/her best IT staff was?
Why would I believe that management at Cloudflare was any more cluefull?
Based on their size, I’d guess ‘certified idiots’ abound, directed by people with pointy hair.
They aren’t that old, the Peter principle says they still have some people not operating at their ‘level of incompetence’, that is changing quickly.
Problem:
Unless the cloud provider is in the meetings, they won’t know when the customer’s IT needs change.
The customer just fired the person that could have told them, because the numbers never worked if they hadn’t.
Question of scale there – if you really need the uptime and backup redundancy that the cloud tends to come with, but are a rather small operator that only really needs one maybe two servers etc then the hardware costs of having 2 or 3 copies of your hardware, with the UPS and generator and that whole other building on a different power grid etc… Not to mention that you could end up employing somebody all the time to do it in house with almost no work for them to actually do.
That was why you had those in a couple of rented racks in different datacenters.
It was generally cheaper than cloud, but clearly marked what remained ‘your problem’.
Firing the dude with ‘almost no work’ was the selling point of cloud.
How they made the beans count.
Problem was the rather small operator is that dude was the only one tech enough to manage details of the cloud for them.
How production databases don’t get backed up.
“and what do we do when ChatGPT also fails for hours or days?”
That one’s easy. Get some goddam work done.
Rule #1 of writing any code that’s interacting with other systems (or people) is that it has to accept any junk thrown at it at any rate that the interface can deliver it (ideally, somewhat higher — I’m used to network testing and since ‘line rate’ implies well formed and timed packets you need to test interfaces with badly formed and ill-timed traffic — anything, in fact). If the interface generates error messages on that interface then they’re not allowed to add to the mayhem (i.e. don’t signal overload conditions by generating network traffic).
Although this rule was promulgated for network interfaces (not by me) it applies to any interface. In this case the code should have been tested with not just legal files but also badly formed files, even some that were pure junk. Unfortunately because the module reading the file was written in an idiot proof language the programmers just assumed that it was proof against idiots.
People write code that doesn’t even test for commonly existing names, eg those with apostrophes. Like those persons of Irish extraction with O'[anything] as their last name. Compounded by a certain large vendor of software who decided in their version of SQL to delimit text/strings with apostrophes instead of quotation marks. What did they think people were using their database for? Did they even try it with real data, like names?
It was understandable when crap was on a mainframe with very limited resources. After 30 years, it’s gotten a little old. Kudos to the poor sap at Pizza Hut some years ago who put in at least half a dozen backslashes to escape the apostrophe in my name, so I could order a pizza online and not have to call.
If your front end is having trouble with apostrophes in the database, you have a SQL injection vulnerability. Proper use of parameters in your SQL client makes this a non-issue.
It’s Little Bobby Tables all over again. What little I know about Rust I’ve only read here but the impression I get is that Rust evangelists are viewed by some as the vegans of CS.
Your just making that up.
All SQL vendors use single or double quotes to delimit text.
Because people will build SQL in strings and submit, they really should use a parameterized query or stored proc, but real world slobs.
Problem is the Mics use a single quote as an apostrophe.
Surely their is a unicode apostrophe, not on a keyboard but.
One of the things that’s most annoying actually is trying to determine if there’s a condition in which panic() could be called in embedded rust code. If it is possible then that’s another error condition you need to handle, but it’s not very intuitive to find out. The guide I saw a while back resorted to looking for the panic symbol in the resulting binary to see if it could be called.
In the video they say that the “.unwrap()” method should be called “.unwrap_or_panic()” to be consistent with the rest of the unwrap family of methods, and to be more clear.
The error was not “cleanly detected and handled” in FL, it failed silently.
Blaming Rust the language as a whole for the Cloudflare outage is like blaming Michelin when you crash your car for driving too fast in the rain.
You are absolutely right that they should have been verifying inputs, handling errors correctly, and probably testing extreme cases like this in such a critical code path. This was a rookie mistake on Cloudflare’s part, and they should know better, but this kind of error can and does happen in every language and paradigm, so blaming it on Rust the language is a bit of a reach, and feels more like flame-bait and “see-i-was-right” journalism, given Maya’s vocal history of distaste for Rust.
Rust evangelists are annoying, but Rust anti-vangelists are the flip side of the same coin. It has pros and cons, as all languages and tools do. Everyone decides what features are important based on the ones their favorite tool does best, and by George are they gonna tell you about it. This is true of programming languages, OSes, car brands, political parties, religions, and even grocery stores. Confirmation bias is virtually unavoidable.
“There are only two kinds of languages: the ones people complain about and the ones nobody uses.”
