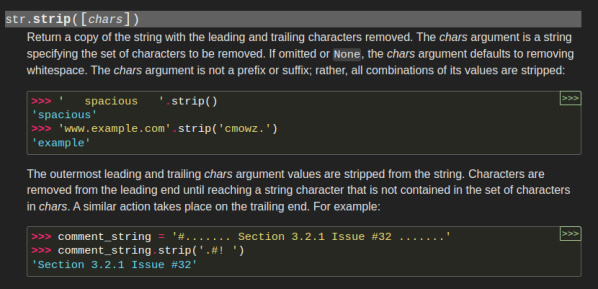
At first, string processing might seem very hard to optimize. If you’re looking for a newline in some text, you have to check every character in the string against every type of newline, right? Apparently not, as [Abhinav Upadhyay] tells us how CPython does some tricks in string processing.
The trick in question is based on bloom filters, used here to quickly tell whether a character possibly matches any in a predefined set. A bloom filter works by condensing a set of more complex data to a couple of bits in an array. When an element is added, a bit is set, the index of which is determined by a hash function. To test whether an element might be in the filter, the same is done but by testing the bit instead of setting it. This effectively allows a fast check of whether an element might be in the filter.
CPython doesn’t stop optimizing there: instead of a complicated hash function, it simply uses the lowest 6 bits. It also has a relatively small bit array at only 64 bits which allows it to avoid memory all together, which in turn makes the comparisons much faster. [Abhinav] goes far into more detail in his article, definitely worth a read for any computer scientists among us.
Nowadays there is ever increasing amounts of talk about AI (specifically large language models), so why not apply an LLM to Python to fix the bugs for you?








