By some estimates, the English language contains over a million unique words. This is perhaps overly generous, but even conservative estimates generally put the number at over a hundred thousand. Regardless of where the exact number falls between those two extremes, it’s certainly many more words than could fit in the 64 kB of memory allocated to the spell checking program on some of the first Unix machines. This article by [Abhinav Upadhyay] takes a deep dive on how the early Unix engineers accomplished the feat despite the extreme limitations of the computers they were working with.
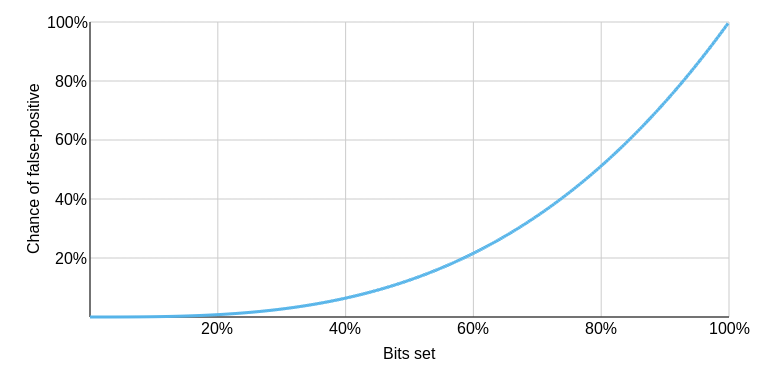
Perhaps the most obvious way to build a spell checker is by simply looking up each word in a dictionary. With modern hardware this wouldn’t be too hard, but disks in the ’70s were extremely slow and expensive. To move the dictionary into memory it was first whittled down to around 25,000 words by various methods, including using an algorithm to remove all affixes, and then using a Bloom filter to perform the lookups. The team found that this wasn’t a big enough dictionary size, and had to change strategies to expand the number of words the spell checker could check. Hash compression was used at first, followed by hash differences and then a special compression method which achieved an almost theoretically perfect compression.
Although most computers that run spell checkers today have much more memory as well as disks which are orders of magnitude larger and faster, a lot of the innovation made by this early Unix team is still relevant for showing how various compression algorithms can be used on data in general. Large language models, for one example, are proving to be the new frontier for text-based data compression.