This quote hits the nail on the head. There is no such thing as stable popular language. Things like Rust that change what they are every 3 months with breaking changes and feature additions are a great choice for corporations which only ship binaries and never expect users to have to compile their software. But it’s a horrible choice for open source where users compiling things is normal and expected. rustc and rust simply aren’t compatible with 4 year cycle distros. Having to curl | sh a language toolchain instead of being able to self host out of repos is a really bad idea.
What kind of breaking changes does Rust introduce every 3 months?
From experience Rust projects are much more stable than python – which is a headache and also tightly coupled with Ubuntu.
I don’t think that hukrepus compares Rust to Python, but to C. Python is in the same ballpark as rust with respect to changes.
When i tried rust, which is now i think about 7 years ago, people were saying to me “there are not breaking changes every 3 months, that’s something that used to happen but it doesn’t happen today.” Suffice it to say, the first project i tried to build ran into a bunch of recent breaking changes. So now i feel like you’re saying Rust doesn’t have breaking changes anymore…maybe it’s true but from my perspective someone already cried wolf and my ears are now jaded.
Or in other words, yeah, Python has breaking changes all the time too. Anecdotally, Python’s are less frequent than Rust’s but more obnoxious because Python is so much more widely-used and every use needs to be paired with the correct version of the interpretter. Whereas my problems with Rust completely went away when i stopped trying to use it to build anything :)
First of all, you don’t know how the FL proxy handled the error. It’s quite likely that the size discrepancy was detected and an error logged. Either way it didn’t bring down operations for an optional feature, which is rather nice.
Second, I’m not blaming Rust here, as the same kind of sloppy coding would have brought down code in any other language. What I am saying here is that there’s nothing in Rust that will prevent people from writing said sloppy code that will happily explode.
What I am also questioning as a corollary is the apparent need to rewrite the FL proxy codebase in a completely different language, as this clearly backfired in a spectacular fashion.
There is something in Rust that will prevent people from calling unwrap without thinking a little more https://rust-lang.github.io/rust-clippy/master/index.html#unwrap_used
From the official Cloudflare debrief:
“Customers on our old proxy engine, known as FL, did not see errors, but bot scores were not generated correctly, resulting in all traffic receiving a bot score of zero. Customers that had rules deployed to block bots would have seen large numbers of false positives.”
So no, the C implementation did not detect it, it did not have a nice error to log. It kept churning through, spitting out bad scores, with no indication of a problem.
Yes, the Rust version caused a very public issue. But to say the rewrite in a new language “backfired” is a bit narrow-sighted. The reason you’re claiming the old codebase is better is because the problems it caused happened in the past and have subsequently been fixed, and the problems from the new codebase are happening right now. Given the same time, the new codebase /will/ be just as robust as the old one, but will have the added benefit of using an updated architecture (see below), and a more modern language. The issue arose not because they used Rust, but because they are doing a rewrite. Had they done the rewrite of FL2 still in C, or chosen C++, or Go, or Malbolge, they would without a doubt have had similar problems, because it’s an untested codebase, and as one of the most central companies to the internet any problem is a big problem.
Coming from an embedded engineering background, I love C as a language. It has an extremely important place in the history of software, and impressively remains important in the modern development landscape, but that doesn’t make it the right choice for a lot of situations. In Cloudflare’s case, they are dealing with the ever changing landscape that is the internet, and the requirements have changed from when FL was written (15 years ago)[https://blog.cloudflare.com/20-percent-internet-upgrade/]. They took the valuable lessons they learned from FL and the shortcomings it had, and iterated on it. In the process, they are trying out a new tool they feel could give them a better return on the investment. It may be a gamble, but it’s not an unwarranted one.
New languages are the same thing. C did (and does!) it’s job great, but there are undeniable pain points and friction to using it at scale, and new languages were created to alleviate those pain points. After some time, other pain points arose in the new languages, and more languages were created to attempt to make things better. And so on, and so on. We learn from the previous problems, and try something new to make things better/easier/more reliable. Sometimes it works better than others, but it doesn’t make the attempt in vain. Even in failure, we learn lessons that can help us on the next attempt. The only true failure is stagnation.
“I know of no better life purpose than to perish in attempting the great and the impossible.” — Friedrich Nietzsche
Using unwrap in production code is usually a mistake. Clippy should have issued a warning about this code and it should have been fixed before going into production.
Erlang – log errors but keep on trucking
Rust – act like every error is reason enough to implode
Someone should have sent this coming
This particular issue threw error during memory allocation. How do you “keep on trucking” after that?
I even fail to see how you can error handle that.
Presumably the process had more memory available in total than the buffer/pool it set aside for this file. My understanding is that’s what ran out and not all memory in the system.
Always let a program in testing phase crash on unhandled exceptions.
Never ever let a production program crash on exceptions where possible.
It could ignore the file, containing bot traffic settings, resulting in websites working mostly just fine. Logging the error will lead the user or system operator to the source.
