The ongoing AI apocalypse is hitting prices for high-end components from RAM to GPUs to storage hard, which is bad enough when you have a job to try and budget for those now-pricier items — but what if you don’t? Once upon a time, it might have been good advice to tell a jobless friend to “learn to code,” but is that still true in the era of AI? [Brian Jenney], writing for IEEE Spectrum, says the death of the CS degree has been vastly exaggerated, but your take might differ. Let’s look at the numbers.
Unemployment is higher amongst new Computer Science grads than ever: in the US, it’s at 6.1%, while 7.5% of Computer Engineering graduates are on the dole. That’s a record high, and while various EU countries have their own numbers, they all have one thing in common: they’ve all shot up like a rocket in the past few years. In the USA, Philosophy grads report only 3% unemployment. Let that sink in: the folks you used to bully as being the most useless on campus are twice as likely to get a job as you would be if you were in school today.
Modern computers use dynamic RAM, a technology that allows very compact bits in return for having to refresh for about 400 nanoseconds every 3-4 microseconds. But what if you couldn’t afford even such a tiny holdup? [LaurieWired] goes into excruciating detail about how to avoid this delay.
But first, why do we care? It once again comes down to high-frequency trading; a couple nanoseconds of latency can be the difference between winning or losing a buy order. You likely miss all the caches and need to fetch data from the remote land of main memory. And if you get unlucky, you’ll be waiting on that price for a precious 400+ nanoseconds! [Laurie] explains all the problems faced in trying to avoid this penalty; you try to get a copy of the data on two independent refresh timers. That’s easier said than done; not only does the operating system hide the physical addresses from you, but the memory controllers themselves also scramble the addresses to the underlying RAM!
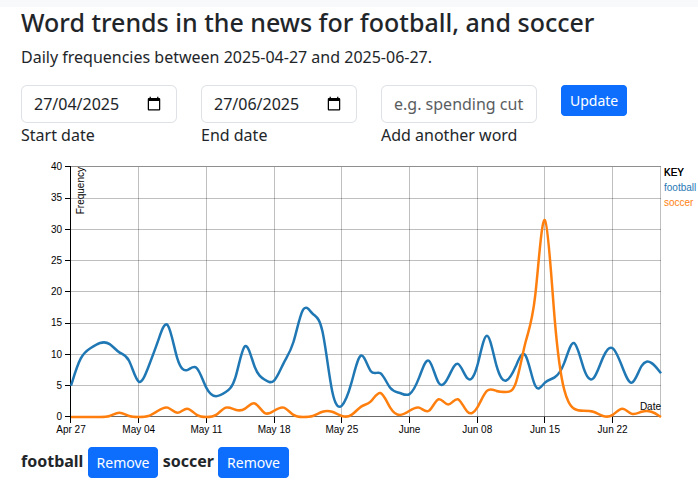
Do you ever look at the news, and wonder about the process behind the news cycle? I did, and for the last couple of decades it’s been the subject of one of my projects. The Raspberry Pi on my shelf runs my word trend analysis tool for news content, and since my journey from curious geek to having my own large corpus analysis system has taken twenty years it’s worth a second look.
How Career Turmoil Led To A Two Decade Project
This is very much a minority spelling. Colin Smith, CC BY-SA 2.0.
In the middle of the 2000s I had come out of the dotcom crash mostly intact, and was working for a small web shop. When they went bust I was casting around as one does, and spent a while as a Google quality rater while I looked for a new permie job. These teams are employed by the search giant through temporary employment agencies, and in loose terms their job is to be the trained monkeys against whom the algorithm is tested. The algorithm chose X, and if the humans also chose X, the algorithm is probably getting it right. Being a quality rater is not in any way a high-profile job, but with the big shiny G on my CV I soon found myself in demand from web companies seeking some white-hat search engine marketing expertise. What I learned mirrored my lesson from a decade earlier in the CD-ROM business, that on the web as in any other electronic publishing medium, good content well presented has priority over any black-hat tricks.
But what makes good content? Forget an obsession with stuffing bogus keywords in the text, and instead talk about the right things, and do it authoritatively. What are the right things in this context? If you are covering a subject, you need to do so using the right language; that which the majority uses rather than language only you use. I can think of a bunch of examples which I probably shouldn’t talk about, but an example close to home for me comes in cider. In the UK, cider is a fermented alcoholic drink made from apples, and as a craft cidermaker of many years standing I have a good grasp of its vocabulary. The accepted spelling is “Cider”, but there’s an alternate spelling of “Cyder” used by some commercial producers of the drink. It doesn’t take long to realise that online, hardly anyone uses cyder with a Y, and thus pages concentrating on that word will do less well than those talking about cider.