You can always give a certain number of tries before crashing.
For this memory allocation for exemple, try, say, 5 times with a small wait between each, and if it fails the last time, well, at least you tried all you could.
You are mistaken about Erlang. The motto there was “Let it crash”. OTP was fully based on the pattern of crash and restart (as opposed to graceful error handling and recovery).
In the spirit of Erlang I’m going to ignore my mistake and continue misquoting them. But I’ve logged the error here.
Like most Erlang/Elixir OTP languages, both your pools of micro-threads can pin the cores… However, unlike other options the users will still see fair resource sharing, and not notice the mistakes.
This is also why the OTP may monitor and debug itself. And new code may be AB tested prior to full upgrade of a live borked system. =)
But how? Rust is so secure, so safe, so magic, and it’s farts smell of roses.
Rust is how big tech takes control of open source. Disenfranchise the real engineers and replace with company lackies. When Google and MS have total control of Linux and start filling it with tracking and data harvesting code but it’s all in Rust so on one knows what the hell it’s doing, don’t come crying to me. I told you so.
This was a configuration error plus a bug in parsing logic. Nothing to do with the language, they wrote the unwrap there themselves. Call something like parse_or_die() from C and see what happens.
I am a real open source developer and engineer and I do understand Rust. And honestly I have more trouble reading “traditional” C text replacement macros and C++ STL meta magic than Rust.
How? By the developers doing things the wrong way, as is usually the problem with language issues being comparatively rare.
Your moronic rant makes it clear you don’t have the mental ability to understand the issue nor, it seems, reality.
Don’t worry, this kind of thing won’t happen with Vibe coding!
Take a network purposely designed to survive a nuclear war because of its ability to auto-reroute data and then make it dependent on what are effectively choke points due to a reliance on single services. Priceless.
Cloudflare broke the Internet
Yet I didn’t notice an interruption
Neither with aws
Unit testing, Integration testing? …. Still too much production code left with holes because of missing testing.
What struck me when i read the timeline summary on slashdot is it seems like it took 3 hours from the problem manifesting to them figuring out what caused it, but the bandaid fix was fairly obvious once they did. That’s where i’d be focusing my energy if i was on the inside…ideally they want to discover before deployment, but failing that they need to at least make sure the error message is propagated intelligibly to the firefighters.
The thing i’m always thinking when i try to put myself in their shoes is how important it is to be simple. To use a handy analogy, actually the biggest problem i had with Rust when i tried it was Cargo. As an over-designed dependency system, when it works, it works so well that it is easy to add another dependency. But as a result, even very trivial tasks are managed by outside dependencies and even the fundamental crates that underly everything else have complicated dependencies. So if Cargo isn’t working and you need to bootstrap, it is a nightmare. If tasks are well-isolated from eachother, then it’s easier to think about the relationships between different components (which is the task that caused diagnosis to take 3 hours), and easier to change those relationships in a hurry.
And while i’m trash-talking Rust, there’s another lesson in my Cargo disaster. I was told (this was several years ago, maybe it’s true now) that no one has to bootstrap Cargo because Rust was already supported on every major platform. That was a bold lie — targets as “obscure” as 32-bit armhf Linux were broken and no one had noticed. And i was also told that boot-strapping Cargo is easy, because here’s a script to do it. And that was a bold lie too — the script was already 3 months out of date (i.e., of course pre-historic by Rust standards) and didn’t work at all because it was woefully out of step with the recent developments of core crates.
I’m not just mocking Rust (but i’ll do that anyways), i’m pointing out the cost of complexity. If things are genuinely simple then it’s possible to manage their change. But because the overall Rust dependency situation is so complicated, as little things changed the whole thing fell down and required massive reinvention to keep up. The changes that caused trouble were simple but the overall system was so complicated that fixing the consequences was not simple.
Which language would you rather use by the following example, just to get standard input.
io::stdin().read_line(&mut input).expect(“Failed to read line”);
or
fgets()
Really, that sums up Rust to me. A language should be simpler to use … not harder. I ‘try’ to like Rust but….
i don’t know, i don’t have opinions on that level i guess. whether it is called “stdin” or “io::stdin()” doesn’t matter to me. Whether it’s filehandle.read_line() or fgets(…, file_handle) doesn’t matter to me either. And whether it’s “if (!fgets…) error(foo)” or “read_line(…).except(foo)” doesn’t really make a huge difference to me either. Like, at some level i have to confess Java is fantastically over-verbose compared to almost every other language on the planet…but i think of those differences as mostly skin-deep.
And that’s the irony of my discomfort with rust. I hate that it’s such a moving target that the only time i’ve used it all i did was debug moved-targets. I hate that Cargo was broken when i used it, and even at its best it makes me think of gradle (my least favorite build tool of all time). I hate that even though i’ve only read probably less than 1000 lines of rust code in my life, i’ve debugged 200 lines of cut and pasted boilerplate code that did nothing but repeat for different types because either rust’s generic programming idioms suck or because the guy who got there before me didn’t know how to use them.
But looking at the bigger picture, i don’t think i have any real objections to the language itself. Like, i have a suspicion if i got to know the object model i would learn to hate it as much as i hate C++. But maybe i’d like it…i mean, i like Java. But as far as its novel approach to scoping and mutability and memory management, really the only thing is its unfamiliarity. I might be able to like it by the next time it crosses my path.
“io::stdin().read_line(&mut input).expect(“Failed to read line”);
or
fgets()”
Programming languages should be simple and modular in design. If 3 commands are packed into a single command that’s great if it works, but when it fails, can be a real problem. From general experience, I personally find simple commands better, and able to choose when and how to group them together vital in software functionality.
In truth, neither method is right or wrong, so long as things work as expected.
The irony in this is that when I checked DownDetector to see if others have problems with CloudFlare, the site was broken. DownDetector was down because it uses CloudFlare, which was down…
The title of this article is low key wrong. “How One Uncaught Rust Exception Took Out Cloudflare” is incorrect. The exception wasnt uncaught.
They didnt “forget to catch an error.” That’s how it works in exception-based languages where you have to write a try/catch. Rust isnt like that. It’s the opposite. They were presented with an error unable to ignore it, and chose to say “crash the system when we hit an exception.” That’s what
.unwrap()is.They’re just dumb.
“Hey! Rust safety stuff looks cool! Let’s rewrite our core in Rust!”
Proceeds to explicitly ignore the safety features of Rust
Like, this isnt even some “Aha! Rust isnt as safe as it claims! It has footguns too!” – they EXPLICITLY ADDED CODE to ignore an issue. They didnt forget a try/catch they said “let’s ignore this so it crashes the system.” A deliberate choice. A stupid one. That’s not Rust being hard to understand. That’s not a language being difficult to wrote well. It is complete and utter incompetence.
The only thing Rust could do better here is maybe disable
.unwrap()for release builds or something, but that presents all sorts of other issues.A program that so much depends on should not fail by just exiting IMHO.
I’m finding that too many system designers and programmer’s are failing to consider how the software they are designing and implementing should work and interact with other software and users.
The language of choice is only a small part of the problem.
Software Architecture by Pearson, bundle.
https://www.humblebundle.com/books/software-architecture-pearson-books
+1
These were exactly my thoughts as well when I read this article!
The wonders of a monopoly failing to fail safely. Or any sufficiently large system that suddenly became The Only Plan A.
Internet didn’t “fail”, what failed was one particular side of it that somehow/gradually emerged to be the only one relied on by way too many.
Time to call up Vint Serf and ask him for a better version that won’t be able to self-assemble into The Next Standard Oil when left to its own devices. I am quite sure he already had some kind of solution to that, but was waved off as an old senile scarety cat.
Sounds like their ability to test their code before release is “too difficult” to do right, else such a simple error as not being able to handle dynamic input into a fixed memory slot would surely have been detected beforehand. In fact, such a strict requirement should have been coded for – no need to throw a fatal error, just work round it and report a shortcoming, or ignore it, and work on. Anything less is asking for trouble. And I’d be worried if they can’t handle such simple input, what else has been overlooked, that may not yet be discovered?
As someone who has been writing, debugging and maintaining all sorts of code for the last 40 years in a dozen or so different languages in many areas, I can summarize my thoughts on the subject in a single phrase:
“The language that will impede any sufficiently ignorant (or self-confident, or lazy, or …) programmer of making serious mistakes hasn’t been invented yet — and never will be.”
Anyone else claiming the opposite is either deluded or a scammer.
Code certified?
can c++small code modules be certified if
they can be disassembled into a platform
machine code?
AI Overview
Yes, C++ code modules can be certified
if they are compiled into machine code.
The ability to disassemble the machine code
back into assembly language is a standard
practice for verification and debugging, not
a barrier to certification. Certification would
depend on the specific requirements of the
certification body, which would assess the
security, reliability, and safety of the
code’s function regardless of how it was
generated.
Compilation and verification
…
mportant considerations
Decompilation: Disassembly is not the
same as decompilation. Decompilation
aims to reconstruct the original source
code, which is an extremely difficult and
often impossible task due to the loss of
high-level information during compilation.
Verification process: Certification would
involve rigorous testing and analysis of
the compiled module. The fact that it was
originally C++ and can be disassembled
is simply a part of its lifecycle that can
be inspected. GCC Developer Discovers “Our Codebase
Isn’t Fully C++20 Ready”.