We Brits rarely use the word “soccer” unless there’s a story about the Club World Cup in America.
I started to build software to analyse language around a given topic, with the aim of discerning the metaphorical cider from the cyder. It was a great surprise a few years later to discover that I had invented for myself the already-existing field of computational linguistics, something that would have saved me a lot of time had I known about it when I began. I was taking a corpus of text and computing the frequencies and collocates (words that appear alongside each other) of the words within it, and from that I could quickly see which wording mattered around a subject, and which didn’t. This led seamlessly to an interest in what the same process would look like for news data with a time axis added, so I created a version which harvested its corpus from RSS feeds. Thus began my decades-long project.
In the realm of computer science, it’s hard to go too far without encountering hashing or hash functions. The concept appears throughout security, from encryption to password storage to crypto, and more generally whenever large or complex data must be efficiently mapped to a smaller, fixed-size set. Hashing makes the process of looking for data much faster for a computer than performing a search and can be incredibly powerful when mastered. [Malte] did some investigation into hash functions and seems to have found a method called Fibonacci hashing that not only seems to have been largely forgotten but which speeds up this lookup process even further.
In a typical hashing operation, the data is transformed in some way, with part of this new value used to store it in a specific location. That second step is often done with an integer modulo function. But the problem with any hashing operation is that two different pieces of data end up with the same value after the modulo operation is performed, resulting in these two different pieces of data being placed at the same point. The Fibonacci hash, on the other hand, uses the golden ratio rather than the modulo function to map the final location of the data, resulting in many fewer instances of collisions like these while also being much faster. It also appears to do a better job of using the smaller fixed-size set more evenly as a consequence of being based around Fibonacci numbers, just as long as the input data doesn’t have a large number of Fibonacci numbers themselves.
Going through the math that [Malte] goes over in his paper shows that, at least as far as performing the mapping part of a hash function, the Fibonacci hash performs much better than integer modulo. Some of the comments mention that it’s a specific type of a more general method called multiplicative hashing. For those using hash functions in their code it might be worth taking a look at either way, and [Malte] admits to not knowing everything about this branch of computer science as well but still goes into an incredible amount of depth about this specific method. If you’re more of a newcomer to this topic, take a look at this person who put an enormous bounty on a bitcoin wallet which shows why reverse-hashing is so hard.
At first, string processing might seem very hard to optimize. If you’re looking for a newline in some text, you have to check every character in the string against every type of newline, right? Apparently not, as [Abhinav Upadhyay] tells us how CPython does some tricks in string processing.
The trick in question is based on bloom filters, used here to quickly tell whether a character possibly matches any in a predefined set. A bloom filter works by condensing a set of more complex data to a couple of bits in an array. When an element is added, a bit is set, the index of which is determined by a hash function. To test whether an element might be in the filter, the same is done but by testing the bit instead of setting it. This effectively allows a fast check of whether an element might be in the filter.
CPython doesn’t stop optimizing there: instead of a complicated hash function, it simply uses the lowest 6 bits. It also has a relatively small bit array at only 64 bits which allows it to avoid memory all together, which in turn makes the comparisons much faster. [Abhinav] goes far into more detail in his article, definitely worth a read for any computer scientists among us.
The human mind is a path-planning wizard. Think back to pre-lockdown days when we all ran multiple errands back to back across town. There was always a mental dance in the back of your head to make sense of how you planned the day. It might go something like “first to the bank, then to drop off the dry-cleaning. Since the post office is on the way to the grocery store, I’ll pop by and send that box that’s been sitting in the trunk for a week.”
This sort of mental gymnastics doesn’t come naturally to machines — it’s actually a famous problem in computer science known as the traveling salesman problem. While it is classified in the industry as an NP-hard problem in combinatorial optimization, a more succinct and understandable definition would be: given a list of destinations, what’s the best round-trip route that visits every location?
There are two reasons to go to school: learn about something and to get a coveted piece of paper that helps you get jobs, or at least, job interviews. With so many schools putting material online, you can do the first part without spending much money as long as you don’t expect the school to help you or grant you that piece of paper. Stanford has a huge computer science department and [Rui Ma] cataloged over 150 computer science classes available online in some form from the University. Just the thing to while away time during the quarantine.
Apparently, [Rui] grabbed the 2020 course catalog to find on-campus classes and found the companion website for each class, organizing them for our benefit. The list doesn’t include the actual online class offerings, which you can find directly from Stanford, although there is another list for that.